4分钟训练ImageNet!腾讯机智创造AI训练世界纪录

4分钟训练ImageNet!
腾讯机智创造AI训练世界纪录
by 腾讯机智团队
注:腾讯机智机器学习平台由TEG架构平台部和运营管理部团队携手,并和香港浸会大学计算机科学系褚晓文教授团队深度合作联袂打造。
为了让大家可以更好的理解「如何4分钟训练ImageNet」,腾讯技术工程公众号特别邀请腾讯机智团队的工程师通过语音录播分享的方式在「腾讯技术课」里同步录制了语音+PPT解说版,点击即可收听:
背景
2018年6月25日,OpenAI在其Dota2 5v5中取得一定成绩后介绍,其在训练中batch size取100W,而1v1的训练batch size更是达到800W;训练时间则是以周计。腾讯内部对游戏AI一直非常重视,也面临大batch size收敛精度和低训练速度慢的问题;目前batch size超过10K则收敛不到基准精度,训练时间以天计,这对于快速迭代模型来说是远远不够的。
目前业界考验大batch size收敛能力和大数据集上训练速度的一个权威基准是如何在ImageNet数据集上,用更大的batch size,在更短的时间内将ResNet-50/AlexNet这两个典型的网络模型训练到标准精度;国外多个团队作了尝试并取得了进展,比如UC Berkely等高校的团队可在20分钟将ResNet-50训练到基准精度。
研究和解决这个问题,可以积累丰富的大batch size收敛优化经验和大集群高性能训练经验,并将这些经验应用到解决游戏AI类实际业务中;这也是我们研究这个问题的初衷。
一 4分钟内训练ImageNet
腾讯机智 机器学习平台团队,在ImageNet数据集上,4分钟训练好AlexNet,6.6分钟训练好ResNet-50,创造了AI训练世界新纪录。
在这之前,业界最好的水平来自:
① 日本Perferred Network公司Chainer团队,其15分钟训练好ResNet-50;
② UC Berkely等高校的团队,11分钟训练好AlexNet.

图示 国内外各团队训练ImageNet速度
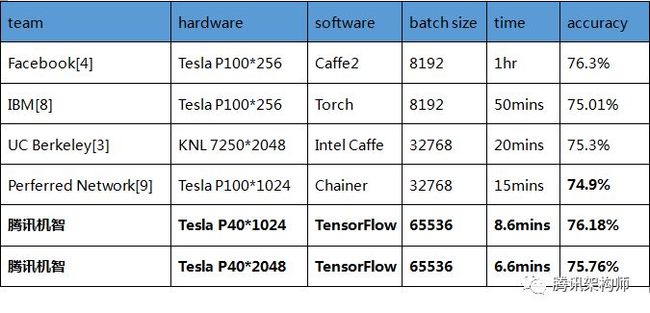 图示 各平台ResNet-50训练软硬件参数配置及性能
图示 各平台ResNet-50训练软硬件参数配置及性能
注:batch size为256时基准准确度为75.3%。

图示 各平台AlexNet训练软硬件参数配置及性能
注:“--”表示相关团队没有对应的测试数据
二 机器学习领域训练背景
在AlexNet网络模型出现后的过去几年中,深度学习有了长足的发展和进步,尤其是在图像、语音、机器翻译、自然语言处理等领域带来了跨越式提升。在AlphaGo使用深度学习方法战胜世界围棋冠军李世石之后,大家对人工智能未来的期望被再一次点燃,人工智能成为各个领域议论的焦点。但与之相伴的也有很多问题:
• 数据量大:
有些模型的训练数据动辄上TB,使得多轮训练时数据读取成为非常耗时的部分。
• 计算模型复杂:
深度网络的一个特点就是结构越深、越复杂,所表达的特征就越丰富,在此思想下,最新的网络结构越来越复杂,从AlexNet的8层,VGG-19的19层,ResNet-50的50层,到Inception-ResNet-V2的467层和ResNet-1000的1202层等。
• 参数量大:
深度神经网络由于层次很多,参数量往往很大。ResNet-50有2500万参数量,AlexNet有6200万的参数量,而VGG-16参数量则达到1.38亿,有的语言模型参数量甚至超过10个亿[5]。
• 超参数范围广泛:
随着模型复杂度的提升,模型中可供调节的超参数数量及数值范围也在增多。例如,在CIFAR-10数据集上训练的ResNet模型有16个可调的超参数[8],当多数超参数的取值为连续域的情况下,如此少量的超参数仍然可能造成组合爆炸。因此,最近也出现了以谷歌的Vizier为代表的系统,采用优化的搜索及学习算法为模型自动适配合适的超参数值的集合。
所有上面这些问题,对训练速度带来巨大的挑战和要求。
从2010年以来,每年的ImageNet大规模视觉识别挑战赛(ILSVRC [1],下文简称ImageNet挑战赛)作为最权威的检验图像识别算法性能的基准,都是机器学习领域的焦点。
随着全世界研究者的不断努力,ImageNet的Top-5错误率从2010年的28%左右,下降到2012年的15.4%(AlexNet),最终在2017年Top-5错误率已经下降到3%左右,远优于人类5%的水平[2]。
在这个迭代过程其中,两个典型的网络,AlexNet和ResNet-50具有里程碑的意义。然而,在一个英伟达的 M40 GPU 上用 ResNet-50 训练 ImageNet 需要 14 天;如果用一个串行程序在单核 CPU 上训练可能需要几十年才能完成[3]。因此,如何在更短的时间内在ImageNet上训练好AlexNet和ResNet-50一直是科研工作者研究的课题。
很多研究团队都进行了深入尝试,比如Facebook人工智能实验室与应用机器学习团队可在1小时训练好ImageNet [4];目前业界最好的水平来自:
① 日本Perferred Network公司Chainer团队,其15分钟训练好ResNet-50; [9]
② UC Berkely等高校的团队,11分钟训练好AlexNet. [3]
机智团队想在这个问题上做出新贡献,推动AI行业向前发展,助力AI业务取得成功。
三 训练速度提升的挑战
如第二节所述,由于以上四个主要矛盾,深度学习训练时间常常以小时和天计算,如何提升训练效率,加快模型训练迭代效率,成了机智团队的关注重点。要提升训练速度,主要面临挑战有如下几个方面:
3.1 大batch size带来精度损失
为了充分利用大规模集群算力以达到提升训练速度的目的,人们不断的提升batch size大小,这是因为更大的batch size允许我们在扩展GPU数量的同时不降低每个GPU的计算负载。
然而,过度增大batch size会带来明显的精度损失!这是因为在大batch size(相对于训练样本数)情况下,样本随机性降低,梯度下降方向趋于稳定,训练就由SGD向GD趋近,这导致模型更容易收敛于初始点附近的某个局部最优解,从而抵消了计算力增加带来的好处。如何既增大batch size,又不降低精度,是机智团队面临的首要挑战。

图示 大batch size带来精度下降
3.2 多机多卡扩展性差
深度训练通常采用数据并行模式,数据并行模式将样本分配给不同的GPU进行训练。相比模型并行,数据并行简单且可扩展,成为目前主流的分布式训练方式。

图示 数据并行
分布式训练数据并行模式下,经典的部署方式是独立的参数服务器(Parameter Server)来做训练过程中梯度的收集、分发和更新工作,每一次迭代所有的GPU都要与PS多次通信来获取、更新参数;当节点超过一定数量时,PS的带宽以及处理能力将成为整个系统的瓶颈。
AI训练系统和传统后台系统之间的一个最主要区别是,传统后台系统可以通过增加节点的方式来分担访问请求,节点之间没有强相关的关系;而AI训练系统在训练模型时需要参与训练的所有节点都不断的与模型参数服务器交换和更新数据,这无形中相当于对整个系统增加了一把大锁,对整个系统中单节点的带宽和处理能力要求非常高,这也是AI训练系统的特别之处,不能通过简单的增加节点来提升系统负载能力,还需要解决多节点的扩展性问题。
所以如何在架构部署和算法层面减少对带宽需求,控制多机扩展中参数传输对训练速度的影响,使AI训练集群性能可线性扩展,是机智团队面临的另一项挑战。
3.3 如何选择合适的超参
此外,由于超参较多,而每一个超参分布范围较广,使得超参调优的耗时较长,特别是针对ImageNet这种超大数据集的情况。前文提过,CIFAR-10数据集上训练的ResNet模型就有16个超参。
随着项目进展,团队还引入了很多新的关键技术,如后面将会提到的LARS算法、分层同步算法、梯度融合策略,Batch Norm替换等都会增加模型超参数量,如何在可接受的时间内寻找到较优解,是机智团队面临的第三个重大挑战。
四 训练速度提升的关键技术
机智团队针对上述挑战,分别在大batch size训练,多机扩展性,及超参调整方法上取得突破,并应用到ImageNet训练场景中,能够在6.6分钟内完成ResNet-50训练,4分钟完成AlexNet训练——这是迄今为止ImageNet训练的最高世界纪录。在这个过程中,机智团队在吸收业界最佳实践的同时,深度融合了多项原创性关键技术。
4.1 超大batch size 的稳定收敛能力
1)半精度训练与层次自适应速率缩放(LARS)算法相结合
为了提升大batch size情况下的可扩展性,机智团队将训练数据和参数采用半精度浮点数的方式来表示,以减少计算量的同时降低带宽需求。但半精度浮点数的表示方式不可避免的会降低模型收敛精度。
为了解决精度下降问题,机智团队引入了层次自适应速率缩放(LARS)算法。LARS算法由You et al. (2017)[3]最先提出,该算法通过对不同的层使用不同的Learning Rate,大幅度提升了大batch size场景下的训练精度,但实际测试发现,直接将LARS算法应用于半精度模型训练造成很大的精度损失,这是由于乘以LARS系数后, 很多参数因半精度数值表示范围较小而直接归0。

图示 LARS学习率更新公式
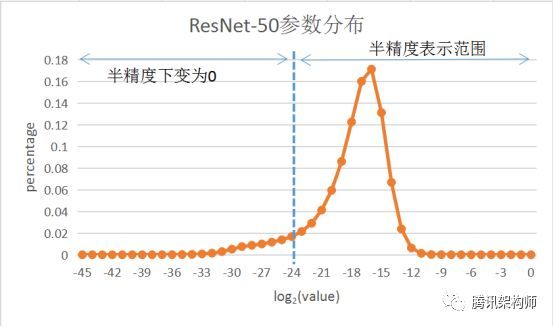
图示 参数用半精度表示导致精度丢失
为此,机智团队引入了混合精度训练方法来解决这个问题,通过将半精度参数转化成单精度,然后再与LARS结合,即半精度训练,单精度LARS优化及参数更新。相应的,在更新参数时使用loss scaling方法成倍扩大loss(并对应减少学习率)避免归0影响精度。测试结果显示,这一方法,一方面保证了计算速度,另一方面也取得了很好的收敛效果。
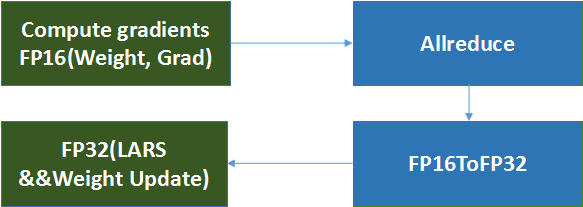
图示 混合精度训练
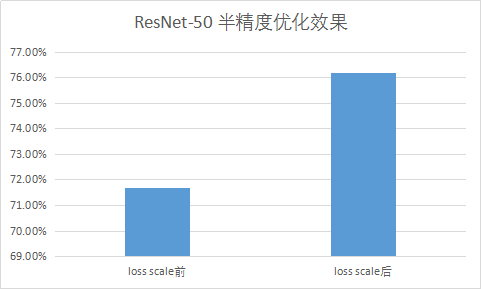
图示 ResNet-50 半精度优化效果
2)模型和参数的改进
我们在32K下复现了You et al. (2017)的测试结果,但batch size扩展到64K时,训练精度未能达到基准准确性。为了提高在64K下的收敛准确性,我们对参数和模型进行了改进:1) 只对weight做正则化。 2)在You et al. (2017)模型的基础上,进一步改进AlexNet模型。
正则化通过在损失函数后加一项惩罚项![]() ,是常用的防止模型过拟合的策略。大多数深度学习框架默认会对所有可学习的参数做正则化,包括weight, bias, BN beta和gamma(batch norm中可学习的参数)。我们发现bias, beta, gamma的参数量相对于weight来说非常小,对于AlexNet模型,bias, beta, gamma参数量总和仅占总参数量的0.02%。
,是常用的防止模型过拟合的策略。大多数深度学习框架默认会对所有可学习的参数做正则化,包括weight, bias, BN beta和gamma(batch norm中可学习的参数)。我们发现bias, beta, gamma的参数量相对于weight来说非常小,对于AlexNet模型,bias, beta, gamma参数量总和仅占总参数量的0.02%。
因此,bias, beta, gamma不会给模型带来过拟合,如果我们对这些参数进行正则化,增加了计算量,还会让模型损失一些灵活性。经过实验验证,我们发现不对bias, beta, gamma做正则化,模型提高了约1.3%的准确性。
优化正则化策略后模型收敛性得到了提升,但是AlexNet还是没有达到基准准确性。通过对AlexNet训练参数和输出特征的分析,我们发现Pool5的特征分布(如下图示,颜色浅表示数据分布少,颜色深的表示数据分布多,总体看数据分布范围很广)随着迭代步数的增加,方差越来越大,分布变化很剧烈,这样会导致学习和收敛变得困难。
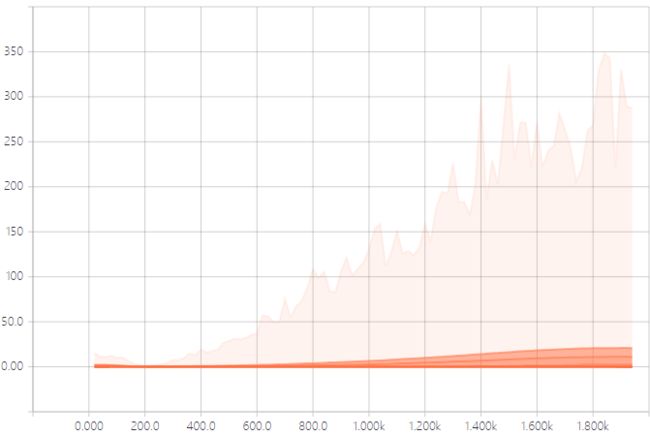
图示 Pool5的输出特征分布图(横轴是迭代步数,纵轴是特征分布)
这个结果启发我们在Pool5后插入一个Batch Norm层,用以规范特征的分布。如下图所示,完善AlexNet后,BN5后面输出的特征图分布更加均匀,64K batch在100 epochs下收敛到58.7%,不损失准确性的同时完成了加速训练。

图示 使用Batch Norm改造AlexNet

图示 Pool5+BN5的输出特征分布图(横轴是迭代步数,纵轴是特征分布)

图示 使用BN改造AlexNet前后的收敛精度比较
3)超参调优
模型超参调优是深度学习中成本最高的部分之一,大模型的训练过程是以小时或天计算的,特别是训练数据集较大的情况下。因此需要有更高效的思路和方法来调优超参,机智平台团队在这个方面主要采取了如下思路:
• 参数步长由粗到细:调优参数值先以较大步长进行划分,可以减少参数组合数量,当确定大的最优范围之后再逐渐细化调整,例如在调整学习速率时,采取较大步长测试发现:学习率lr较大时,收敛速度前期快、后期平缓,lr较小时,前期平缓、后期较快,根据这个规律继续做细微调整,最终得到多个不同区间的最佳学习速率;
• 低精度调参:在低精度训练过程中,遇到的最大的一个问题就是精度丢失的问题,通过分析相关数据,放大低精度表示边缘数值,保证参数的有效性是回归高精度计算的重要方法;
• 初始化数据的调参:随着网络层数的增多,由于激活函数的非线性,初始化参数使得模型变得不容易收敛,可以像VGGNet那样通过首先训练一个浅层的网络,再通过浅层网络的参数递进初始化深层网络参数,也可以根据输入输出通道数的范围来初始化初始值,一般以输入通道数较为常见;对于全连接网络层则采用高斯分布即可;对于shortcut的batch norm,参数gamma初始化为零。
以上思路在4分钟训练ImageNet项目中提升了调参效率。但调参是个浩繁的工作,后续将由内部正在测试的AutoML系统来进行。
通过以上三个方面,在ImageNet数据集上,机智平台可将ResNet-50/AlexNet在batch size 为64K时训练到基准精度!

图示 AlexNet 收敛性优化
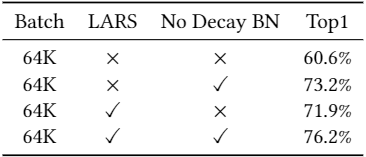
图示 ResNet-50 收敛性优化
4.2 超大规模GPU集群(1024+GPUs)线性扩展能力
1)参数更新去中心化
数据并行训练方式下,每一次迭代都需要做梯度规约,以TensorFlow为代表的经典分布式训练部署方式中,中心化的参数服务器(Parameter Server)承担了梯度的收集、平均和分发工作,这样的部署方式下PS的访问带宽容易成为瓶颈,严重影响可扩展性,机智团队最初应对方法是引入HPC领域常用的去中心化的Allreduce方式,然而目前流行的NCCL2或baidu-allreduce中的Allreduce采用的基于环形拓扑的通信方式,在超大规模GPU集群场景下数据通信会有很大的延时开销。
机智团队进一步将Allreduce算法进行了改进,并成功的部署在1024+GPUs的异构集群中,达到了理想的扩展效率。

图示 去中心化的参数规约

图示 原始版本的Ring Allreduce
2)利用分层同步和梯度分段融合优化Ring Allreduce
在分布式通信中,参数传输耗时可用如下公式表达:
![]()
其中α 代表单节点单次数据传输的延时,比如准备数据,发送数据接口调用等;P为数据在节点间传输的次数,通常是节点个数的一个倍数,β 为参数传输耗时的系数,不同参数传输方法,这个系数不同;B为网络带宽,M为参数总字节数,(M/B)为单次完整参数传输耗时。[6]
由以上公式可以看出,参数M越大,第二项所占的比重就越大,受第一项的影响就越小,即P对整体时间的影响则越小;参数M越小,则第一项所占的时间不可忽略,随着P的增大,对总体时间则影响越大。对于传输采取Ring Allreduce算法来讲, 全局规约操作对带宽的需求接近于常数,不随节点数增加而增加,所以β * (M/B)接近为常数,可变因数为 α * P;网络模型越小,传输的数据量越小越散,则 α * P 这块的比重越大,整体的扩展性也就越差。
比如,在AlexNet神经网络中,除了两层参数量较大的全连接层,其余的BN层和卷积层参数量较少,各层的参数分布差异很大。在我们的实验环境中,使用Ring Allreduce传输方式,测试不同数据包大小传输耗时如下图所示。从图中可以看出,Ring Allreduce的时间开销会随着GPU个数的增加而显著增大。

图示 Ring-Allreduce不同节点数下的传输耗时
此外,传输数据块太小也不能充分利用带宽,多个小块传输带来极大的overhead,如图所示。可以看到发送同量数据时,小数据包额外开销大,不能高效利用带宽。
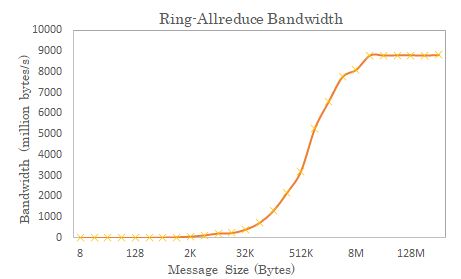
图示 在100Gbps RoCE v2网络中使用2机8卡Ring-Allreduce测试带宽
经过以上对神经网络每层的参数和数据包传输特性的分析,机智团队得出以下结论:
(1) 随着集群节点增多,Ring Allreduce传输模式不够高效。随着节点增多,传输耗时中α* P部分比例会逐步增大。
(2) Ring Allreduce算法对小Tensor不够友好。算法将待规约的数据拆分为N等份(N为节点总数),这导致节点数大幅增加时,Tensor碎片化,通信网络传输大量小数据包,带宽利用率很低。
针对上述问题,机智团队提出了如下改进方案:
(1) 分层同步与Ring Allreduce有机结合:对集群内GPU节点进行分组,减少P对整体时间的影响。如前论述,当P的值对系统性能影响较大时,根据具体的集群网络结构分层,同时跨节点规约使用Ring Allreduce算法规约, 这一改进有效的减少了每层Ring参与的节点数,降低了传输耗时中 α * P 的占比。如下图所示。原本需要对16个(即P=16)GPU进行AllReduce,现将16个GPU分为4组,每组4个GPU,首先在组内进行Reduce(4组并行执行,P1=4),然后再以每组的主GPU间进行Allreduce(P2=4),最后在每组内进行Broadcast(P3=4),这样便大大地减少了P的影响,从而提高Allreduce的性能。
(2) 梯度融合,多次梯度传输合并为一次:根据具体模型设置合适的Tensor size阈值,将多次梯度传输合并为一次,同时超过阈值大小的Tensor不再参与融合;这样可以防止Tensor过度碎片化,从而提升了带宽利用率,降低了传输耗时。
(3) GDR技术加速Ring Allreduce:在前述方案的基础上,将GDR技术应用于跨节点Ring,这减少了主存和显存之间的Copy操作,同时为GPU执行规约计算提供了便利;
注:GDR(GPU Direct RDMA)是RDMA技术的GPU版本,可以提供远程节点间显存直接访问,能大幅降低了CPU工作负载。
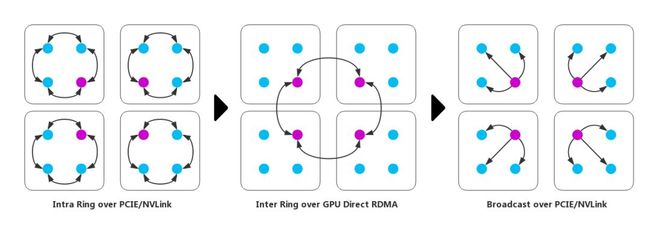
图示 改进的分层Ring Allreduce with GDR
在具体到ImageNet训练问题中,在测试梯度融合时,机智团队根据对模型各层参数大小分析和实测结果,提出了分段融合策略,将AlexNet和ResNet-50各层分为两段,各融合为一个Tensor参与Ring Allreduce。经过测试和分析,在1024卡场景下,AlexNet在20层和21层处分段可以达到最好效果;ResNet-50在76层和77层之间分段速度达到最优,如下图所示。
经分段融合策略后,极大提高了反向计算和传输的并行度,提升了训练速度。目前分段融合已可根据前向计算和反向计算耗时,及传输耗时,结合实际硬件配置和网络模型对传输性能进行建模,自动实现最优分段策略,自适应地选择需要合并的参数,以达到系统最佳扩展性能。
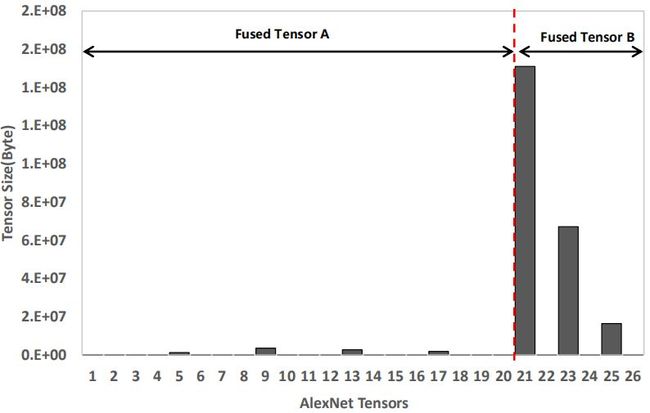
图示 AlexNet梯度分段融合策略

图示 ResNet-50梯度分段融合策略

图示 1024卡场景下分段融合前后吞吐量对比

图示 1024卡场景下分层同步前后吞吐量对比
3)使用Pipeline机制降低IO延迟
GPU引入深度学习之后,模型训练速度越来越快,最优加速性能不仅依赖于高速的计算硬件,也要求有一个高效的数据输入管道。
在一轮训练迭代中,CPU首先从磁盘读取数据并作预处理,然后将数据加载到计算设备(GPU)上去。一般实现中,当 CPU 在准备数据时,GPU处于闲置状态;相反,当GPU在训练模型时,CPU 处于闲置状态。因此,总训练时间是 CPU预处理 和 GPU训练时间的总和。
机智团队为解决IO问题,将训练样本集部署在由SSD盘组成的存储系统上,以保证CPU访问数据的带宽不受网络限制;同时,更为关键的是引入了Pipeline机制,该机制将一次训练迭代中的数据读入及处理和模型计算并行起来,在做模型计算的同时做下一轮迭代的数据读取处理并放入自定义“无锁”队列,并通过GPU预取机制提前把处理好的数据从队列中同步到GPU显存中,当做下一轮的模型计算时直接从显存读取数据而不需要再从CPU或磁盘读取,做到将数据读取隐藏,IO和计算并行起来。
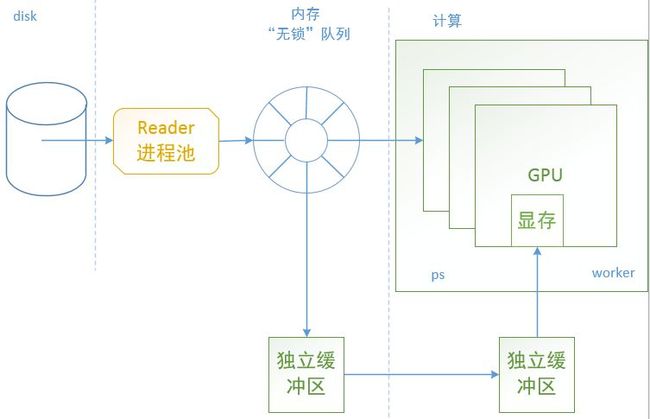
图示 Pipeline机制示意图

图示 “无锁”队列出入队耗时对比
通过以上三方面,机智平台在1024卡以上跑ResNet-50,扩展性也可以达到~99%,在2048卡上跑ResNet-50,扩展性还可以保持在97%!

图示 ResNet-50/AlexNet多机扩展性
五 平台价值
人工智能越来越多的融入到人们生活当中,涵盖各行各业,包括衣食住行,交通、个性化产品等;可以服务于人们需求的人工智能服务在未来会像水和电一样成为基本需求,机智机器学习平台正是在这种背景下应运而生。
提升训练ImageNet的速度,只是机智团队推动AI发展工作中一小部分;事实上,服务好游戏AI等AI业务,助力AI团队在建设AI服务时,聚焦用户需求,而AI服务背后的模型训练、优化,模型部署和运营触手可得,才是机智的真正使命。机智机器学习平台当前主要提供训练加速能力。
1)训练加速
快速完成模型训练意味着可以做更多的模型/算法尝试;这不仅是体现平台能力的一个重要指标,也是增加业务竞争力的一个关键所在。如果一个产品模型的训练时间以周记或以月记,那这个产品也是生命力不旺盛的。以下是机智的两个典型应用案例:
• X业务的训练数据是结构化数据且量大,模型比较复杂;一直以来训练好一个模型需要一天以上,这对于快速迭代模型算法来说是远远不够的。在应用了机智机器学习平台后,可以在约10分钟时间迭代一个模型,极大的加速了训练迭代效率,为业务的成功奠定了坚实的基础。
• 计算机视觉,是人工智能应用的重要领域,已在交通、安防、零售、机器人等各种场景中应用开来。计算机视觉中网络模型的关键部件就是CNN,快速的将CNN网络训练好可以极大的提升产品落地速度。以业界最著名的ImageNet数据集为例,要将ResNet-50模型在其上训练到75%以上准确率,普通单机单卡需要一周左右时间。在机智机器学习平台上,这样的应用只需要6.6分钟。
六 展望
未来,机智团队将继续保障游戏AI业务的快速迭代,把解决imagenet训练问题中所积累的加速方案应用到游戏AI中,将游戏AI的大batch size收敛问题和训练速度问题彻底解决,协助业务取得新的突破性成果。此外,机智团队将在平台性能,功能上持续完善:
1)平台性能
机智将结合模型压缩/剪枝,量化技术,在通信传输中统筹多种all-reduce算法,做到对不同场景的模型:
• 计算瓶颈的模型多机达到线性扩展
• 传输瓶颈的模型多机达到90%以上扩展效率
2)平台功能
a)AutoML(自动调参)
机智团队认为,算法工程师应当专注于创建新网络,推导新公式,调整超参数的浩繁工作,交给机智平台帮你自动完成。
b)一站式的管理服务
机器学习的模型训练过程是个复杂的系统工整,涉及到对可视化任务的管理,对各种资源的管理(比如CPU, GPU, FPGA, ASIC等)和调度,对训练数据和结果数据的管理,高质量的服务体系等,将这一整套流程都打通,并且做到对用户友好,所见即所得,是算法工程师验证想法最基本的需求。机智平台将提供一站式的管理服务,想你所想,助你成功。
此外,计算机视觉类加速只是起点,未来在功能方面,机智平台将支持多场景、多模型;结合更广义的AutoML技术,让AI技术赋能更广大的业务,我们的目标是:
为用户提供训练,推理,模型托管全流程计算加速服务。
最终,建立从训练加速到部署上线一站式服务平台,打造AI服务基础设施,助力AI业务取得成功。
七 致谢
在研究和解决imagenet训练项目中,机智团队小伙伴们通力合作,最终在这个问题上取得了突破。在此要特别感谢团队内小伙伴——TEG兄弟部门运营管理部,香港浸会大学计算机科学系褚晓文教授团队;是大家的精诚团结和专业精神,才得以让我们在这个业界权威基准上取得新的重大突破。
此外还要隆重感谢机智平台合作伙伴——TEG兄弟部门AI平台部,网络平台部,感谢兄弟部门小伙伴们一直以来的支持和信任。期盼在未来的前进道路上,机智团队仍然能与各位同行,去创造新的好成绩。
八 参考资料
[1] Large Scale Visual Recognition Challenge 2017
http://image-net.org/challenges/LSVRC/2017/
[2] http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/
[3] ImageNet Training in Minutes
https://arxiv.org/pdf/1709.05011.pdf
[4] Facebook 1小时训练ImageNet
https://research.fb.com/publications/ImageNet1kIn1h/
[5] Exploring the Limits of Language Modeling
https://arxiv.org/pdf/1602.02410.pdf
[6]Optimization of Collective Communication Operations in MPICH
http://www.mcs.anl.gov/~thakur/papers/ijhpca-coll.pdf
原allreduce的公式为:t = 2(P − 1)α + (2(P − 1)β + (P −1)γ)M/P,本文根据场景进行了简化描述。
其中P为进程个数(此次亦表示GPU个数),α 代表单节点单次数据传输的延时,比如准备数据,发送数据接口调用等;β为点对点间单个字节的传输时间,通常表示为1/B,B为网络带宽;γ为两个参数的单次加法运算时间;M为参数总字节数。
[7]Google Vizier: A Service for Black-Box Optimization 4.4.2节
https://ai.google/research/pubs/pub46180
[8]PowerAI DDL, https://arxiv.org/pdf/1708.02188.pdf
[9] Extremely Large Minibatch SGD:Training ResNet-50 on ImageNet in 15 Minutes, https://arxiv.org/abs/1711.04325
本项目论文《Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes》,将首先在arxiv上提交供查阅。
