Fork / Join框架在不同配置下如何工作?
就像即将上映的《星球大战》一样,围绕Java 8并行性的批评也充满了兴奋。 并行流的语法糖带来了一些炒作,就像我们在预告片中看到的新型光剑一样。 现在,有了许多使用Java进行并行处理的方法,我们希望了解性能优势和并行处理的危险。 经过260多次测试运行,从数据中获得了一些新见解,我们希望在本文中与您分享。

分叉/加入:分叉唤醒
ExecutorService与Fork / Join Framework与并行流
很久以前,在一个遥远的星系中……。 我的意思是,大约10年前,并发只能通过3rd party库在Java中使用。 然后出现了Java 5,并在语言中引入了java.util.concurrent库,该库受到Doug Lea的强烈影响。 ExecutorService可用并为我们提供了处理线程池的直接方法。 当然,java.util.concurrent一直在发展,并且在Java 7中,在ExecutorService线程池的基础上引入了Fork / Join框架。 借助Java 8流,我们已经为使用Fork / Join提供了一种简单的方法,对于许多开发人员而言,它仍然有些神秘。 让我们找出它们之间的比较。
我们完成了两项任务,一项是CPU密集型任务,另一项是IO密集型任务,并使用相同的基本功能测试了4种不同的方案。 另一个重要因素是我们用于每个实现的线程数,因此我们也对其进行了测试。 我们使用的机器有8个内核 ,因此我们有4、8、16和32个线程的变种,以大致了解结果的发展方向。 对于每个任务,我们还尝试了一个单线程解决方案,您不会在图中看到它,因为执行起来需要花费更长的时间。 要详细了解测试的运行方式,您可以查看下面的基础部分。 现在,让我们开始吧。
索引580万行文本的6GB文件
在此测试中,我们生成了一个巨大的文本文件,并为索引过程创建了类似的实现。 结果如下所示:
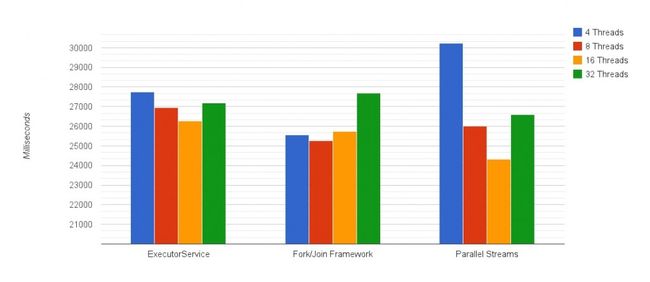
文件索引测试结果
**单线程执行:176,267毫秒,或将近3分钟。
**请注意,图形开始于20000毫秒。
1.更少的线程将使CPU处于未使用状态,太多的线程将增加开销
您在图表中注意到的第一件事是结果开始采用的形状–您仅从这4个数据点就可以了解每个实现的行为。 临界点在8到16个线程之间,因为某些线程在文件IO中处于阻塞状态,并且添加比内核更多的线程有助于更好地利用它们。 当有32个线程进入时,由于额外的开销,性能会变差。
比亚军快1秒:直接使用Fork / Join
除了语法糖(lambdas!我们没有提到lambdas),我们已经看到并行流的性能比Fork / Join和ExecutorService实现的更好。 6GB的文本在24.33秒内被索引。 您可以在这里信任Java来提供最佳结果。
3.但是...并行流也表现最差:唯一的变化超过了30秒
这再次提醒了并行流如何使您减速。 假设这种情况发生在已经运行多线程应用程序的计算机上。 在可用线程数量较少的情况下,直接使用Fork / Join实际上比通过并行流要好-5秒的差异,将这两个线程进行比较时大约要付出18%的代价。
4.不要使用图片中带有IO的默认池大小
当为并行流使用默认池大小时,计算机上相同数量的内核(此处为8个内核)比16个线程版本的性能差了近2秒。 如果使用默认池大小,则要加收7%的罚款。 发生这种情况的原因与阻塞IO线程有关。 还有更多的等待正在进行,因此引入更多的线程可以使我们更多地使用所涉及的CPU内核,而其他线程则需要等待调度而不是空闲。
如何更改并行流的默认Fork / Join池大小? 您可以使用JVM参数更改常见的Fork / Join池大小:
-Djava.util.concurrent.ForkJoinPool.common.parallelism=16(默认情况下,所有Fork / Join任务都使用一个公共静态池,其大小与内核数相同。这样做的好处是,通过在不使用期间为其他任务回收线程,从而减少了资源使用。)
或者…您可以使用此技巧并在自定义的Fork / Join池中运行并行流。 这将覆盖通用的Fork / Join池的默认用法,并允许您使用自己设置的池。 偷偷摸摸。 在测试中,我们使用了公共池。
5.单线程性能比最佳结果差7.25倍
并行性提供了7.25倍的改进,并且考虑到该机器具有8个核心,因此非常接近理论上的8倍预测! 我们可以将其余的归因于开销。 话虽如此,即使我们测试的最慢的并行性实现(这次是具有4个线程的并行流(30.24sec))的性能也比单线程解决方案(176.27sec)好5.8倍。
检查数字是否为质数
在下一轮测试中,我们完全消除了IO,并检查了确定一个真正大的数字是否为素数所需的时间。 多大? 19位数字 。 1,530,692,068,127,007,263,或换句话说:五百一十九亿四千三百四十四万亿三千三百八十亿八千八百三十八万三千三百三十三。 啊,让我呼吸一下。 无论如何,除了运行到平方根以外,我们没有使用任何优化,因此即使我们的大数没有除以2只是为了延长处理时间,我们也检查了所有偶数。 剧透警告:这是首要的,因此每个实现都运行相同数量的计算。
结果是这样的:

素数测试结果
**单线程执行:118,127毫秒,或将近2分钟。
**请注意,图形开始于20000毫秒
1. 8和16个线程之间的差异较小
与IO测试不同,这里没有IO调用,因此8个线程和16个线程的性能基本相似,除了Fork / Join解决方案。 实际上,我们已经进行了多组测试,以确保由于这种“异常”而在这里获得良好的结果,但事实证明,一次又一次地非常相似。 我们很高兴在下面的评论部分中听到您对此的想法。
2.所有方法的最佳结果相似
我们看到所有实现都共享大约28秒的相似最佳结果。 无论我们尝试采用哪种方法,结果都是一样的。 这并不意味着我们对使用哪种方法都无所谓。 查看下一个见解。
3.并行流比其他实现更好地处理线程重载
这是更有趣的部分。 通过该测试,我们再次看到运行16个线程的最高结果来自使用并行流。 而且,在此版本中,使用并行流是线程号的所有变体的一个好方法。
4.单线程性能比最佳结果低4.2倍
另外,在运行计算密集型任务时使用并行性的好处几乎比使用文件IO的IO测试要差2倍。 这是有道理的,因为它是CPU密集型测试,与之前的测试不同,我们可以通过减少内核等待被IO阻塞的线程的时间来获得额外的好处。
结论
我建议您去参考源代码,以了解有关何时使用并行流的更多信息,并在您使用Java进行并行化时随时进行仔细的判断。 最好的方法是在登台环境中运行与这些测试类似的测试,在该环境中,您可以尝试并更好地了解要面对的挑战。 您必须要注意的因素当然是运行的硬件(和要测试的硬件)以及应用程序中的线程总数。 这包括公用的Fork / Join池和团队中其他开发人员正在处理的代码。 因此,在添加自己的并行性之前,请尝试检查它们并获得应用程序的完整视图。
基础工作
为了运行此测试,我们使用了具有8个vCPU和15GB RAM的EC2 c3.2xlarge实例。 vCPU意味着存在超线程,因此实际上我们在这里有4个物理内核,每个物理内核都像2个内核一样工作。就OS调度程序而言,我们在这里有8个内核。 为了尽可能使它公平,每个实现运行了10次,并且我们采用了运行2到9的平均运行时间。这是260次测试运行,! 另一重要的是处理时间。 我们选择的任务要花20秒钟以上的时间,因此差异更容易发现,并且不受外部因素的影响。
下一步是什么?
原始结果可在此处获得 ,代码在GitHub上 。 请随时修改它,并让我们知道您得到什么样的结果。 如果您对我们错过的结果有更多有趣的见解或解释,我们很乐意阅读并添加到帖子中。
翻译自: https://www.javacodegeeks.com/2015/01/forkjoin-framework-vs-parallel-streams-vs-executorservice-the-ultimate-forkjoin-benchmark.html