tensorflow2caffe(3) : 如何将tensorflow框架下训练得到的权重转化为caffe框架下的权重参数
在前两期专栏tensorflow2caffe(1)和tensorflow2caffe(2)中,笔者向大家介绍了caffemodel文件类型下的参数架构和如何取出tensorflow框架下训练参数。在本期中,笔者将向大家阐述,如何去将tensorflow框架下训练得到的参数转化为caffe框架下的规定格式的参数。首先,我们来捋一捋目前我们手里面已经有了哪些东西:
1. 我们有自己的tensorflow训练程序,也就是说我们知道训练的网络架构。
2. 我们能够得到tensorflow架构训练得到的参数,并且我们知道我们的主要目的是得到一个caffemodel。
那么,请读者朋友们想一想,我们现在还缺少什么东西呢?
要得到以上问题的答案,不妨思考如下这个问题,当我们使用caffe框架训练模型完毕后,需要测试这个模型,我们必须的东西什么?首先我们需要一个caffemodel,其次,在模型测试的时候,我们需要一个.prototxt文件,该文件记录了网络前传的逻辑顺序。
写到这里,知其然不如知其所以然,笔者不妨多说两句。各位读者朋友知道,当使用caffe框架训练模型的时候,我们会使用一个prototxt文件,姑且就叫他train.prototxt吧。那么,在测试模型的时候,我们同样使用了一个prototxt文件,姑且将该文件称为test.prototxt。那么,如何将train.prototxt、训练得到的caffemodel文件还有test.prototxt文件关联起来呢?答案是这样的:caffemodel里面包含了绝大部分train.prototxt的内容,就如tensorflow2caffe(1)中所述。为什么要这么做,是因为train.prototxt除了约定了训练网络架构与参数配置,更重要的是规定了键名,这个键名就是layer中的"name"参数,而该键名也会记录在caffemodel中。在我们训练完毕模型并使用test.prototxt结合caffemodel对模型进行测试时,相当于是根据test.prortotxt中的layer的"name"参数去取得键名,然后根据这个键名在caffemodel中取得参数,然后才能进行网络的前向传播。到这里,请读者朋友们明白,test.prototxt是根据键名去caffemodel中取参数的,也就是说,如果提供的键名在caffemodel中找寻不到,那么也就无从取值。这其实和我们使用caffe框架训练模型时需要去finetune成熟模型的部分层的参数,于是我们就将我们的模型中需要finetune的layer的"name"参数改成finetune的caffemodel中对应layer的"name"一样是同一个道理。
言归正传,经过上面一段话的阐述,我们明白了,我们目前还缺少什么东西。
(1) 我们需要一个test.prototxt。
(2) 我们需要将tensorflow训练出来的参数转化成文本,并且写在test.prototxt里面。
首先,对于(1),笔者想说的是,在撰写test.prototxt的时候,网络架构应该按照tensorflow训练程序的网络架构来。也就是说,在写作test.prototxt的时候,需要对tensorflow框架下面的训练网络架构相当熟悉,并且明了tensorflow和caffe下面的框架协议规范。举个栗子,在写tensorflow卷积层时候,有很多读者朋友可能会使用padding = "SAME" 这个参数,可是在caffe,没有那么智能的操作,因此在写test.prototxt框架下面卷积层的定义参数的时候,需要人为地去pad,再比如说,tensorflow下面的卷积实现的时候有时没有在权重中加上bias,只有weight,那么在撰写test.prototxt的时候,就需要在该卷积层convolution_param的大括号中,加上"bias_term: false"的定义,这就需要对网络中数据流向和数据维度有相当程度的了解。除了这一点,还需要读者朋友们注意的是,需要按需去重写某些前传层。比如说,tensorflow下面实现了一个激活函数
def lrelu(x, leak=0.2, name = "lrelu"):
return tf.maximum(x, leak*x)
这种函数caffe官方是没有定义的,也就是说,需要读者朋友们自己去写作caffe框架下的前传代码(不需反传函数)。并且,对于tensorflow和caffe两个框架,对于某些层的实现机制是不一样的。也就是说,在进行这一步的时候,请大家务必对训练代码和caffe编程了解深刻,这样才能够在caffe框架下实现tensorflow的某些自定义层的逻辑。最后,形成一个完整的test.prototxt。
接下来,笔者详细地介绍一下(2)。
在tensorflow2caffe(2)中,我们已经能够打印出tensorflow下训练得到的权重参数的名字了,也就是说可以得到权重。以卷积层为例,tesorflow框架下卷积层的权重shape是[kernel_height, kernel_width, input_channels, output_channels](相反,反卷积层的权重shape是[kernel_height, kernel_width, output_channels, input_channels])。
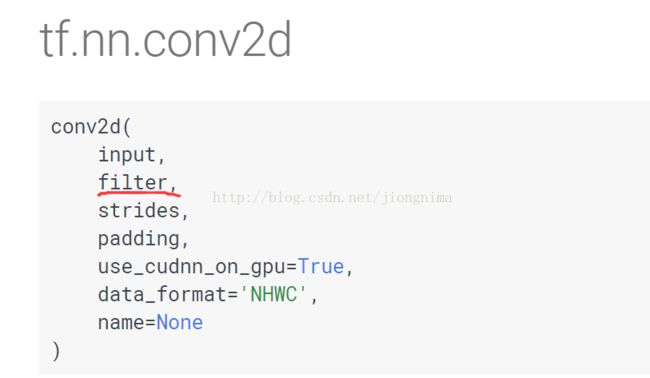
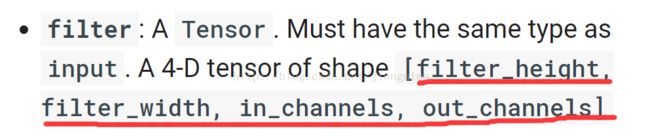

那么,caffe下面的参数规格在哪里定义的呢?笔者提醒读者朋友们,在tensorflow2caffe(1)中笔者有贴出读出的caffemodel转化得到的文本文件截图,读者朋友们仔细观察可以发现,caffemodel在每一个layer中,记录参数的blobs大括号尾部,有一个shape属性,里面的dims就记录了caffe框架下的参数格式,在caffe框架中,卷积层权重参数shape是[output_channels, input_channels, kernel_height, kernel_width](相反地,反卷积层权重参数是[input_channels, output_channels, kernel_height, kernel_width])。因此,我们需要将参数的维度加以变换。
到这里的时候,笔者的困惑就来了,举个栗子,某个卷积层输入channel是128,输出channel是256,二维卷积核长宽都是4,没有bias参数,那么,该卷积层的权重参数数量是多少呢?
答案是128×256×4×4 = 524288个,这个时候,用什么函数或者工具能够轻而易举地转化权重参数的维度呢?
笔者最开始在解决这个问题的时候也一筹莫展,甚至使用c语言进行过数组处理,可是事实证明,这样处理的方式是低效的。那么如何取得参数维度转化时的高效率呢?笔者的同事@feiyang想出了解决方案,使用numpy的swapaxes函数,几行代码就可解决问题。

笔者使用的代码如下:
#!/usr/bin/python
import tensorflow as tf
import numpy as np
with tf.Session() as sess:
new_saver = tf.train.import_meta_graph('.model.meta')
for var in tf.trainable_variables():
print var.name
new_saver.restore(sess, tf.train.latest_checkpoint('./checkpoint_dir/'))
all_vars = tf.trainable_variables()
for v in all_vars:
name = v.name
fname = name + '.prototxt'
fname = fname.replace('/','_')
print fname
v_4d = np.array(sess.run(v))
if v_4d.ndim == 4:
#v_4d.shape [ H, W, I, O ]
v_4d = np.swapaxes(v_4d, 0, 2) # swap H, I
v_4d = np.swapaxes(v_4d, 1, 3) # swap W, O
v_4d = np.swapaxes(v_4d, 0, 1) # swap I, O
#v_4d.shape [ O, I, H, W ]
f = open(fname, 'w')
vshape = v_4d.shape[:]
v_1d = v_4d.reshape(v_4d.shape[0]*v_4d.shape[1]*v_4d.shape[2]*v_4d.shape[3])
f.write(' blobs {\n')
for vv in v_1d:
f.write(' data: %8f' % vv)
f.write('\n')
f.write(' shape {\n')
for s in vshape:
f.write(' dim: ' + str(s))#print dims
f.write('\n')
f.write(' }\n')
f.write(' }\n')
elif v_4d.ndim == 1 :#do not swap
f = open(fname, 'w')
f.write(' blobs {\n')
for vv in v_4d:
f.write(' data: %.8f' % vv)
f.write('\n')
f.write(' shape {\n')
f.write(' dim: ' + str(v_4d.shape[0]))#print dims
f.write('\n')
f.write(' }\n')
f.write(' }\n')
f.close()
首先,代码的上半部分和tensorflow2caffe(2)中的一样,至于代码的下半部分,就涉及到参数维度的转换了,笔者将每一层对应的权重参数逐一取出来,并相应地新建了.prototxt文件并按照caffemodel下面的参数格式写入了文件中。
值的读者朋友们注意的是,由于笔者模型下面只涉及到四维(卷积层,反卷积层)和一维(batch_norm的乘数(scale),偏置(offset))的参数,因此笔者在写参数文件中只对这两类参数做了处理,读者朋友们在使用的时候可以按需作出处理。
运行一下上述程序。
可以看到,转化为caffe框架格式的各层权重参数文件已经保存在了路径下:

随便点开一个卷积层的参数文件,头尾部分如下两图所示:
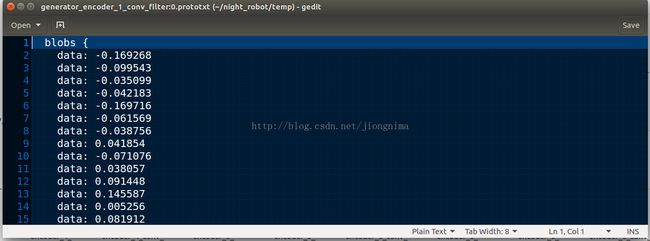
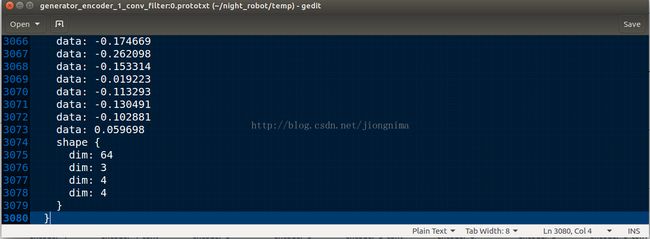
读者朋友们可以看到,权重参数的shape是不是变成了caffe框架下的[output_channels, input_channels, kernel_height, kernel_width]了呢?
现在,我们有了一个test.prototxt文件,还有了各个层的参数,那么,下面就将我们转化得到的参数写入test.prototxt文件就好了。那么,参数应该写到层里面的什么地方呢?很简单,直接将我们得到的参数文件写入对应层的大括号内就好辣!ヾ(✿゚▽゚)ノ,如下代码示意:
layer {
name: "conv_layer_name"
type: "Convolution"
bottom: "bottom_blob"
top: "top_blob"
param { lr_mult: ... }
convolution_param {
num_output: output_dims
kernel_size: kernel_size
pad: padding_size
stride: stride
bias_term: false
}
#add params
blobs: {
data: ...
...
shape {
dim: ...
dim: ...
dim: ...
dim: ...
}
}
}
笔者在这里教大家一个小技巧,我们既然得到了记录各层参数的众多.prototxt文件,又有一个test.prototxt,不如我们将test.prototxt按照添加断点拆成若干部分,然后制作一个.sh脚本,就可以将各层参数添加进test.prototxt文件中了哦,姑且称这个添加过权重参数的文件为model.prototxt文件吧。
笔者就是将test.prototxt按照拼接断点拆开:
然后再将上图中的文件和转化得到的.prototxt格式的众多参数文件放在同一目录下,并且使用一个index.txt文件从上到下记录了拼接顺序:
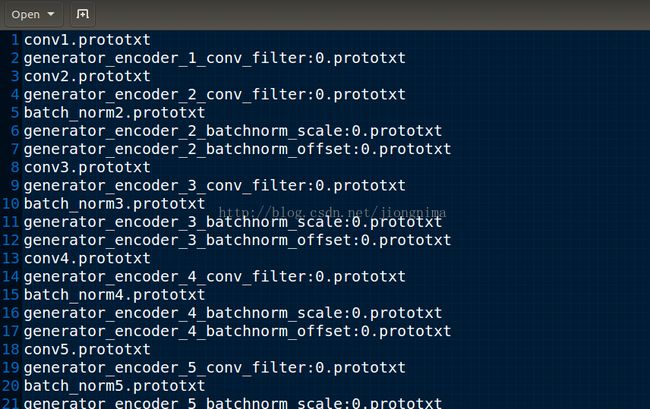
然后使用一个名为ss.sh的脚本文件作拼接:
#!/bin/bash
cat index.txt |while read line
do
cat $line >>model.prototxt
done
然后我们运行ss.sh文件:

可以看到生成了model.prototxt文件。那么,这个文件有多大呢?
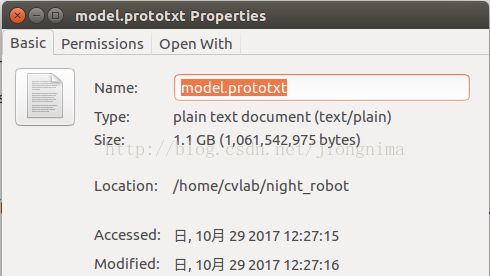
大家可以看到,该文件是相当大的,因此,强烈推荐大家使用脚本对文件进行拼接得到最终的模型文件。
可是,最终的模型文件有什么用呢?最终的模型文件将被转化为.caffemodel的模型文件并在测试程序中被调用。那么,如何将最终的.ptototxt模型文件转化为.caffemodel文件呢?预知后事如何,请看下篇分解!
总的来说,在tensorflow2caffe框架转换的过程中,本篇描述的是最难的部分,也是笔者阐述相当认真的一部分,希望能对各位读者朋友有帮助和有启发,对于博客中的疏漏,万望各位读者朋友在评论区指出,笔者不胜感激!
对于笔者的每一篇博客,笔者都是记录与阐述的科研和项目中的干货,笔者也会尽力做到常常更新,如果各位读者朋友们觉得笔者的博客对大家有帮助,订阅是欢迎的,广而告之更是欢迎的!
欢迎阅读笔者后续博客,各位读者朋友的支持与鼓励是我最大的动力!
written by jiong
功崇惟志,业广惟勤