Anchor Free,框即是点,CenterNet
目录
前沿:
Loss设计:
如何将网络预测转化为坐标框:
网络预测转化为坐标框:
网络预测转化为轮廓点:
网络结构:
2d检测任务:
姿态估计任务:
实验结果:
牛刀小试:
官方模型测试:
自己数据训练目标检测:
网络基础结构改进:
总结:
论文:Objects as Points
Github:https://github.com/xingyizhou/CenterNet
CVPR 2019
前沿:
CenterNet,一个anchor free的新的检测算法,算是对cornerNet的改进,在cornerNet基础上,引入了中心点的概念,因此,称为CenterNet。
算法亮点,
- anchor free,大大减少了anchor部分的计算量,并且不需要nms这样的后处理。
- 一个框架可以做2d检测,3d检测,pose姿态估计,3种不同的任
速度够快,速度和精度的良好平衡,在MS-COCO上28.1%的MAP,142FPS,或者,37.4%的MAP,52FPS。采用多尺度测试的话,可以达到45.1%的MAP,1.4FPS。
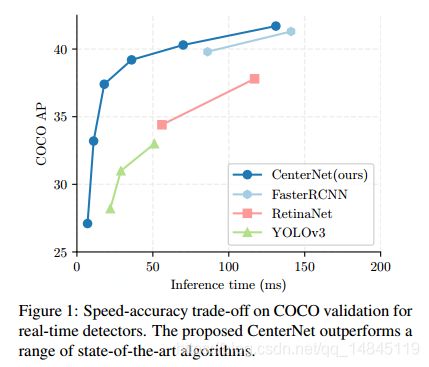
CenterNet的anchor free思想和基于anchor框架的区别:
CenterNet可以看作基于anchor框架的演变,可以看作只有一个形状的anchor。
A center point can be seenas a single shape-agnostic anchor

传统的基于anchor的思想,需要计算anchor和ground truth的IOU,IOU>0.7是正样本,IOU<0.3是负样本,其他的忽略掉。
CenterNet只取ground truh边框的中心一点作为anchor,只回归该中心点和宽,高。该点周围的其余点当作负样本。
- CenterNet只根据位置布置anchor,背部关心IOU,不需要像基于anchor的框架那样人工设置阈值来进行前景背景分类。
- 由于每一个物体只有一个正的anchor,因此不再需要后处理的NMS,只需要提取输出feature map种峰值最高的点即可。
- CenterNet的网络输出特征层尺度更大,是原图的1/4,而基于anchor的方法,最后一层特征图大小是原图的1/16,因此基于anchor的方法需要多个不同长宽比和尺度的anchor。这里为什么anchor free的方法,需要输出是原图的1/4呢?因为,大多数anchor free的方法,基本都需要下采样+上采样这样的结构,来综合底层和高层特征,才可以保证分割或者回归的准确性。
Loss设计:
输入图片大小为I (W ×H×3),其中W=H=512,
网络最后输出的特征层Y大小为,(W/R ×H/R×C),C为输出的通道数,R为输出的滑动步长,Y(x,y,c)=1表示检测到的关键点,Y(x,y,c)=0表示背景
实际训练中的groundtruth使用高斯核进行处理,核函数为,
![]()
对于一维标准高斯核函数来说,公式如下,
![]()

其中,
a表示核函数的最大值,因为e函数的指数是一个分子比分母大的函数,e函数最大就是e0=1,所以,核函数最大值就是a,也就是核函数曲线的最高点峰值坐标
b表示核函数的均值u,也就是核函数曲线的中心轴坐标
c表示核函数的方差seigema,也就是核函数曲线的宽度
二维核函数与此类比,
那么回到论文的问题,
(1)这里的高斯核函数的方差是根据图像中目标大小进行自适应确定的,不同的物体具有不同的方差。
得到的收益就是,如果这个物体大,那么经过对groundtruth进行高斯滤波后,得到的点的光圈就会比较大,反之,如果目标小,得到的点的光圈就会比较小。
而所有的groundtruth进行高斯滤波后的最高点波峰值都是1
如果两个核函数的区域相交,则分别取对应位置的最大值,而不是像传统的密度估计中那样,对所有的高斯核处理后的结果进行累加,造成波谷1+波谷2>=波峰的情况。
If two Gaussians of the same class overlap, we take the element-wise maximum [4]
(2)这里为什么需要对groundtruth进行一个高斯滤波呢?似乎很多问题都是这样的操作,包括密度估计,关键点检测等,那么这里不做可以不可以?
首先这里预测中心点的loss是一个分类的loss。也就是说预测完的每一个类别对应的feature上的点是每一个groundtruth位置内,只有一个像素比较亮,就是说,预测的特征图中只有0,1这样2种类型的整形值。而不是像groundtruth一样,是一个float类型的值,光圈中间点为1,其余周围点慢慢降低的特征图。
而好多关键点检测,deeplabcut使用的是回归,预测完就是一个float类型的特征图。而openpose也是基于回归做的,基于欧氏距离的loss,输出也是一个float类型的特征图。好多密度估计的loss也是基于回归的loss。
另一个就是所谓groundtruth的中心点,怎么就是最佳最合理的中心点呢?难度多一个像素,少一个像素就不是最佳的吗?还是人达标的框一定是最佳的真实答案呢。肯定不是这样的情况。所以这就是经过高斯核函数滤波的好处。
经过高斯滤波后,groundtruth=1的位置,会有loss传递,其他不为1的位置是一个float类型的数值,也有相应的loss传递,float类型的groundtruth的值越大,loss越大。感觉还有种soft label的思想。
而如果不经过高斯滤波,那么久会出现只有一个位置的点是groundtruth=1,其他位置都等于0。而这个点周围的其他点,都有可能是最佳的那个点。但是实际训练的时候,却都当成了0处理,这样训练完,也许效果上就会有区别吧。
(3)这里预测这个中心点,本质就是语义分割的思想。但是还有点区别,如果是语义分割的话,并且使用的是基于回归的loss,那么类别应该是C类,如果是使用的基于分类的loss,那么类别应该是C+1类,而这里是C类,那么就只能是groundtruth=0 的位置不进行loss的传递,计算loss的时候,通过对预测特征图和groundtruth进行对应位置乘积运算实现或者,支取对应的index实现。
def _slow_neg_loss(pred, gt):
'''focal loss from CornerNet'''
pos_inds = gt.eq(1)
neg_inds = gt.lt(1)
neg_weights = torch.pow(1 - gt[neg_inds], 4)
loss = 0
pos_pred = pred[pos_inds]
neg_pred = pred[neg_inds]通过这样的实现,分类的这个分支只需要C个通道就可以。从程序来说,就是写法上的区别。本质还是这个groundtruth只有0,1这2个区别,groundtruth=0的时候,如果没有背景类别这个通道,则可以通过前景类别的通道间接传递loss,如果有背景类别的通道,也不可以通过背景类别的通道传递loss。本质是一样的。主要还是因为这里的groundtruth是 one-hot形式,是hard-label,如果这里将label改为soft-label也就是说,groundtruth为0.9, 0.1这样的形式,就必须得是C+1个通道了。
plus:
假设都是用voc数据集
faster rcnn:最后的输出层分类部分的全连接层输出的个数是21。虽然faster已经先经过前面的RPN的2分类,过滤掉了大部分背景类别,但是后续仍然有可能存在背景类别。
https://github.com/ShaoqingRen/faster_rcnn
RPN:
layer {
name: "proposal_bbox_pred"
type: "Convolution"
bottom: "conv_proposal1"
top: "proposal_bbox_pred"
param {
lr_mult: 1.0
}
param {
lr_mult: 2.0
}
convolution_param{
num_output: 36 # 4 * 9(anchors)
kernel_size: 1
pad: 0
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
#-----------------------output------------------------
# to enable the calculation of softmax loss, we first reshape blobs related to SoftmaxWithLoss
layer {
bottom: "proposal_cls_score"
top: "proposal_cls_score_reshape"
name: "proposal_cls_score_reshape"
type: "Reshape"
reshape_param{
shape {
dim: 0
dim: 2
dim: -1
dim: 0
}
}
}
RCNN:
layer {
bottom: "fc7"
top: "cls_score"
name: "cls_score"
param {
lr_mult: 1.0
}
param {
lr_mult: 2.0
}
type: "InnerProduct"
inner_product_param {
num_output: 21
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "fc7"
top: "bbox_pred"
name: "bbox_pred"
type: "InnerProduct"
param {
lr_mult: 1.0
}
param {
lr_mult: 2.0
}
inner_product_param {
num_output: 84 #21*4
weight_filler {
type: "gaussian"
std: 0.001
}
bias_filler {
type: "constant"
value: 0
}
}
}SSD:分类的类别为21类,因为,使用softmax loss,肯定会有一个值最大,所以必须得加背景类别。
https://github.com/chuanqi305/MobileNet-SSD/blob/master/train.prototxt
layer {
name: "mbox_loss"
type: "MultiBoxLoss"
bottom: "mbox_loc"
bottom: "mbox_conf"
bottom: "mbox_priorbox"
bottom: "label"
top: "mbox_loss"
include {
phase: TRAIN
}
propagate_down: true
propagate_down: true
propagate_down: false
propagate_down: false
loss_param {
normalization: VALID
}
multibox_loss_param {
loc_loss_type: SMOOTH_L1
conf_loss_type: SOFTMAX
loc_weight: 1.0
num_classes: 21
share_location: true
match_type: PER_PREDICTION
overlap_threshold: 0.5
use_prior_for_matching: true
background_label_id: 0
use_difficult_gt: true
neg_pos_ratio: 3.0
neg_overlap: 0.5
code_type: CENTER_SIZE
ignore_cross_boundary_bbox: false
mining_type: MAX_NEGATIVE
}
}yolov3:20类,因为使用的是多个sigmoid来代替softmax,本质上每一个sigmoid都是前景,背景分类问题。https://github.com/pjreddie/darknet/blob/master/cfg/yolov3-voc.cfg
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=20
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
最终,中心点的loss函数为基于focal loss改进的损失函数,

α ,β是focal loss的超参数,分别取α =2,β=4,N表示一幅图像I中的点的数目
偏移offset使用L1 loss进行计算,

其中,R为网络的下采样率,
p表示所有物体中心点的groundtruth,比如中心点的,
p~表示预测的物体中心点的坐标,
2个做差后,就是预测的中心点和实际坐标点的偏移,就是需要回归的真实的偏移的groundtruth
Op~就表示预测的偏移量
问题来了,这里的offset分支,可不可以没有,没有会有什么问题产生?为什么faster RCNN没有 offset分支?
按照论文的下采样率,从输入图片到网络最后一层特征图,会进行2次下采样,也就是最后一层特征图上1个像素表示原图的4*4=16个像素。那么问题来了,这个坐标点到底对应这16个像素的哪一个,是不知道的。所以为了得到这个对应关系,这里必须得有一个offset分支。就好比ctpn,也有这个offset 分支,来对左右的边界进行精确定位。
Faster RCNN基于anchor回归得到的tx,ty,tw,th都是float类型的数值,可以对应为原图的任意一个位置,自然就不存在offset问题。而本文的CenterNet得到的框的位置是整数值,所以会有这样的问题。
物体的size使用L1 loss进行计算,
![]()

最终,整体的loss 就是中心点的loss(Lk)+物体宽高的loss(Lsize)+偏移的loss(Loff)
![]()
参数,λsize = 0:1 , λoff = 1
在推断部分,每一个类别一个输出特征图。如果一个点周围的8领域的像素都比中心该点的像素值小,则将其当作一个检测出的peak 点(该操作可以通过3*3的max pooling实现)。每一个特征图,取前100个peak点,最后通过卡阈值得到最终的结果。
对于这块的3*3 pooling,在src/lib/models/decode.py中,
def _nms(heat, kernel=3):
pad = (kernel - 1) // 2
hmax = nn.functional.max_pool2d(
heat, (kernel, kernel), stride=1, padding=pad)
keep = (hmax == heat).float()
return heat * keep其实pytorch的pooling是可以返回index的,这点就比tf的更灵活,像segnet里面,都是作者使用caffe自己实现的。
pytorch 的pooling 接口:
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)return_indices - 如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助
tensorflow的pooling 接口:
tf.nn.max_pool(
value,
ksize,
strides,
padding,
data_format='NHWC',
name=None
)并没有index返回。
实现测试,
import torch
from torch import nn
input = torch.Tensor([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16]).view(1,1,4,4)
print(input)
downsample ,index= nn.MaxPool2d(kernel_size=2, stride=2,return_indices=True)(input)
out = nn.MaxUnpool2d(kernel_size =2, stride=2)(downsample,index)
print(out)
“””
tensor([[[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]])
tensor([[[[ 0., 0., 0., 0.],
[ 0., 6., 0., 8.],
[ 0., 0., 0., 0.],
[ 0., 14., 0., 16.]]]])
“””
这里为什么需要一个3*3的max pooling,这里个人理解,其实就是很类似NMS的一个操作。本质出现这个问题,还是因为中心点的最佳位置不是可以确切肯定的。这样就可以去掉框上累加框的情况。但是这个思想,本质也没有解决高遮挡的高IOU目标检测问题。NMS没解决这个问题,3*3的max pooling也么有解决。
但是centerNet由于自身下采样次数少,所以高IOU问题影响较少,只有0.1%,而基于anchor思想的却有大约2%的影响。faster RCNN在iou 0.5的阈值下,有20%的高遮挡问题。
CenterNet is unable to predict < 0:1% of objects due to collisions in center points. This is much less than slow- or fastRCNN miss due to imperfect region proposals [52] (∼ 2%),and fewer than anchor-based methods miss due to insufficient anchor placement [46] (20:0% for Faster-RCNN with15 anchors at 0:5 IOU threshold). In addition, 715 pairs of objects have bounding box IoU > 0:7 and would beassigned to two anchors, hence a center-based assignment causes fewer collisions.
如果是需要mul scale的推断的话,每一个scale输出的结果就需要通过NMS的融合。如果只是单一scale做推断,就不需要NMS操作。
For multi-scale, we use NMS to merge results
如何将网络预测转化为坐标框:
网络预测转化为坐标框:

其中,(xi,yi)表示预测的中心点x,y坐标。
(δxi; δyi) = Oxi;yi,表示预测的中心点坐标x,y的偏移
( wi; hi) = Sxi;yi,表示物体框的大小宽度和高度。

通过中心点坐标加上中心点坐标在x,y两个方向的偏移量,得到准确的中心点坐标。然后使用中心点坐标分别减去宽,高的一半,即得到人体目标框的左上角坐标点(x1,y1)和右下角坐标点(x2,y2)。
网络预测转化为轮廓点:
使用下面的公式转化为最终的关键点坐标
![]()
其中,(x,y)表示目标物体中心点的坐标,即hm分支。Jxyj表示第j个点的(x,y)坐标的偏移量,即hps分支。但是这样的基于直接回归的方式预测的关键点坐标的误差是相对较大的。
![]()
因此,这里使用一个技巧,即根据直接回归可以确定出每一个轮廓点的大致位置,然后找这个位置附近的置信度大于0.1的权值最大的那个点Lj(hm_hp),将其作为真正的轮廓点。然后使用该点加上偏移(hp_offset)得到最终的轮廓点的坐标。
Lj = hm_hp+hp_offset
![]()
网络结构:

(a)沙漏(HourGlass)网络结构
(b)ResNet结构+反卷积
(c)原生的DLA-34结构
(d)本文基于DLA-34,修改后的结构,增加了skip connections。
模型效果:Hourglass > DLA > Resnet
网络输入为512*512,输出为128*128,网络中使用的卷积conv是可变形卷积DeformConv,可变形卷积对性能的提升还是很明显的。
可变形卷积的使用感触:
(1)参数量相比正常卷积大
(2)计算量比正常卷积大,速度能慢出近1半来。
(3)效果提升非常明显,loss下降的可以更低。
(4)DCNv2还加入了卷积像素的加权,类似attention,效果更好。
(5)缺点,pytorch并不原生支持。
数据增强方式包括,random flip, random scaling (0.6-1.3), cropping, color jittering
网络的基础结构可以采用,ResNet-18, ResNet-101, DLA-34, Hourglass-104,在这些基础结构的基础上进行了下面2个修改,
- 增加可变形卷积(deformable convolution)
- 增加反卷积,采用沙漏结构(Hourglass)

CenterNet模型可以适用于传统的2d目标检测,3d目标检测,姿态估计,等3个任务,不同的任务,最终的模型输出层略有区别。
2d检测任务:
输出3个分支,分别是,
- 物体的特征图,一个类别一个channel,包含C个channel。
- 物体中心点的偏移,包含x,y两个偏移量,因此是2个channel。
- 物体的大小,也就是宽,高,因此也是2个channel。
最终网络输出,C+4个预测分支。
姿态估计任务:

这里我的训练任务的pose关键点有5个。
输出6个分支,分别是,
- hm,128*128*C,物体的特征图,一个类别一个channel,包含C个channel。
- reg,128*128*2,物体中心点的偏移,包含x,y两个偏移量,因此是2个channel。
- wh,128*128*2,物体的大小,也就是宽,高,因此也是2个channel。
- hps,128*128*k*2,基于回归的思想Coordinate,物体的关键点基于中心点的偏移,输出k*2个通道,k表示关键点的数目,2表示x,y两个偏移。
- hm_hp,128*128*k,基于Heatmap分割的思想,得到的物体关键点的特征图,输出k个通道,一个点一个通道。
- hp_offset,128*128*2,K个关键点的偏移,所有这些关键点采用同样的偏移量,x,y两个指标,输出2个通道。
关键点回归的Ground Truth 的构建问题,主要有两种思路, Coordinate 和 Heatmap,Coordinate 即直接将关键点坐标作为最后网络需要回归的目标,这种情况下可以直接得到每个坐标点的直接位置信息; Heatmap 即将每一类坐标用一个概率图来表示,对图片中的每个像素位置都给一个概率,表示该点属于对应类别关键点的概率, 比较自然的是,距离关键点位置越近的像素点的概率越接近 1,距离关键点越远的像素点的概率越接近 0,具体可以通过相应函数进行模拟,如Gaussian 等。
Coordinate 的优点是参数量少,缺点是效果较差,容易训练学习。
Heatmap 的优点是容易训练,准确性高,缺点是参数量大,随着要检测的点的个数呈爆炸性增长。
实际使用的时候,基于回归预测的点的坐标(4),肯定是没有基于分割思路预测的点的坐标(5)准确。所以,实际使用的时候,使用一个物体框内部,离得回归的点最近的分割的点作为最终预测的点。
We then assign each regressed location lj to its closest detected keypoint arg minl2Lj (l - lj)2 considering only joint
detections within the bounding box of the detected object
实验结果:
不同基础网络结构对比,

COCO数据集2d检测结果对比,

KITTI 3d检测结果对比,

COCO pose检测结果对比,

cuda9.0,pytorch0.4.1可能安装错误:
(1)RuntimeError: cuDNN version mismatch: PyTorch was compiled against 7102 but linked against 7301
解决办法:conda install cudnn=7.1.2
(2)skipping 'pycocotools/_mask.c' Cython extension (up-to-date)
building 'pycocotools._mask' extension
x86_64-conda_cos6-linux-gnu-gcc -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -fwrapv -O2 -Wall -Wstrict-prototypes -march=nocona -mtune=haswell -ftree-vectorize -fPIC -fstack-protector-strong -fno-plt -O2 -pipe -march=nocona -mtune=haswell -ftree-vectorize -fPIC -fstack-protector-strong -fno-plt -O2 -pipe -fPIC -I/home/jiangxiaolong/Anaconda3/lib/python3.6/site-packages/numpy/core/include -I../common -I/home/jiangxiaolong/Anaconda3/include/python3.6m -c ../common/maskApi.c -o build/temp.linux-x86_64-3.6/../common/maskApi.o -Wno-cpp -Wno-unused-function -std=c99
unable to execute 'x86_64-conda_cos6-linux-gnu-gcc': No such file or directory
error: command 'x86_64-conda_cos6-linux-gnu-gcc' failed with exit status 1
make: *** [all] 错误 1
解决办法:conda install gxx_linux-64
cuda10.0,pytorch1.0.0可能安装错误:
安装pytorch:
pip3 install -U https://download.pytorch.org/whl/cu100/torch-1.0.0-cp36-cp36m-linux_x86_64.whl安装可变形卷积:
cd src/lib/models/networks
rm -rf DCNv2
git clone https://github.com/CharlesShang/DCNv2.git
cd DCNv2
./make.sh # build
python3 testcpu.py # run examples and gradient check on cpu
python3 testcuda.py
自测pytorch0.4.1&torchvision0.2.1,pytorch1.0.0&torchvision0.2.1,pytorch1.4.0&torchvision0.5.0都可以进行训练和测试。
牛刀小试:
官方模型测试:
目标检测
python demo.py ctdet --demo /path/to/image/or/folder/or/video --load_model ../models/ctdet_coco_dla_2x.pth关键点检测:
python demo.py multi_pose --demo /path/to/image/or/folder/or/video/or/webcam --load_model ../models/multi_pose_dla_3x.pth官方模型训练:
目标检测:
python main.py ctdet --exp_id coco_dla --arch dla_34 --batch_size 32 --master_batch 15 --lr 1.25e-4 --gpus 3,4 --load_model ../models/ctdet_coco_dla_2x.pth --resume关键点检测:
python main.py multi_pose --exp_id dla_3x --dataset coco_hp --batch_size 16 --master_batch 2 --lr 5e-4 --load_model ../models/multi_pose_dla_3x.pth --gpus 3,4 --num_workers 2 --num_epochs 320 --lr_step 270,300
自己数据训练目标检测:
比如最近很火的kesci大赛,水下目标检测算法赛(2020年全国水下机器人(湛江)大赛),https://www.kesci.com/home/competition/5e535a612537a0002ca864ac
下载大赛数据集,然后进行xml转化为coco的json格式,
import os
import cv2
import json
import xml.dom.minidom
import xml.etree.ElementTree as ET
data_dir = './train' #根目录文件,其中包含image文件夹和box文件夹(根据自己的情况修改这个路径)
image_file_dir = os.path.join(data_dir, 'image')
xml_file_dir = os.path.join(data_dir, 'box')
annotations_info = {'images': [], 'annotations': [], 'categories': []}
categories_map = {'holothurian': 1, 'echinus': 2, 'scallop': 3, 'starfish': 4}
for key in categories_map:
categoriy_info = {"id":categories_map[key], "name":key}
annotations_info['categories'].append(categoriy_info)
file_names = [image_file_name.split('.')[0]
for image_file_name in os.listdir(image_file_dir)]
ann_id = 1
for i, file_name in enumerate(file_names):
image_file_name = file_name + '.jpg'
xml_file_name = file_name + '.xml'
image_file_path = os.path.join(image_file_dir, image_file_name)
xml_file_path = os.path.join(xml_file_dir, xml_file_name)
image_info = dict()
image = cv2.cvtColor(cv2.imread(image_file_path), cv2.COLOR_BGR2RGB)
height, width, _ = image.shape
image_info = {'file_name': image_file_name, 'id': i+1,
'height': height, 'width': width}
annotations_info['images'].append(image_info)
DOMTree = xml.dom.minidom.parse(xml_file_path)
collection = DOMTree.documentElement
names = collection.getElementsByTagName('name')
names = [name.firstChild.data for name in names]
xmins = collection.getElementsByTagName('xmin')
xmins = [xmin.firstChild.data for xmin in xmins]
ymins = collection.getElementsByTagName('ymin')
ymins = [ymin.firstChild.data for ymin in ymins]
xmaxs = collection.getElementsByTagName('xmax')
xmaxs = [xmax.firstChild.data for xmax in xmaxs]
ymaxs = collection.getElementsByTagName('ymax')
ymaxs = [ymax.firstChild.data for ymax in ymaxs]
object_num = len(names)
for j in range(object_num):
if names[j] in categories_map:
image_id = i + 1
x1,y1,x2,y2 = int(xmins[j]),int(ymins[j]),int(xmaxs[j]),int(ymaxs[j])
x1,y1,x2,y2 = x1 - 1,y1 - 1,x2 - 1,y2 - 1
if x2 == width:
x2 -= 1
if y2 == height:
y2 -= 1
x,y = x1,y1
w,h = x2 - x1 + 1,y2 - y1 + 1
category_id = categories_map[names[j]]
area = w * h
annotation_info = {"id": ann_id, "image_id":image_id, "bbox":[x, y, w, h], "category_id": category_id, "area": area,"iscrowd": 0}
annotations_info['annotations'].append(annotation_info)
ann_id += 1
with open('./annotations.json', 'w') as f:
json.dump(annotations_info, f, indent=4)
print('---整理后的标注文件---')
print('所有图片的数量:', len(annotations_info['images']))
print('所有标注的数量:', len(annotations_info['annotations']))
print('所有类别的数量:', len(annotations_info['categories']))程序修改:
src/lib/opts.py
'ctdet': {'default_resolution': [512, 512], 'num_classes': 80修改为:
'ctdet': {'default_resolution': [512, 512], 'num_classes': 4,因为这个训练集只有4个类别,
lib/datasets/dataset/coco.py,进行下面的修改,
def __init__(self, opt, split):
super(COCO, self).__init__()
#self.data_dir = os.path.join(opt.data_dir, 'coco')
#self.img_dir = os.path.join(self.data_dir, '{}2017'.format(split))
self.data_dir = os.path.join(opt.data_dir, 'kesci')
self.img_dir = os.path.join(self.data_dir, '{}'.format(split))
if split == 'test':
#self.annot_path = os.path.join(
# self.data_dir, 'annotations',
# 'image_info_test-dev2017.json').format(split)
self.annot_path = os.path.join(self.data_dir,"annotations/annotations_test.json")
else:
if opt.task == 'exdet':
#self.annot_path = os.path.join(
# self.data_dir, 'annotations',
# 'instances_extreme_{}2017.json').format(split)
self.annot_path = os.path.join(self.data_dir,"annotations/annotations_val.json")
else:
self.annot_path = os.path.join(self.data_dir,"annotations/annotations_train.json")
#self.annot_path = os.path.join(
# self.data_dir, 'annotations',
# 'instances_{}2017.json').format(split)
self.max_objs = 128
self.class_name = ['__background__','holothurian', 'echinus', 'scallop' ,'starfish']
#self.class_name = [
# '__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
# 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
# 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse',
# 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack',
# 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis',
# 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
# 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass',
# 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
# 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake',
# 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv',
# 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
# 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
# 'scissors', 'teddy bear', 'hair drier', 'toothbrush']然后开始训练,
python main.py ctdet --exp_id coco_dla --arch dla_34 --batch_size 32 --master_batch 15 --lr 1.25e-4 --gpus 3,4 --load_model ../models/ctdet_coco_dla_2x.pth --resumeloss下降还是挺快的,v100 2卡,有30分钟就可以看结果了,

模型保存在,../exp/ctdet/coco_dla/,训练完成后,进行测试,
python demo.py ctdet --demo ../image_kesci --load_model ../exp/ctdet/coco_dla/model_best.pth --gpus 5
自己数据训练关键点检测:
程序修改,整个程序写的扩展性很差,修改的地方相对比较多,只要是涉及到类别数目的地方,涉及到点的个数的地方,都需要修改,
包括,
src/lib/opts.py
src/lib/datasets/dataset/coco_hp.py
src/lib/datasets/sample/multi_pose.py
src/lib/detectors/multi_pose.py
src/lib/utils/debugger.py
src/lib/utils/post_process.py
src/lib/models/utils.py
总之改完后,哪里有错误,就改哪里,最好定义变量num_classes ,num_keypoints ,实现一改全改。
训练指令,
python main.py multi_pose --arch dla_34 --exp_id dla_3x --dataset coco_hp --batch_size 16 --master_batch 2 --lr 5e-4 --load_model ../models/multi_pose_dla_3x.pth --gpus 3,4 --num_workers 2 --num_epochs 320 --lr_step 270,300loss下降还是挺快的,v100 2卡,有30分钟就可以看结果了,

测试效果,
python demo.py multi_pose --arch dla_34 --load_model ../exp/multi_pose/dla_3x/model_best.pth --demo ../image_fish --gpus 5
网络基础结构改进:
使用EfficientNet基础结构替换DLA网络结构,可以实现精度和速度的双重平衡。

总结:
(1)简单,快速,准确。
(2)anchor free领域新的里程碑
(3)一个框架,同时兼顾2d检测,3d检测,姿态估计
(4)实际训练中,对于两个物体中心点重叠的情况,CenterNet无能无力,只能将2个点,也就是2个物体,当作一个物体,一个点来处理。同理,测试的时候,对于两个遮挡的中心点重合的物体,也只能检测出一个中心点。
(5) CenterNet的头部分类分支,会随着类别数目增加而爆炸性增长问题,这块会是一个比较大的参数量。而face++的子弹头检测网络这方面就做的很好。
(6)可变形卷积在移动端的不支持,替代为传统卷积,精度会降低。
(7)CenterNet相比于CornerNet,更像是将左上角点和右下角点的回归修改为,一个中心点和宽高的回归,从而不再需要corner pooling,不需要左上角点和右下角点的配对问题,不再需要后处理的NMS。
CenterNet相比于有anchor的检测框架,本质上都是回归中心点和宽高,这点本质没变。虽然centerNet的下采样率较小,如果部anchor的话,应该布的更多才对。但是,centerNet在时间训练的时候,只有groundtruth位置的中心点才被当成类似anchor的思路处理。这样就大大的减少了anchor的数目,只需要一个anchor就可以,也就从本质上省去了NMS后处理操作。
其实认真一思考,其实本质上,也许就该是CenterNet这样的思想来做。至于为啥没有,也许可能从最开始的机器学习中滑动窗口的过渡,需要延续这样的思想了。人的思想也许很难有如此大跨度的升华。
(8) CenterNet为了使用基于heatmap的关键点替代基于回归的关键点,直接取了离回归的点最近的heatmap的点。如果所训练的点和点直接的距离较大,这样做无所谓。但是如果,训练的点和点之间的距离较小,这样就会使得预测的2个不同的点都使用同一个heatmap的点。所以,如果点点之间距离较小,使用该方法就得慎重。