Yolo-V3 关于负数据的引入
负数据的引入
想要引入负数据,使网络具有更好的鲁棒性,我们首先需要明确的是如何计算Loss,然后再将负数据在网络中的效果添加到Loss计算中
Loss
首先明确,网络中含训练集和测试集,具体是图片与归一化之后的数据(存放于特定的txt文件中)。
1. 读取数据
读取数据的函数位于datasets.py中:
def __init__(self, list_path, img_size=416, augment=True, multiscale=True, normalized_labels=True):
with open(list_path, "r") as file:
self.img_files = file.readlines()
self.label_files = [
path.replace("images", "labels").replace(".png", ".txt").replace(".jpg", ".txt")
for path in self.img_files
]
self.img_size = img_size
self.max_objects = 100
self.augment = augment
self.multiscale = multiscale
self.normalized_labels = normalized_labels
self.min_size = self.img_size - 3 * 32
self.max_size = self.img_size + 3 * 32
self.batch_count = 0
读取数据之后,将图片修改为符合网络训练的规格:`
def __getitem__(self, index):
#获取图片路径
img_path = self.img_files[index % len(self.img_files)].rstrip()
img = cv2.imread(img_path)
#print(img_path)
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
label_path = self.label_files[index % len(self.img_files)].rstrip()
if os.path.exists(label_path):
boxes = np.loadtxt(label_path).reshape(-1, 5)
else:
target = None
img = transforms.ToTensor()(img)
return img_path, img, targets
if self.augment:
if np.random.random() < 0.5:
#获取图片pad之前的长宽
w, h = img.size
w_factor, h_factor = (w, h) if self.normalized_labels else (1, 1)
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)
y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2)
x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)
y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2)
xMin = np.min(x1)
yMin = np.min(y1)
xMax = np.max(x2)
yMax = np.max(y2)
left = random.uniform(0, max(0, xMin-0.1*w))
top = random.uniform(0, max(0, yMin-0.1*h))
right = random.uniform(min(w, xMax+0.1*w), w)
bottom = random.uniform(min(h, yMax+0.1*h), h)
#裁剪之后的图像
img = img.crop((left, top, right, bottom))
#裁剪后新边长
new_w = right - left
new_h = bottom - top
#boxes1代替原来的boxes1
boxes[:, 1] = (w_factor * boxes[:, 1] - left) / new_w
boxes[:, 2] = (h_factor * boxes[:, 2] - top) / new_h
boxes[:, 3] = w_factor * boxes[:, 3] / new_w
boxes[:, 4] = h_factor * boxes[:, 4] / new_h
else:
pass
img = transforms.ToTensor()(img)
boxes = torch.from_numpy(boxes)
# Handle images with less than three channels
if len(img.shape) != 3:
img = img.unsqueeze(0)
img = img.expand((3, img.shape[1:]))
_, h, w = img.shape
h_factor, w_factor = (h, w) if self.normalized_labels else (1, 1)
# Pad to square resolution
img, pad = pad_to_square(img, 0)
_, padded_h, padded_w = img.shape
# Extract coordinates for unpadded + unscaled image
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)
y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2)
x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)
y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2)
# Adjust for added padding
x1 += pad[0]
y1 += pad[2]
x2 += pad[1]
y2 += pad[3]
# Returns (x, y, w, h)
boxes[:, 1] = ((x1 + x2) / 2) / padded_w
boxes[:, 2] = ((y1 + y2) / 2) / padded_h
boxes[:, 3] *= w_factor / padded_w
boxes[:, 4] *= h_factor / padded_h
targets = torch.zeros((len(boxes), 6))
targets[:, 1:] = boxes
return img_path, img, targets
可见最后return的是图像路径,图像与targets,所谓targets就是最后和网络训练结果对比的标准答案。
2. 了解数据在哪里输出,找到print出Loss的位置从而确定Loss如何计算
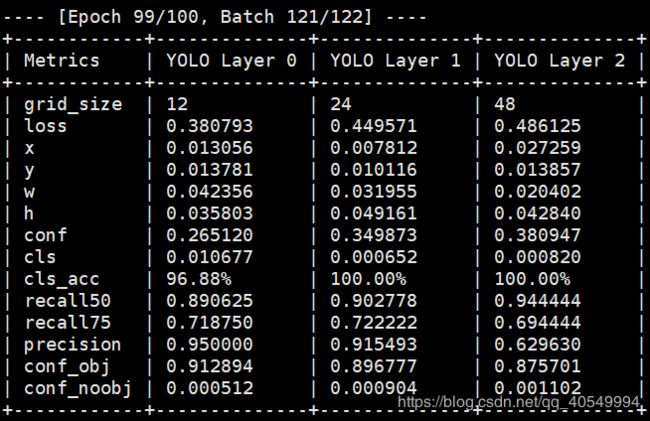
在train.py中找到了将网络训练的数据以表格的形式print出的语句,但是很可惜这并不能告诉我们怎么计算。
log_str = "\n---- [Epoch %d/%d, Batch %d/%d] ----\n" % (epoch, opt.epochs, batch_i, len(dataloader))
metric_table = [["Metrics", *[f"YOLO Layer {i}" for i in range(len(model.yolo_layers))]]]
最后在Xshell中输出的形式如图所示:
3. 网络具体结构
在输出的语句中我们发现,Loss值是作为model.yolo_layers的参数输出的,既然我们没有办法直接得到具体的数学计算公式,那我们就去看网络结构,看看这个yolo_layers长什么样。
在model.py的class - YOLOLayer中,找到了网络结构的定义。
class YOLOLayer(nn.Module):
init
def __init__(self, anchors, num_classes, img_dim=416):
super(YOLOLayer, self).__init__()
self.anchors = anchors
self.num_anchors = len(anchors)
self.num_classes = num_classes
self.ignore_thres = 0.5
self.mse_loss = nn.MSELoss()
self.bce_loss = nn.BCELoss()
self.obj_scale = 1
self.noobj_scale = 100
self.metrics = {}
self.img_dim = img_dim
self.grid_size = 0 # grid size
init中主要是定义了后面要用到的一些参数。
compute_grid_offsets
def compute_grid_offsets(self, grid_size, cuda=True):
self.grid_size = grid_size
g = self.grid_size
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
self.stride = self.img_dim / self.grid_size
# Calculate offsets for each grid
self.grid_x = torch.arange(g).repeat(g, 1).view([1, 1, g, g]).type(FloatTensor)
self.grid_y = torch.arange(g).repeat(g, 1).t().view([1, 1, g, g]).type(FloatTensor)
self.scaled_anchors = FloatTensor([(a_w / self.stride, a_h / self.stride) for a_w, a_h in self.anchors])
self.anchor_w = self.scaled_anchors[:, 0:1].view((1, self.num_anchors, 1, 1))
self.anchor_h = self.scaled_anchors[:, 1:2].view((1, self.num_anchors, 1, 1))
forward
def forward(self, x, targets=None, img_dim=None):
定义数据类型
# Tensors for cuda support
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
ByteTensor = torch.cuda.ByteTensor if x.is_cuda else torch.ByteTensor
定义预测值
prediction = (
x.view(num_samples, self.num_anchors, self.num_classes + 5, grid_size, grid_size)
.permute(0, 1, 3, 4, 2)
.contiguous()
)
x.view中view的作用是把原先tensor中的数据按照行优先的顺序排成一个一维的数据(这里应该是因为要求地址是连续存储的),然后按照参数组合成其他维度的tensor。比如说是不管你原先的数据是[[[1,2,3],[4,5,6]]]还是[1,2,3,4,5,6],因为它们排成一维向量都是6个元素,所以只要view后面的参数一致。
permute(0, 1, 3, 4, 2)的作用简而言之就是将tensor的维度换位。
contiguous: transpose、permute等维度变换操作后,tensor在内存中不再是连续存储的,而view操作要求tensor的内存连续存储,所以需要contiguous来返回一个contiguous copy contiguous-知乎
获取输出
# Get outputs
x = torch.sigmoid(prediction[..., 0]) # Center x
y = torch.sigmoid(prediction[..., 1]) # Center y
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
pred_conf = torch.sigmoid(prediction[..., 4]) # Conf
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
torch.sigmoid为激活函数Sigmoid,具体公式在Pytorch官方文档中有。Pytorch.nn
将prediction中数据作处理后放入output中
# Add offset and scale with anchors
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x.data + self.grid_x
pred_boxes[..., 1] = y.data + self.grid_y
pred_boxes[..., 2] = torch.exp(w.data) * self.anchor_w
pred_boxes[..., 3] = torch.exp(h.data) * self.anchor_h
output = torch.cat(
(
pred_boxes.view(num_samples, -1, 4) * self.stride,
pred_conf.view(num_samples, -1, 1),
pred_cls.view(num_samples, -1, self.num_classes),
),
-1,
)
获取targets
if targets is None:
return output, 0
else:
iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf = build_targets(
pred_boxes=pred_boxes,
pred_cls=pred_cls,
target=targets,
anchors=self.scaled_anchors,
ignore_thres=self.ignore_thres,
)
其中的build_targets位于utils.py中,等会再说。
计算所有的loss
# Loss : Mask outputs to ignore non-existing objects (except with conf. loss)
loss_x = self.mse_loss(x[obj_mask], tx[obj_mask])
loss_y = self.mse_loss(y[obj_mask], ty[obj_mask])
loss_w = self.mse_loss(w[obj_mask], tw[obj_mask])
loss_h = self.mse_loss(h[obj_mask], th[obj_mask])
loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask])
loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask])
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj
loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask])
total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls
# Metrics
cls_acc = 100 * class_mask[obj_mask].mean()
conf_obj = pred_conf[obj_mask].mean()
conf_noobj = pred_conf[noobj_mask].mean()
conf50 = (pred_conf > 0.5).float()
iou50 = (iou_scores > 0.5).float()
iou75 = (iou_scores > 0.75).float()
detected_mask = conf50 * class_mask * tconf
precision = torch.sum(iou50 * detected_mask) / (conf50.sum() + 1e-16)
recall50 = torch.sum(iou50 * detected_mask) / (obj_mask.sum() + 1e-16)
recall75 = torch.sum(iou75 * detected_mask) / (obj_mask.sum() + 1e-16)
将结果放入self.metrics中
self.metrics = {
"loss": to_cpu(total_loss).item(),
"x": to_cpu(loss_x).item(),
"y": to_cpu(loss_y).item(),
"w": to_cpu(loss_w).item(),
"h": to_cpu(loss_h).item(),
"conf": to_cpu(loss_conf).item(),
"cls": to_cpu(loss_cls).item(),
"cls_acc": to_cpu(cls_acc).item(),
"recall50": to_cpu(recall50).item(),
"recall75": to_cpu(recall75).item(),
"precision": to_cpu(precision).item(),
"conf_obj": to_cpu(conf_obj).item(),
"conf_noobj": to_cpu(conf_noobj).item(),
"grid_size": grid_size,
}
返回out,total_loss
return output, total_loss
现在,回到前面看bulid_targets是如何操作的:
def build_targets(pred_boxes, pred_cls, target, anchors, ignore_thres):
定义数据类型
ByteTensor = torch.cuda.ByteTensor if pred_boxes.is_cuda else torch.ByteTensor
FloatTensor = torch.cuda.FloatTensor if pred_boxes.is_cuda else torch.FloatTensor
获取x, y ,w, cls的大小,并以此创建Tensor放置target数据
nB = pred_boxes.size(0)
nA = pred_boxes.size(1)
nC = pred_cls.size(-1)
nG = pred_boxes.size(2)
# Output tensors
obj_mask = ByteTensor(nB, nA, nG, nG).fill_(0)
noobj_mask = ByteTensor(nB, nA, nG, nG).fill_(1)
class_mask = FloatTensor(nB, nA, nG, nG).fill_(0)
iou_scores = FloatTensor(nB, nA, nG, nG).fill_(0)
tx = FloatTensor(nB, nA, nG, nG).fill_(0)
ty = FloatTensor(nB, nA, nG, nG).fill_(0)
tw = FloatTensor(nB, nA, nG, nG).fill_(0)
th = FloatTensor(nB, nA, nG, nG).fill_(0)
tcls = FloatTensor(nB, nA, nG, nG, nC).fill_(0)
将x, y, w, h的数据放于gxy与gwh中
# Convert to position relative to box
target_boxes = target[:, 2:6] * nG
gxy = target_boxes[:, :2]
gwh = target_boxes[:, 2:]
与anchor进行比较后,用并集 / 交集后得到ious,求得最大值
# Get anchors with best iou
ious = torch.stack([bbox_wh_iou(anchor, gwh) for anchor in anchors])
best_ious, best_n = ious.max(0)
torch.stack作用是将维度结合,这里有三中类型的anchor,所以stack将三个一维的tensor结合成二维
ious.max(0)的作用是取出ious中每列的最大值
-
min(0)返回该矩阵中每一列的最小值
-
min(1)返回该矩阵中每一行的最小值
-
max(0)返回该矩阵中每一列的最大值
-
max(1)返回该矩阵中每一行的最大值
将target中的值拿出来
# Separate target valueshuo
b, target_labels = target[:, :2].long().t()
gx, gy = gxy.t()
gw, gh = gwh.t()
gi, gj = gxy.long().t()
# Set masks
obj_mask[b, best_n, gj, gi] = 1
noobj_mask[b, best_n, gj, gi] = 0
计算各种用于计算Loss的target值
# Coordinates
tx[b, best_n, gj, gi] = gx - gx.floor()
ty[b, best_n, gj, gi] = gy - gy.floor()
# Width and height
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16)
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16)
# One-hot encoding of label
tcls[b, best_n, gj, gi, target_labels] = 1
# Compute label correctness and iou at best anchor
class_mask[b, best_n, gj, gi] = (pred_cls[b, best_n, gj, gi].argmax(-1) == target_labels).float()
iou_scores[b, best_n, gj, gi] = bbox_iou(pred_boxes[b, best_n, gj, gi], target_boxes, x1y1x2y2=False)
tconf = obj_mask.float()
返回所有test值
return iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf
4. 理清如何去添加
首先,在bulid_targets中引入的target数据是原始的,我们在labelImg2上标记并归一化了的数据,在models中的prediction是网络训练出来的结果,最后的loss值是由loss_x = self.mse_loss(x[obj_mask], tx[obj_mask]) 这种形式计算的。
5. 最后解决方案
看最后loss中的代码不难看出,所有的计算都与坐标[b, best_n, gj, gi]有关,而此坐标最关键的是与obj_mask和noobj_mask息息相关。obj_mask[] = 1表示检测出物体,noobj_mask[] = 1表示没有检测出物体。
# Set masks
obj_mask[b, best_n, gj, gi] = 1
noobj_mask[b, best_n, gj, gi] = 0
引入负数据,首先将图片路径放入train.txt中,然后将归一化之后的txt文件与之前的训练txt放在一起。但是我们知道,负数据是没有相关特征的,我们不对其作标注,直接在其各自的txt文件中全部加0。然后在以上代码下加两行,表面如果检测到tx,ty = 0的话,将noobj_mask置为1,将obj_mask置为0。这就相当于告诉了网络,即使网络认为,这个负数据中存在特征,但是如果他的label没有描述,网络就算是判断错误。最后是否成功,就要看网络最后的实际效果和出来的loss值了。但是由于此次训练,是只检测一个label也就是card,所以说loss值经过几个epoch之后就非常高,看loss意义就不大了。
# 如果是全0的label,即anchor_ious为0,则将obj mask设为0,noobj mask设为1
obj_mask[b[i], anchor_ious == 0., gj[i], gi[i]] = 0
noobj_mask[b[i], anchor_ious == 0., gj[i], gi[i]] = 1
最后问题得以解决,此文告一段落。