mysql:select实践和总结
原文链接:https://zhuanlan.zhihu.com/p/50662216
这里重现原文部分内容,问题编号一致,select语句不完全一致,目的是根据查询需求梳理select语句编写思路,总结一般性方法,不探讨语法细节。下面先给出一些总结出的经验,之后再建表、建立需求场景练习select。
经验来自实践,可能存在疏漏,请赐教。
经验总结
子句执行顺序
from —> where —> group by —> having —> order by—> select —> limit —>结果。
别名
会用到别名的地方:
调用子查询结果(后文问题7,写法四),必须有别名;
查询结果重命名(后文问题3),可选;
多表连接使用别名代替原表名(后文问题1,写法二),可简化书写内容,可选;但一张表自连接时,必须有别名;
限定where子句条件判断范围(后文问题10,写法二),可选;
别名使用规则:
别名唯一,否则程序无法判断;
遵循子句查询顺序,必须先有别名,才能被使用;
集合运算
1、并集:union,有重复则保留一条记录;union all,不去重;
2、交集:在A也在B; 语法:sth in A and sth in B;
3、差集:若A为空,B为空或非空,则A-B为空;
若A非空,B>=A,则A-B为空;
若A非空,B
集合运算的结果可以是最终的筛选目标;也可以搭配exists使用,根据是否为空在where子句作True或False。
除了使用in或not in进行集合运算,还可以使用union all 配合group by…having count(…)为1或2做集合运算,
由于union all求和不去重,故count(…)=2表示交集;
当两个集合除了交集之外,还各自有元素,则count(…)=1表示union all后count(…)=2部分的补集,而非差集;
当一个集合是另一个集合的父集时,count(…)=1表示差集;(问题5,写法三)
待积累更多实践经验后,再比较使用in或not in 与 union all的差别。
group by 后的select子句
group by 后,select后只能跟作分组键的列、与分组键一一对应(不能一对多)的列、常数(后文问题19,写法一、二)、聚合函数。
case…when
可用于将同一列内容根据不同条件,放到多列(后文问题17)。
建表
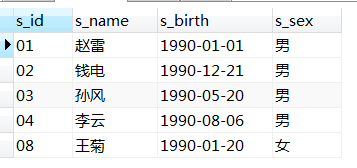
--学生表
CREATE TABLE `student`(
`s_id` VARCHAR(20),
`s_name` VARCHAR(20) NOT NULL DEFAULT '',
`s_birth` VARCHAR(20) NOT NULL DEFAULT '',
`s_sex` VARCHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY(`s_id`)
);
--课程表
CREATE TABLE `course`(
`c_id` VARCHAR(20),
`c_name` VARCHAR(20) NOT NULL DEFAULT '',
`t_id` VARCHAR(20) NOT NULL,
PRIMARY KEY(`c_id`)
);
--教师表
CREATE TABLE `teacher`(
`t_id` VARCHAR(20),
`t_name` VARCHAR(20) NOT NULL DEFAULT '',
PRIMARY KEY(`t_id`)
);
--成绩表
CREATE TABLE `score`(
`s_id` VARCHAR(20),
`c_id` VARCHAR(20),
`s_score` INT(3),
PRIMARY KEY(`s_id`,`c_id`)
);
--插入学生表测试数据
insert into student values('01' , '赵雷' , '1990-01-01' , '男');
insert into student values('02' , '钱电' , '1990-12-21' , '男');
insert into student values('03' , '孙风' , '1990-05-20' , '男');
insert into student values('04' , '李云' , '1990-08-06' , '男');
insert into student values('05' , '周梅' , '1991-12-01' , '女');
insert into student values('06' , '吴兰' , '1992-03-01' , '女');
insert into student values('07' , '郑竹' , '1989-07-01' , '女');
insert into student values('08' , '王菊' , '1990-01-20' , '女');
--课程表测试数据
insert into course values('01' , '语文' , '02');
insert into course values('02' , '数学' , '01');
insert into course values('03' , '英语' , '03');
--教师表测试数据
insert into teacher values('01' , '张三');
insert into teacher values('02' , '李四');
insert into teacher values('03' , '王五');
--成绩表测试数据
insert into score values('01' , '01' , 80);
insert into score values('01' , '02' , 90);
insert into score values('01' , '03' , 99);
insert into score values('02' , '01' , 70);
insert into score values('02' , '02' , 60);
insert into score values('02' , '03' , 80);
insert into score values('03' , '01' , 80);
insert into score values('03' , '02' , 80);
insert into score values('03' , '03' , 80);
insert into score values('04' , '01' , 50);
insert into score values('04' , '02' , 30);
insert into score values('04' , '03' , 20);
insert into score values('05' , '01' , 76);
insert into score values('05' , '02' , 87);
insert into score values('06' , '01' , 31);
insert into score values('06' , '03' , 34);
insert into score values('07' , '02' , 89);
insert into score values('07' , '03' , 98);
需求场景
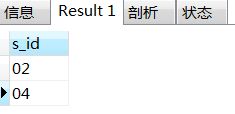
1、查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号。
--写法一:查找s_id,条件为该s_id的课程01分数高于课程02分数
select distinct s_id
from score as s
where (select s_score from score as s01 where s01.s_id=s.s_id and s01.c_id='01')
>
(select s_score from score as s02 where s02.s_id=s.s_id and s02.c_id='02');
--写法二:自连接,使得每行包含课程‘01’‘02’及其成绩;
select a.s_id
from score as a join score as b
on a.s_id=b.s_id and a.c_id='01' and b.c_id='02' and a.s_score>b.s_score;
--写法三:
select distinct a.s_id
from (select * from score where c_id='01') as a
join
(select * from score where c_id='02') as b
on a.s_id=b.s_id and a.s_score>b.s_score;
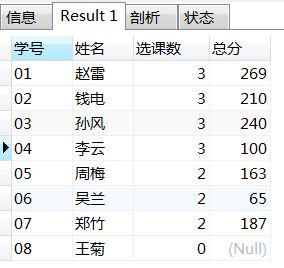
3、查询所有学生的学号、姓名、选课数、总成绩
/*
1、需求是所有学生的,那么student内所有学生都应该出现在结果里,无论有没有选课,故student left join score,而非 inner join ;
2、计数是针对课程(c_id),故准确应为count(c_id),而非count(*)对行记录进行计数;
在某些场景下,前面提到的两点中,不同的写法结果一致,但在当前,s_id='08'没有选课的情况下,结果就不一致了。因此,应当养成习惯,尽量逻辑严谨。
*/
select student.s_id as 学号,student.s_name as 姓名,count(c_id) as 选课数,sum(s_score) as 总分
from student left join score on student.s_id=score.s_id
group by student.s_id,student.s_name;
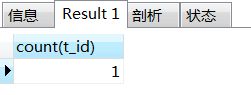
4、查询姓“张”的老师的个数
--count(t_name)也行,因为count统计非空记录数,不会因为有两个张三而只计数一个,但使用t_id更严谨,因为t_id是主键,是唯一标识;
select count(t_id)
from teacher
where t_name like '张%';
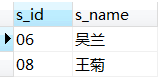
5.查询没学过“张三”老师课的学生的学号、姓名
--写法一:这些学生的s_id不在张三老师学生的s_id范围内
select s_id,s_name from student
where s_id not in (select score.s_id from teacher left join course on teacher.t_id=course.t_id
left join score on course.c_id=score.c_id
where teacher.t_name='张三'
);
--写法三:所有学生与张三的学生求并集(不去重),则张三的学生s_id每个都计数为2,非张三的学生s_id每个都计数为1
select s_id,s_name from student
where s_id in (select s_id from (select s_id from student
union all
select s_id from teacher left join course on teacher.t_id=course.t_id
left join score on course.c_id=score.c_id
where teacher.t_name='张三'
) as union_all
group by union_all.s_id having count(union_all.s_id)=1
);
7、查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
--写法一:筛选出同时选择了'01','02'课程的学生,然后按照学号姓名分组计数,若同时选了两门课,则计数应为2
select student.s_id,student.s_name
from student left join score on student.s_id=score.s_id
where c_id in ('01','02')
group by student.s_id,student.s_name
having count(*)=2;
--写法二:表score自连接,某个学生所选课程同列跨行排列,转换为同行跨列排列,相当于枚举出考虑了顺序的各种组合;
select student.s_id,student.s_name
from student left join score as s1 on student.s_id=s1.s_id
left join score as s2 on s1.s_id=s2.s_id
where s1.c_id='01' and s2.c_id='02';
--写法三:s_id既在选择了'01'的s_id里,也在选择了'02'的s_id里
select s_id,s_name from student
where s_id in (select s_id from score where c_id='02') and
s_id in (select s_id from score where c_id='01');
--写法四:目标属于,选了课程'01'的s_id表,与选了课程'02'的s_id表的交集;
select s_id,s_name
from student
where s_id in (select a.s_id
from (select s_id from score where c_id='01') as a #选了课程'01'的s_id
inner join
(select s_id from score where c_id='02') as b #选了课程'02'的s_id
on a.s_id=b.s_id #两张表的s_id的交集即为同时选择了两门课的学号
);
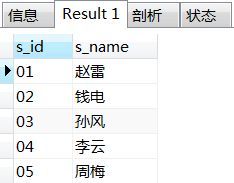
9、查询所有课程成绩小于60分的学生的学号、姓名
--一开始可能hi考虑每科去判断,但这种思路随着课程数的增加,工作是无限的,故换思路。
--写法一:目标:所有课程成绩小于60分的学生。其补集为至少有一科成绩大于等于60分学生,那么没在这部分的学生就是目标学生:
select s_id,s_name from student
where s_id not in (select distinct s_id from score where s_score>=60);
--写法二:最高分小于60或最高分为空
select st.s_id,st.s_name
from student as st left join score as sc on st.s_id=sc.s_id
group by st.s_id
having max(sc.s_score)<60 or max(sc.s_score) is null;
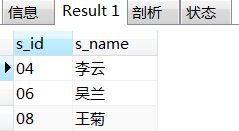
10、查询没有学全所有课的学生的学号、姓名
--写法一:目标学生所学课程数小于总的课程数
select st.s_id,st.s_name
from student as st left join score as sc on st.s_id=sc.s_id
group by st.s_id,st.s_name
having count(sc.c_id) < (select count(c_id) from course);
--have子句'<'右边应该是一个数值,而select查询语句返回的是一张表,加一个括号就变成了数值,不理解内在逻辑。
--写法二:exists搭配集合差集:所有课程的集合为A,某目标学生的课程集合为B,则目标学生的课程集合为B满足条件:A-B不为空。
select s_id,s_name
from student
where exists(select c_id from course
where c_id not in (select c_id from score where student.s_id=score.s_id)
);
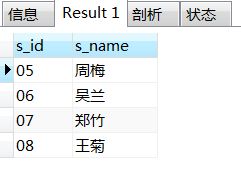
11、查询至少有一门课与学号为“01”的学生所学课程相同的学生的学号和姓名
--写法一:目标学生的任意一门课与'01'的其中某课相同,则筛出,然后去重;注意目标不能含'01';
select distinct st.s_id,st.s_name
from student as st left join score as sc on st.s_id=sc.s_id
where c_id in (select c_id from score where s_id='01') and st.s_id != '01';
--写法二:用exists,目标学生的课程与'01'的课程交集不为空;
select s_id,s_name
from student
where exists(select c_id from score
where student.s_id=score.s_id
and c_id in (select c_id from score where s_id='01')
and s_id<>'01'
);
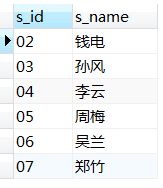
12、查询和“01”号同学所学课程完全相同的其他同学的学号
--利用课程数
select s_id from score
where s_id <> '01' and c_id in (select c_id from score where s_id='01')
group by s_id having count(c_id)=(select count(c_id) from score where s_id='01');
13、把“score”表中“张三”老师教的课的成绩都更改为此课程的平均成绩
--使用自定义变量,将复杂的查询逻辑化整为零,结合事务控制过程;
start transaction;
select c_id into @course_id from course join teacher on course.t_id=teacher.t_id where t_name='张三';
select avg(s_score) into @avg_score from score where c_id=@course_id;
update score set s_score=@avg_score where c_id=@course_id;
commit;
--为便于之后的练习,记得将数据恢复到修改前,可delete清空数据后重新insert into插入数据。
17、按平均成绩从高到低显示所有学生的“数据库”(c_id=‘04’)、“企业管理”(c_id=‘01’)、“英语”(c_id=‘06’)三门的课程成绩,按如下形式显示:学生ID,数据库,企业管理,英语,有效课程数,有效平均分
--学生ID,有效课程数,有效平均分可通过s_id分组后计算得到;
--学生ID,数据库,企业管理,英语分数原本在同一列,现在要根据c_id的不同, 放到不同列,可用case...when;
--将两部分分别做子查询,然后再做表连接。
select distinct b.s_id as 学生ID,数据库,企业管理,英语,有效课程数,有效平均分
from
(select s_id,count(c_id) as 有效课程数,avg(s_score) as 有效平均分 from score group by s_id) as b
left join
(select s_id ,
(case when c_id='04' then s_score else null end) as 数据库,
(case when c_id='01' then s_score else null end) as 企业管理,
(case when c_id='06' then s_score else null end) as 英语
from score where c_id in ('01','04','06')
) as a
on a.s_id=b.s_id
order by 有效平均分 desc
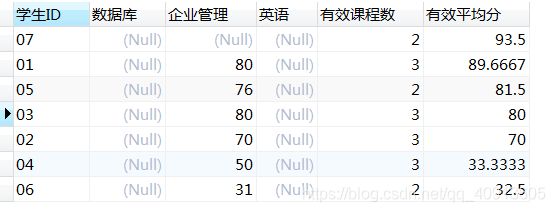
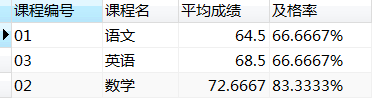
19、按各科平均成绩从低到高和及格率的百分数从高到低排列,以如下形式显示:课程号,课程名,平均成绩,及格百分数
--写法一:select后跟分组键、与分组键一一对应的列、聚合函数、常数
select s1.c_id as 课号,c_name as 课名,avg(s_score) 平均成绩,
concat(100*(select count(s_score) from score as s2 where s2.s_score>=60 and s2.c_id=c.c_id) /
(select count(*) from score as s3 where s3.c_id=s1.c_id),'%') as 及格率
from score as s1 join course as c on s1.c_id=c.c_id
group by s1.c_id
order by 平均成绩 asc,及格率 desc;
--写法二:case...when;select后跟分组键、聚合函数、常数
select c.c_id as 课程编号,c.c_name as 课程名,avg(s1.s_score) as 平均成绩,
concat(100*count(case when s_score>=60 then s_score else null end)/
(select count(*) from score as s2 where s1.c_id=s2.c_id),'%') as 及格率
from score as s1 join course as c on s1.c_id=c.c_id
group by c.c_id,c.c_name
order by 平均成绩 asc,及格率 desc;
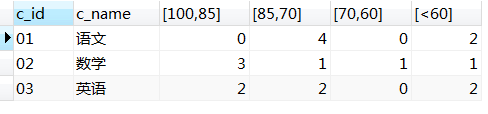
23、使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计各分数段人数:课程ID和课程名称
--分数原本在同一列,现需要根据分数所属区间放到不同列,可用case...when
select course.c_id,course.c_name,
sum(case when s_score between 85 and 100 then 1 else 0 end) as `[100,85]`,
sum(case when s_score between 70 and 84 then 1 else 0 end) as `[85,70]`,
sum(case when s_score between 60 and 69 then 1 else 0 end) as `[70,60]`,
sum(case when s_score<60 then 1 else 0 end) as `[<60]`
from course left join score on course.c_id=score.c_id
group by course.c_id,course.c_name
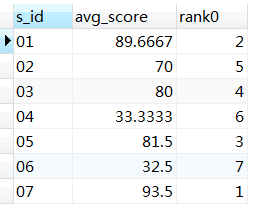
24、查询学生平均成绩及其名次
--思路:分数高于第1名的人数为0,分数高于第2名的人数为1,故任意一个人的分数名次是高于其分数的人数加1;
--若允许并列第一,则分数比较时,不应考虑等号;
--写法一:重复做同一个子查询
select s_id,`avg(s_score)`,
(select count(*) from (select s_id,avg(s_score) from score group by s_id) as avg2
where avg2.`avg(s_score)`>avg1.`avg(s_score)`
)+1 as rank0
from (select s_id,avg(s_score) from score group by s_id) as avg1;
--写法二:由于重复查询平均成绩,重复编写同一子查询,可该用用事务:
start transaction;
drop table if exists avg0;##确保建表前该表不存在
create table avg0 select s_id,avg(s_score) as avg_score from score group by s_id;
select *,(select count(*) from avg0 as avg2 where avg2.avg_score>avg1.avg_score)+1 as rank0
from avg0 as avg1;#临时表不能以select子句中的where子句形式调用
drop table avg0;#建表后删除表,实现临时表的功能;直接新建临时表create temporary table,不能被调用。
commit;
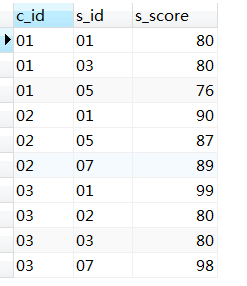
25、查询各科成绩前三名的记录,不考虑成绩并列情况
--思路:分数高于第一名的人数0,分数高于第二名的人数1,分开数高于第三名的人数2
--不考虑成绩并列情况:是允许结果有并列呢还是不允许?这里没讲清楚,下面的语句时允许并列出现的。
select c_id,s_id,s_score
from score as s1
where 2>=(select count(s_score) from score as s2
where s1.c_id=s2.c_id and s2.s_score>s1.s_score
)
order by c_id asc,s_id asc,s_score desc;
31、1990年出生的学生名单。
--写法一:函数year(datetime)或extract(year/month... from datetime)。year(datetime)提取日期字符串中的年,另有month(datetime)提取月,和extract功能一样;
select s_id,s_name,s_birth from student where year(s_birth)=1990;
select s_id,s_name,s_birth from student where extract(year from s_birth)=1990;
--写法二:datetime型数据本质也是字符串,真实被解析成datetime型,故可用like
select * from student where s_birth like '1990%';
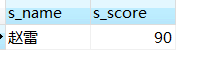
40、查询选修“张三”老师所授课程的学生中成绩最高的学生姓名及其成绩
--使用 limit m,n 从m开始,选取n个值
select st.s_name,sc.s_score
from student as st join score as sc on st.s_id=sc.s_id
join course as c on sc.c_id=c.c_id
join teacher as t on c.t_id=t.t_id
where t.t_name='张三'
order by sc.s_score desc limit 1;
42、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
--写法一:该学生所有课程中至少有两个不同课程的分数相同
select * from score as s1
where exists(select * from score as s2
where s1.s_id=s2.s_id and s1.s_score=s2.s_score and s1.c_id<>s2.c_id);
--写法二:这种学生所有分数的最大值最小值相同
select s_id,c_id,s_score
from score as sc1
where (select max(s_score) from score as sc2 where sc1.s_id=sc2.s_id)
=
(select min(s_score) from score as sc3 where sc1.s_id=sc3.s_id);
--写法三:这种学生所有分数去重后计数为1
select * from score
where s_id in (select s_id from score group by s_id having count(distinct s_score)=1)
#或
select * from score as sc1
where 1=(select count(distinct s_score) from score as sc2 where sc2.s_id=sc1.s_id);
46、查询选修了全部课程的学生信息
--写法一:所有课程的集合为A,该学生所选课程的集合为B,故有A>=B,B可以为空,目标是A-B为空,即不存在A有B无的项;
select * from student as st
where not exists (select c_id from course where c_id not in
(select c_id from score as sc where st.s_id=sc.s_id)
);
--写法二:该学生所选课程数等于课程总数
select st.s_id,st.s_name,st.s_birth,st.s_sex
from score join student as st on score.s_id=st.s_id
group by s_id having count(c_id)=(select count(*) from course);
47、查询没学过“张三”老师讲授的任一门课程的学生姓名
--写法一:该学生不在张三老师的学生集合内
select s_name from student
where s_id not in (select s_id from score
where c_id =(select c_id from course join teacher on course.t_id=teacher.t_id
where teacher.t_name='张三'));
--写法二:张三老师不在该学生的老师的集合内
select s_name from student as st
where '张三' not in (select t.t_name from teacher as t join course as c on t.t_id=c.t_id
join score as sc on sc.c_id=c.c_id
where st.s_id=sc.s_id
);
48、查询两门以上不及格课程的同学的学号及其平均成绩
select s_id,avg(s_score)
from score as s1
where 2<=(select count(c_id) from score as s2 where s1.s_id=s2.s_id and s2.s_score<60)
group by s_id;
--解析:where子句限制的是s_id,要求该s_id至少有两科分数低于60;对这类s_id的所有课程计算平均分;
--下面是有问题的写法:计算平均分的课程只有不及格的课程,where子句筛出的是s_id不及格的部分;
select s_id,avg(s_score)
from score
where s_score<60
group by s_id;
