kaggle数据挖掘竞赛--信用卡违约风险评估模型
本例程是通过客户提供的信息分析客户会产生违约的可能性。由此来判断是否要给客户提供贷款。背景内容不再多说,数据相关的解释在代码中会有注释。运行中缺失的包请自行安装,我这里的环境是anaconda
直接上代码:
import numpy as no
import pandas as pd
import os
import seaborn as sns
color = sns.color_palette()
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.offline as py
py.init_notebook_mode(connected=True)
from plotly.offline import init_notebook_mode,iplot
init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.offline as offline
offline.init_notebook_mode()
import cufflinks as cf
cf.go_offline()#下面开始加载数据
df_train = pd.read_csv('./dataset/Home_Credit/application_train.csv')
df_test = pd.read_csv('./dataset/Home_Credit/application_test.csv')#看看都有哪些属性
df_train.columns.values
#属性很多,有点吓人
print(df_train.shape)
#(307511, 122)
df_train.head()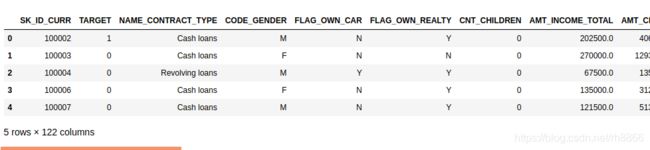
#检查application_train 中的缺失数据
total = df_train.isnull().sum().sort_values(ascending = False)
percent = (df_train.isnull().sum()/df_train.isnull().count()*100).sort_values(ascending=False)
missing_application_train_data = pd.concat([total,percent],axis = 1,keys=['Toatl','Percent'])
missing_application_train_data.head(10)
#开始探索我们的数据
#贷款金额 分布
plt.figure(figsize=(12,5))
plt.title("Distribution of AMT_CREDIT")
ax = sns.distplot(df_train["AMT_CREDIT"])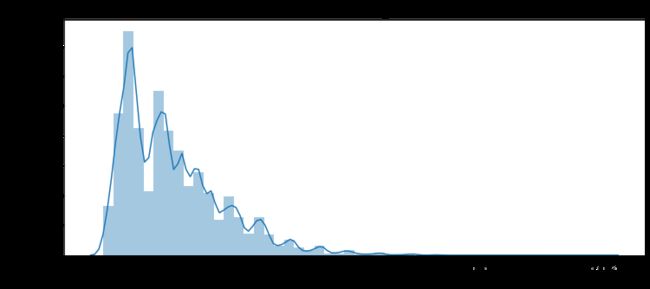
#客户年收入(大部分人都是在50000以下)
plt.figure(figsize=(12,5))
plt.title("Distribution of AMT_INCOME_TOTAL")
ax = sns.distplot(df_train["AMT_ANNUITY"].dropna())
#消费贷款,对应贷款的商品的价格
plt.figure(figsize=(12,5))
plt.title("Distribution of AMT_GOODS_PRICE")
ax = sns.distplot(df_train['AMT_GOODS_PRICE'].dropna())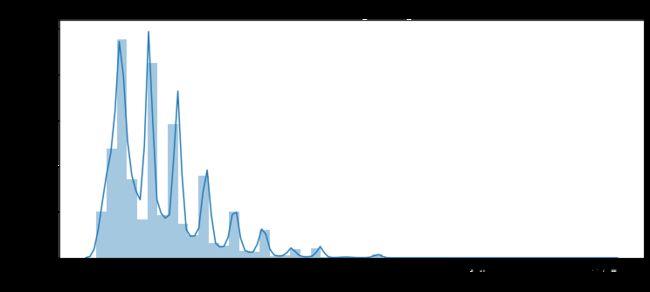
#申请贷款的时候客户的陪同人
temp = df_train["NAME_TYPE_SUITE"].value_counts()
trace = go.Bar(
x = temp.index,
y = (temp / temp.sum())*100,
)
data = [trace]
layout = go.Layout(
title = "Distribution of Name of type of the Suite in % ",
xaxis=dict(
title='Name of type of the Suite',
tickfont=dict(
size=14,
color='rgb(107, 107, 107)'
)
),
yaxis=dict(
title='Count of Name of type of the Suite in %',
titlefont=dict(
size=16,
color='rgb(107, 107, 107)'
),
tickfont=dict(
size=14,
color='rgb(107, 107, 107)'
)
)
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='schoolStateNames')
#如下图看来一个人的时候发生贷款的概率更高,有人陪同估计不好意思

#是否发生逾期未还的情况分布,看来绝大多数人还是守信用的
temp = df_train["TARGET"].value_counts()
df = pd.DataFrame({'labels': temp.index,
'values': temp.values
})
df.iplot(kind='pie',labels='labels',values='values', title='Loan Repayed or not')
#贷款是现金还是循环的标识 (就是一次性拿到全部贷款还是当前只拿部分在后面需要的时候再拿)
temp = df_train["NAME_CONTRACT_TYPE"].value_counts()
fig = {
"data": [
{
"values": temp.values,
"labels": temp.index,
"domain": {"x": [0, .48]},
#"name": "Types of Loans",
#"hoverinfo":"label+percent+name",
"hole": .7,
"type": "pie"
},
],
"layout": {
"title":"Types of loan",
"annotations": [
{
"font": {
"size": 20
},
"showarrow": False,
"text": "Loan Types",
"x": 0.17,
"y": 0.5
}
]
}
}
iplot(fig, filename='donut')
#如下图可知绝大部分人都只是会拿到贷款全部额度,毕竟贷款一般是解燃眉之急,很少有人贷款回来慢慢用。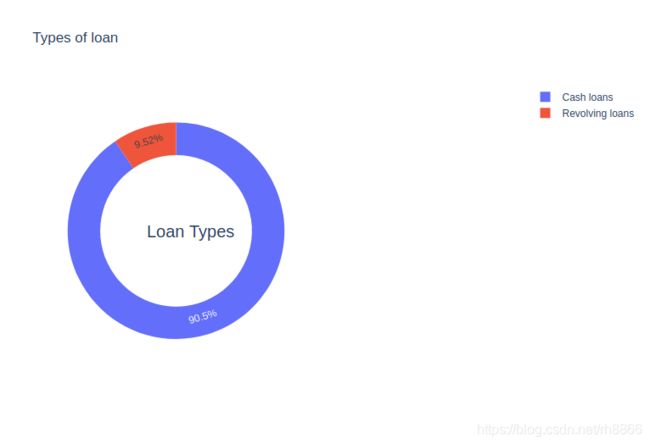
#是否有房/车
#FLAG_OWN_CAR 客户是否拥有汽车
#FLAG_OWN_REALTY 客户是否拥有房屋或公寓
temp1 = df_train["FLAG_OWN_CAR"].value_counts()
temp2 = df_train["FLAG_OWN_REALTY"].value_counts()
fig = {
"data": [
{
"values": temp1.values,
"labels": temp1.index,
"domain": {"x": [0, .48]},
"name": "Own Car",
"hoverinfo":"label+percent+name",
"hole": .6,
"type": "pie"
},
{
"values": temp2.values,
"labels": temp2.index,
"textposition":"inside",
"domain": {"x": [.52, 1]},
"name": "Own Reality",
"hoverinfo":"label+percent+name",
"hole": .6,
"type": "pie"
}],
"layout": {
"title":"Purpose of loan",
"annotations": [
{
"font": {
"size": 20
},
"showarrow": False,
"text": "Own Car",
"x": 0.20,
"y": 0.5
},
{
"font": {
"size": 20
},
"showarrow": False,
"text": "Own Reality",
"x": 0.8,
"y": 0.5
}
]
}
}
iplot(fig, filename='donut')
#如下图看下来,多数贷款的人是有房没车的人。有房没车估计也是底层人民啊,这符合我们正常的认知,没有住所的人去贷款估计也很难通过(谁愿意借钱给流浪汉呢)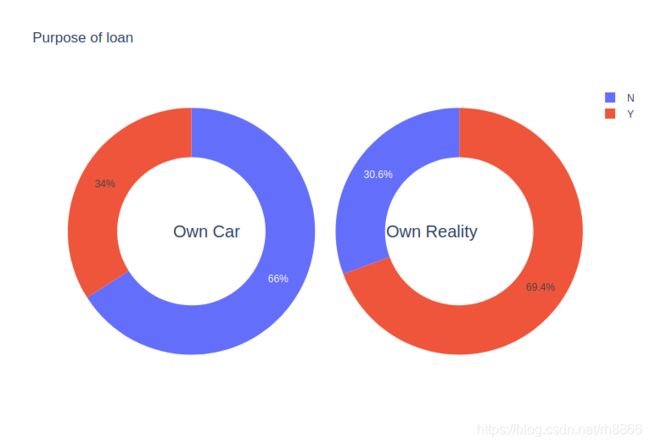
# 收入类型
# 工作/商业助理/退休人员/公务员/失业/学生/商人/产假
temp = df_train['NAME_INCOME_TYPE'].value_counts()
df = pd.DataFrame({'labels':temp.index,
'values':temp.values})
df.iplot(kind='pie',labels='labels',values='values',title='Income sources of Applicant\'s',hole=0.5)
#多数人还是上班族(干得多拿得少,万恶的资本主义)
#贷款申请人的家庭状况
#结婚(有宗教或教堂参与的)/单身/民事婚姻(类似中国有政府部门颁发结婚证的民间组织的婚姻)/分离/寡(应该是丧偶)/未知
temp = df_train['NAME_FAMILY_STATUS'].value_counts()
df = pd.DataFrame({'labels':temp.index,
'values':temp.values})
df.iplot(kind='pie',labels='labels',values='values',title='Family Status of Applicant\'s',hole=0.6)
#除了正常已婚人士,单身汉也不少,看来单身汉是真缺钱(要不然也不会单身是吧)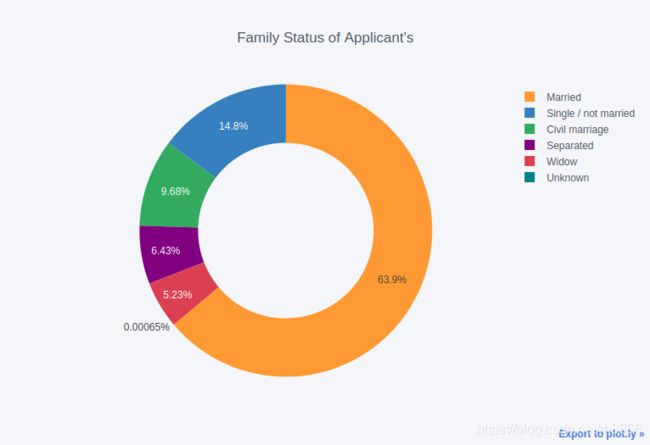
#申请人的职业
temp = df_train['OCCUPATION_TYPE'].value_counts()
# df = pd.DataFrame({'labels':temp.index,
# 'values':temp.values})
# df.iplot(kind='pie',labels='labels',values='values',title='Family Status of Applicant\'s',hole=0.6)
temp.iplot(kind='bar',xTitle='Occupation',yTitle='Count',title='Occupation of Applicatnt\'s who applied for loan',color='green')
#看看下图,最缺钱的是伟大的劳动者,最不缺钱的竟然是我们IT人员(看来是我拖大家的后腿了)
#申请人的教育情况
temp = df_train['NAME_EDUCATION_TYPE'].value_counts()
df = pd.DataFrame({'labels':temp.index,
'values':temp.values})
df.iplot(kind='pie',labels='labels',values='values',title='Education od Applicant\'s',hole=0.5)
#Secondary special 中等专业学校学历的人最缺钱,然后是Higher education高等教育,难道是学历越高眼界越高,欲望越多,压力越大(也有可能是其他的情况,比如学历底了收入少、还款能力底,贷款批不下来,也就不再去申请贷款了)
#住房情况
temp = df_train["NAME_HOUSING_TYPE"].value_counts()
df = pd.DataFrame({'labels': temp.index,
'values': temp.values
})
df.iplot(kind='pie',labels='labels',values='values', title='Type of House', hole = 0.5)
#住父母房子的人贷款的是最多的(难道是生活压力小只想这享乐了,合租的人很少去贷款估计是要攒钱改善生活吧)
#工作机构类型
temp = df_train["ORGANIZATION_TYPE"].value_counts()
df = pd.DataFrame({'labels': temp.index,
'values': temp.values
})
df.iplot(kind='pie',labels='labels',values='values', title='Type of House', hole = 0.5)
#最缺钱的是做实体的(这个国内情况很相似,踏实做事的企业赚不到钱;反倒不如投机倒把,炒房,炒股票的赚钱,堪忧啊)
#将类别属性数值化
from sklearn import preprocessing
#找出类别的属性
categorical_features = [
categorical for categorical in df_train.columns if df_train[categorical].dtype == 'object'
]
#将类别属性数值化
for i in categorical_features:
lben = preprocessing.LabelEncoder()
lben.fit(list(df_train[i].values.astype('str')) + list(df_test[i].values.astype('str')))
df_train[i] = lben.transform(list(df_train[i].values.astype('str')))
df_test[i] = lben.transform(list(df_test[i].values.astype('str')))#用-999填充空值
df_train.fillna(-999, inplace = True)
df_test.fillna(-999, inplace = True)#构建模型
#LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中。
#如果没有lightgbm包,则需要安装(用了镜像源) pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ lightgbm
import lightgbm as lgb
from sklearn.model_selection import train_test_split #提取标签列
Y = df_train['TARGET']
test_id = df_test['SK_ID_CURR']
#删除不用与训练的属性
train_X = df_train.drop(['TARGET','SK_ID_CURR'],axis=1)
test_X = df_test.drop(['SK_ID_CURR'], axis = 1)#训练集分割为训练数据和验证数据
x_train, x_val, y_train, y_val = train_test_split(
train_X,
Y,
random_state=18)
lgb_train = lgb.Dataset(data=x_train, label=y_train)
lgb_eval = lgb.Dataset(data=x_val, label=y_val)#模型参数
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.05,
'num_leaves': 32,
'num_iteration': 500,
'verbose': 0
}#开始训练
model = lgb.train(params,lgb_train,valid_sets=lgb_eval,early_stopping_rounds=100,verbose_eval=10)

#特征的重要性分布如下
lgb.plot_importance(model,figsize=(18,20))

#预测
pred = model.predict(test_X)
sub = pd.DataFrame()
sub['SK_ID_CURR'] = test_id
sub['TARGET'] = pred
#保存结果
sub.to_csv("baseline_submission.csv", index=False)
sub.head(10)
#换一个训练模型
#LGBMClassifier
from lightgbm import LGBMClassifier
clf = LGBMClassifier(
n_estimators=300,
num_leaves=15,
colsample_bytree=.8,
subsample=.8,
max_depth=7,
reg_alpha=.1,
reg_lambda=.1,
min_split_gain=0.01)#开始训练
clf.fit(x_train,
y_train,
eval_set=[(x_train,y_train),(x_val,y_val)],
eval_metric='auc',
verbose=0,
early_stopping_rounds=30)
#预测
pred_1 = clf.predict(test_X)
sub = pd.DataFrame()
sub['SK_ID_CURR'] = test_id
sub['TARGET'] = pred_1
sub.to_csv("submission_clf.csv", index=False)
sub.head(10)
以上便是通过客户提供的信息预测客户有可能违约的模型实现过程,这里我将有数据都纳如到训练中,当然也可以根据你你自己的判断和思考去掉某些属性;也可以对其中的一些数值型属性进行分段划分。另外也可以用其他你认为更好的算法来训练模型,欢迎流言交流。