我们要爬取评论信息,首先在请求消息头部封装必要的内容,这样吧,先上全部代码:
# -*- coding: utf-8 -*-
#导入requests库(请求和页面抓取)
import requests
#导入time库(设置抓取Sleep时间)
import time
#导入random库(生成乱序随机数)
import random
#设置请求头文件的信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'Accept':'*/*',
'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Referer':'http://www.mafengwo.cn/poi/13732.html'
}
cookie={'PHPSESSID':'bivg7utd58gij4c95edtfn5075',
'mfw_uuid':'5b0fb182-6fd6-0655-688b-f861c77ef5b9',
'uva':'s%3A78%3A%22a%3A3%3A%7Bs%3A2%3A%22lt%22%3Bi%3A1527755140%3Bs%3A10%3A%22last_refer%22%3Bs%3A6%3A%22direct%22%3Bs%3A5%3A%22rhost%22%3Bs%3A0%3A%22%22%3B%7D%22%3B',
'__mfwurd':'a%3A3%3A%7Bs%3A6%3A%22f_time%22%3Bi%3A1527755140%3Bs%3A9%3A%22f_rdomain%22%3Bs%3A0%3A%22%22%3Bs%3A6%3A%22f_host%22%3Bs%3A3%3A%22www%22%3B%7D',
'__mfwuuid':'5b0fb182-6fd6-0655-688b-f861c77ef5b9',
'UM_distinctid':'163b54d758a733-084cd4ee1d553d-b34356b-144000-163b54d758b267',
'_r':'sogou',
'_rp':'a%3A2%3A%7Bs%3A1%3A%22p%22%3Bs%3A18%3A%22www.sogou.com%2Flink%22%3Bs%3A1%3A%22t%22%3Bi%3A1528184664%3B%7D',
'oad_n':'a%3A5%3A%7Bs%3A5%3A%22refer%22%3Bs%3A21%3A%22https%3A%2F%2Fwww.sogou.com%22%3Bs%3A2%3A%22hp%22%3Bs%3A13%3A%22www.sogou.com%22%3Bs%3A3%3A%22oid%22%3Bi%3A1112%3Bs%3A2%3A%22dm%22%3Bs%3A15%3A%22www.mafengwo.cn%22%3Bs%3A2%3A%22ft%22%3Bs%3A19%3A%222018-06-05+15%3A44%3A24%22%3B%7D',
'__mfwlv':'1528335819',
'__mfwvn':'5',
'__mfwlt':'1528335837'
}
#设置URL的第一部分
url1='http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery1810032117359187310734_1528335837579¶ms={"poi_id":"13732","page":'
#设置URL的第二部分
url2=',"just_comment":1}'
#乱序输出0-264的唯一随机数
ran_num=random.sample(range(1,2), 1)
#拼接URL并乱序循环抓取页面
for i in ran_num:
a = ran_num[0]
if i == a:
i=str(i)
url=(url1+i+url2)
r=requests.get(url=url,headers=headers,cookies=cookie)
html=r.content
else:
i=str(i)
url=(url1+i+url2)
r=requests.get(url=url,headers=headers,cookies=cookie)
html2=r.content
html = html + html2
time.sleep(5)
print("当前抓取页面:",url,"状态:",r)
ht1=html.decode('unicode-escape')
ht2=ht1.replace('\/','/')
#将编码后的页面输出为txt文本存储
file=open('pa1.txt','w',encoding='utf-8')
file.write(ht2)
file.close()
看一下该页面的请求信息:
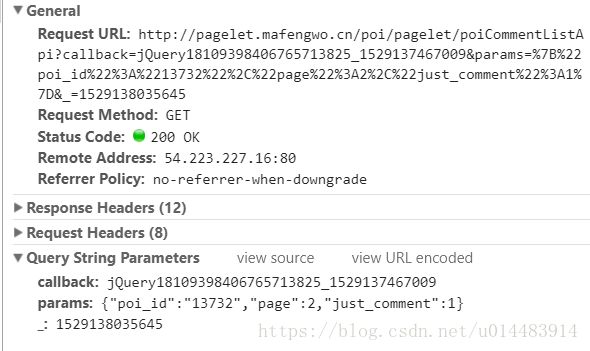
注意Request URL和下面的params,主要信息是对应的,一下是我之前做的笔记:
%22是引号,%3A是冒号,%2C是逗号
poi_id":"13732":这是都江堰景区的id
每页的“”属性都不一样
所以每个评论页的不同点为“page”和“”
亲测发现,去掉“_”属性也能正常访问页面 ---------> 画重点会考
http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery1810032117359187310734_1528335837579¶ms={"poi_id":"13732","page":4,"just_comment":1}照样可以访问(将unicode编码换成常规操作)
所以我们如果想访问所有页面,只需更改page的值就行了,这样我们采用地址拼接,组合请求的url。
继续往下,用到了random.sample()方法,sample(seq, n) 意思是从序列seq中选择n个随机且独立的元素;为了测试方便,我只访问第一页。
马蜂窝的数据应该是经过加密的,将request url中的地址复制到浏览器打开,发现是这样的:

这一块搞了很久才解决,各种转码就是不好使,最后查到的就是decode('unicode-escape'),它可以将unicode编码的汉字正常显示,然后还有一个问题,所有的‘\’都被转义了,这就看着很别扭了(虽然不影响程序的正常运行),想了很多办法都不行,python2中有个方法可以解决这一问题,但在python3中禁用了,也没找到合适的替代品,最后用了最简洁明了的“物理方法”ht2=ht1.replace('/','/') ,直接替换。。。这样就很美观了。
关于for循环也很简单,逻辑很老套但却实用,第一次访问时(随机地访问某一页)将内容存在html中,以后都存在html2中,这样就能获取全部数据了。
最后将爬取的数据存入文档中,要记得设置encoding,关于编码解码问题至今也只懂得些皮毛,能保证基本的显示运行吧。
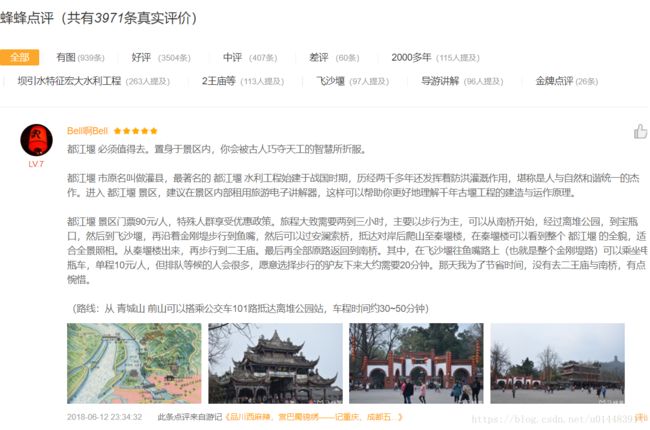
看一下最终效果:

对应的首页内容: