变分自编码器:金融间序的降维与指标构建(附代码)

标星★公众号 爱你们♥
作者:Marie Imokoyende
编译:方的馒头
近期原创文章:
♥ 5种机器学习算法在预测股价的应用(代码+数据)
♥ Two Sigma用新闻来预测股价走势,带你吊打Kaggle
♥ 2万字干货:利用深度学习最新前沿预测股价走势
♥ 机器学习在量化金融领域的误用!
♥ 基于RNN和LSTM的股市预测方法
♥ 如何鉴别那些用深度学习预测股价的花哨模型?
♥ 优化强化学习Q-learning算法进行股市
♥ WorldQuant 101 Alpha、国泰君安 191 Alpha
♥ 基于回声状态网络预测股票价格(附代码)
♥ 计量经济学应用投资失败的7个原因
♥ 配对交易千千万,强化学习最NB!(文档+代码)
♥ 关于高盛在Github开源背后的真相!
♥ 新一代量化带货王诞生!Oh My God!
♥ 独家!关于定量/交易求职分享(附真实试题)
♥ Quant们的身份危机!
♥ 拿起Python,防御特朗普的Twitter
♥ AQR最新研究 | 机器能“学习”金融吗?

本文探讨了使用一个变分自动编码器来降低使用Keras和Python的金融时间序列的维度。我们将进一步检测不同市场中的金融工具之间的相似性,并将使用获得的结果构建一个自定义指数。
获取全部代码,见文末
![]()
在本节中,我们将讨论:
创建几何移动平均数据集
使用随机模拟扩充数据
构建变分自动编码器模型
获取预测
▍创建几何移动平均数据集
为了比较各种价格区间的时间序列,我们选择计算收益的几何移动平均时间序列,定义如下:
![]()
我们选择d=5,因为它代表了一周的交易日。
本文使用的数据集包含从2016年1月4日到2019年3月1日期间的423个几何移动平均时间序列。
类似于这样:

结果可以通过绘制一些样本股价时间序列及其几何移动平均曲线来验证:

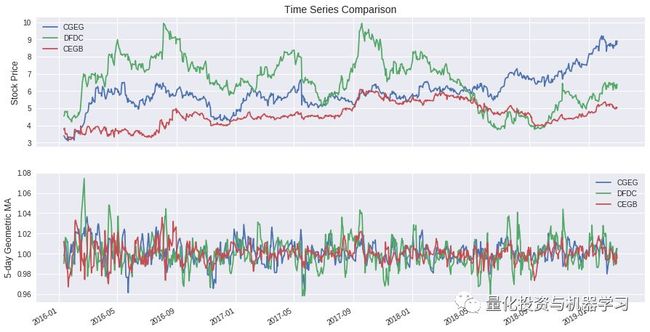
然后,刚刚构建的dataframe可以分为两个等长的时间段,仅在第一阶段内转置一个。第1阶段从2016年1月12日到2017年8月4日。第2阶段从2017年8月7日到2019年3月1日。
我们将只使用第1阶段的数据来获取预测。

我们对dataframe进行转置,以便每一行表示给定股票的时间序列:

▍使用随机模拟扩充数据
我们将使用随机模拟来生成合成的几何移动平均曲线。目标不是精确地建模返回,而是获得具有类似于真实数据的行为的曲线。通过仅使用模拟曲线训练模型,我们可以保留真实的数据来获得预测。
使用几何布朗运动生成合成曲线。我们遵循以下步骤操作:
1、使用第一阶段dataframe,随机选择100只股票代码;
2、对于所选的每只股票代码,计算一个对数收益的向量,以便:

3、然后对于所选的每只股票代码,我们将生成100条路径,以便:
![]()
这里有一条模拟曲线和一条真实曲线的示例:


我们已将423个时间序列的数据集扩展为100 * 100 = 10,000个与股票数据集相似(但不相等)的新时间序列。
这将允许我们保留实际的股票数据集范围以进行预测,甚至不必使用它进行验证。
在构建变分自动编码器(VAE)模型之前,创建训练和测试集(使用80%-20%的比率):

读者还应该注意,在训练模型之前,无需删除时间序列的季节性和趋势。
▍构建变分自动编码器模型(VAE)
我们将使用变分自动编码器将具有388个项目的时间序列向量的维度降低到二维点。
自动编码器是用于压缩数据的无监督算法。它们是由一个编码器、一个解码器和一个丢失函数构成,用于测量压缩和解压缩数据表示之间的信息丢失。
该编码器模型具有:
一个长度为388的输入向量
一个长度为300的中间层,具有整流线性单元(ReLu)激活功能
一个二维编码器。
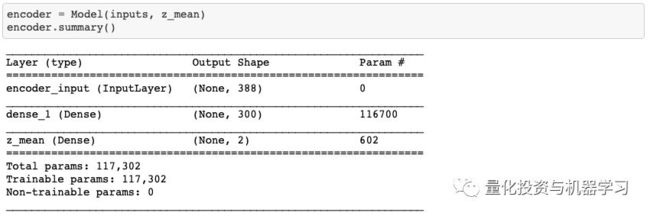
解码器模型具有:
一个二维输入向量(从潜在变量中采样)
一个长度为300的中间层,具有整流线性单元(ReLu)激活功能
具有S形激活函数的长度为388的解码向量。

以下代码改编自Keras上Github团队的variational_autoencoder.py。它用于构建和训练VAE模型。
https://github.com/keras-team/keras/blob/master/examples/variational_autoencoder.py

训练结束后,我们绘制训练和验证损失曲线:


▍获取预测
我们将只使用编码器来获取预测。我们将使用实值矩阵,包括股票数据集和一个或多个感兴趣的时间序列。
在我们的项目中,我们针对在另一个国家以不同货币所列出的前一个月期货合约测试了一个股票数据集。

我们获得了以下结果:
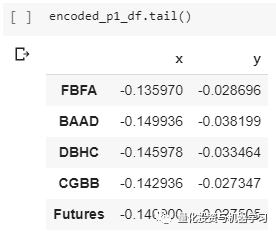
在绘制结果之前,我们必须:
1、计算期货合约点与dataframe中所有其他股票之间的距离。
2、选择最接近期货合约的50pints。
我们现在可以绘制获得的结果,以可视化最近的50只股票:


我们已经对另一个国家所列出的期货合约进行了分析,但是对于来自于同一交易所的股
票,我们可以按照第1部分中的相同步骤进行。
指标构建
让我们使用在第1部分中获得的结果来创建一个指标。
由于VAE模型的随机性,我们将无法获得每次运行的前50只股票的准确列表。为了得到最接近50个点的公平表示,我们将运行VAE模型(每次运行时重新初始化和重新训练)。然后,我们将在每次运行中找到的50个最近点,以创建一个长度为500的dataframe closest_points_df。
一旦建立了dataframe closet_points_df:
1、按距离对点进行排序;
2、删除重复的代码,只保留第一次出现;

删除重复项后,我们只保留50个最近点。
▍计算每只股票的权重
在指数构建中,股票权重的计算采用不同的方法,如市值法或股票的价格法。
相反,我们将计算每只股票的权重,使得最接近期货合约点的点将比离它较远的点获得更高的权重。
对于非匿名股票数据,在计算股票权重之前,对得到的结果进行过滤是非常重要的。应删除异常值并改进市值范围。

▍计算样本权重
计算每只股票的股数
计算权重后,我们计算了自定义指标中每只股票的股数。我们需要:
在2016年1月4日(第1期的第一天)获得的每只股票的价格
定义净资产金额
计算每只股票的股数
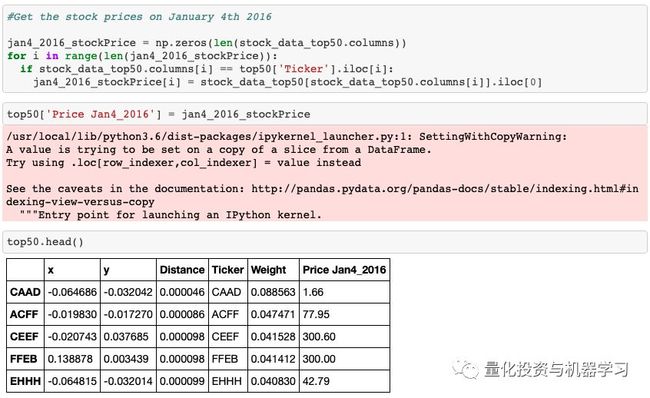
我们为2016年1月4日的股价增添了一列

我们为股份数增添了一列
指标构建
为了建造指标,我们将使用拉斯拜尔指数(Laspeyresindex),计算如下:
我们绘制了获得的自定义指标:



将我们的自定义指标与期货时间序列进行比较
我们必须缩放期货价格数据,以便将其绘制在与我们自定义指标相同的图表中。要做到这一点,我们必须:
计算期货价格数据的日百分比变化
设置S_0=100
现在我们将曲线绘制在同一张图表中:
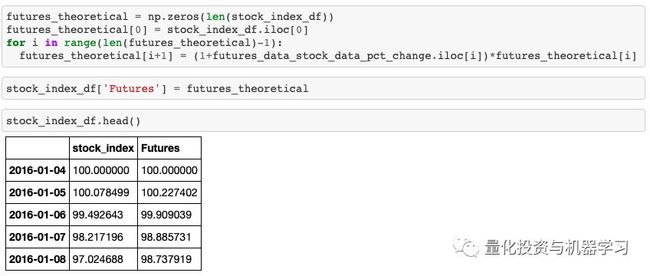

除2018年下半年外,我们的指数与参考期货时间序列的趋势大致相同。因为我们使用匿名数据,所以我们没有过滤股票的异常值和市值限制。此外,在观察到的两个时间段内没有重新平衡,并且我们忽略了分布。
如果识别出股票代码并删除异常值,则自定义指数绝对有可能击败期货指数。
我们鼓励大家利用在线提供的免费(GPU)实例创建自己的指标。这对我们来说是一个有趣的实验,我们发现了一些有趣的股票模式。
使用变分自动编码器可以加快外国股票市场新指数的发展,即使分析师不熟悉它们。此外,还可以创建符合客户利益的利基指数或投资组合。
虽然这种方法可以用于创建ETF,但我们相信它也可以为全球的直接指数和智能投顾公司创造新的投资可能性。
在后台输入(严格大小写)
变分自编码器LhtzJQXX
—End—
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、CST、AI等专业的主流量化自媒体。公众号拥有来自公募、私募、券商、银行、海外等众多圈内10W+关注者。每日发布行业前沿研究成果和最新量化资讯。
