StarGAN
CVPR 2018 《StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation》
github - 1 github - 2

昨天在看《CollaGAN: Collaborative GAN for Missing Image Data Imputation》(发表于CVPR 2019)这篇文章所提到的模型结构时,顿生疑惑,这不仅就是StarGAN吗?有什么区别吗?我为什么这么说呢,首先来直观的看一下它们两个的模型架构:

StarGAN
CollaGAN如下所示
CollaGAN
是不是特别的相似呢 !..持续懵逼中…但是既然都是顶会论文,必然会有不同,所以我又重新研读了一下StarGAN的论文,希望可以明白两者的不同之处。
StarGAN
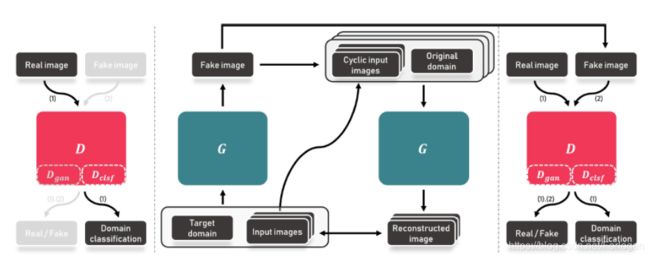
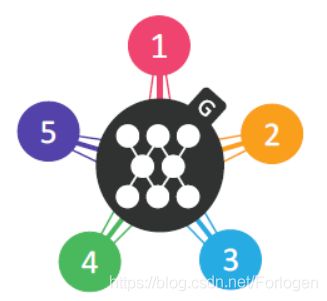
首先我们看一下StarGAN是怎样的一个GANs:它解决的是关于多域(Domain)之间图像的转换问题,但是我们知道,在此之前已经有例如CycleGAN、DiscoGAN、pix2pix、UNIT、CoupleGAN等诸多GAN的变体,使用它们我们就可以完成域之间图像的转换,即Image-to-Image的工作。相比而言,StarGAN的意义在哪里呢?仔细比较就可以明白,此前的模型主要完成的都是两个域之间的转换工作,如果想要完成多个域之间的转换,就有点麻烦了。假设我们有 K K K个域图像的数据集,如果想要实现任意两个域之间的转换,就需要训练 K ( K − 1 ) K(K-1) K(K−1)个生成器(Generator,G), 如下所示,当我们有4个域时,就要训练12个生成器

虽然这样做理论上可以达成目的,但是由于GAN本身训练的难度就很高,要想完成 K ( K − 1 ) K(K-1) K(K−1)生成器的训练,工作量是难以忍受的。而StarGAN的提出就是为了解决这个问题,它可以完成多个域之间图像的转换,但是只需训练一个生成器,而不是 K ( K − 1 ) K(K-1) K(K−1)个,如下所示
下面就来看一下StarGAN是如何巧妙的解决上述的难题的!我们从目标函数的设置和模型架构两个方面结合着看一下,最后简单的看一下实验结果。
目标函数
StarGAN中主要包含三个损失项:Adversarial Loss、Domain Classification Loss、Reconstruction Loss,下面依次来看一下是如何设置的。
首先,作为GAN的一个新的变体,自然无法脱离其中最重要的对抗的思想,所以第一个损失项就是Adversarial Loss。StarGAN的生成器接收输入图像(input image) x x x 和域标签(domain label) c c c 两项,输入转换后的图像(output image) y y y,即 G ( x , c ) → y G(x,c) \rightarrow y G(x,c)→y。对于判别器(Discriminator,D)来说,它需要判别输入到D的图像是来自源图像域还是目标图像域,即 D : x → { D s r c ( x ) , D c l s ( x ) } D : x \rightarrow\left\{D_{s r c}(x), D_{c l s}(x)\right\} D:x→{Dsrc(x),Dcls(x)} ,因此完整的Adversarial Loss为:
L a d v = E x [ log D s r c ( x ) ] + E x , c [ log ( 1 − D s r c ( G ( x , c ) ) \mathcal{L}_{a d v} = \mathbb{E}_{x}[\log D_{s r c}(x)]+ \mathbb{E}_{x, c}[\log(1-D_{s r c}(G(x, c)) Ladv=Ex[logDsrc(x)]+Ex,c[log(1−Dsrc(G(x,c))
但是为了提高StarGAN训练过程的稳定性,这里最后使用的是Improved-WGAN中的对抗损失项:
L a d v = E x [ D s r c ( x ) ] − E x , c [ D s r c ( G ( x , c ) ) ] − λ g p E x ^ [ ( ∥ ∇ x ^ D s r c ( x ^ ) ∥ 2 − 1 ) 2 ] \begin{aligned} \mathcal{L}_{a d v}=& \mathbb{E}_{x}\left[D_{s r c}(x)\right]-\mathbb{E}_{x, c}\left[D_{s r c}(G(x, c))\right] \\ &-\lambda_{g p} \mathbb{E}_{\hat{x}}\left[\left(\left\|\nabla_{\hat{x}} D_{s r c}(\hat{x})\right\|_{2}-1\right)^{2}\right] \end{aligned} Ladv=Ex[Dsrc(x)]−Ex,c[Dsrc(G(x,c))]−λgpEx^[(∥∇x^Dsrc(x^)∥2−1)2]
第二个就是Domain Classification Loss,我们希望经过G生成的样本 y y y 属于目标域 c c c,所以作者在D之前又引入了一个辅助的分类器,然后使用Domain Classification Loss来优化G和D。它分为两项:关于真实样本(目标域中的样本)的域分类损失用来优化D;关于假样本(生成样本)的域分类损失用来优化G。即:
L c l s r = E x , c ′ [ − log D c l s ( c ′ ∣ x ) ] L c l s f = E x , c [ − log D c l s ( c ∣ G ( x , c ) ) ] \mathcal{L}_{c l s}^{r}=\mathbb{E}_{x, c^{\prime}}\left[-\log D_{c l s}\left(c^{\prime} | x\right)\right] \\ \mathcal{L}_{c l s}^{f}=\mathbb{E}_{x, c}\left[-\log D_{c l s}(c | G(x, c))\right] Lclsr=Ex,c′[−logDcls(c′∣x)]Lclsf=Ex,c[−logDcls(c∣G(x,c))]
其中 r r r表示real, f f f表示fake, c ′ c' c′代表的是原始域的域标签, c c c代表目标域的域标签。对于输入图像 x x x来说,D希望正确的判别它为原始域的概率越大越好,所以需要最小化第一项;而对于生成样本来说,希望它越接近目标域越好,相当于希望D将其判别为目标域的概率越大越小,所以同样的需要最小化第二项。
经过前面的两个损失项的设置,我们可以使得生成结果越来越真实,同时属于目标域的概率越大,但是为了更好的保留原始输入图像中的内容信息,这里类似于auto-encoder,引入了Reconstruction Loss,希望重建后的图像越接近输入越好,即
L r e c = E x , c , c ′ [ ∥ x − G ( G ( x , c ) , c ′ ) ∥ 1 ] \mathcal{L}_{r e c}=\mathbb{E}_{x, c, c^{\prime}}\left[\left\|x-G\left(G(x, c), c^{\prime}\right)\right\|_{1}\right] Lrec=Ex,c,c′[∥x−G(G(x,c),c′)∥1]
因此,完整的损失函数为:
L D = − L a d v + λ c l s L c l s r L G = L a d v + λ c l s L c l s f + λ r e c L r e c \begin{array}{c}{\mathcal{L}_{D}=-\mathcal{L}_{a d v}+\lambda_{c l s} \mathcal{L}_{c l s}^{r}} \\ {\mathcal{L}_{G}=\mathcal{L}_{a d v}+\lambda_{c l s} \mathcal{L}_{c l s}^{f}+\lambda_{r e c} \mathcal{L}_{r e c}}\end{array} LD=−Ladv+λclsLclsrLG=Ladv+λclsLclsf+λrecLrec
其中 λ c l s \lambda_{cls} λcls和 λ r e c \lambda_{rec} λrec为两个超参数,文中的实验取值为1和10。
这样通过控制输入到G中的目标域标签 c c c,就可以使用一个生成器来实现任意两个域之间的图像转换。
另一个StarGAN的优点就是,它可以同时操作多个不同类型的数据集所拥有的类标签,但是如何在过程中保证只让G知道某个域的信息呢?假设我们要联合训练CelebA和RaFD两个数据集,前者包含的有例如发色、性别等属性信息,后者包含的是开心、愤怒等面部表情,那么如何将CelebA中的图像训练得到RaFD中包含的面部表情信息的图像呢?一种最直接的方法是使用one-hot向量,假设原先域的属性信息使用5维的one-hot向量表示,那么现在将其变长到例如8维不就行了吗?但是CelebA中的图像也有面部表情,RaFD中的图像也有发色、性别等信息,这样的方式就使得D不知道你想要完成的是哪两个域的转换,我们希望模型关注的是某一部分信息。因此,作者引入了Mask Vector来解决这个问题,如下所示:
c ~ = [ c 1 , … , c n , m ] \tilde{c}=\left[c_{1}, \ldots, c_{n}, m\right] c~=[c1,…,cn,m]
它也是一个n维的one-hot向量,其中 n n n表示的是数据集的数目, c i c_{i} ci表示第 i i i 个域的标签信息,如果它是二进制属性就可以表示位二进制向量,如果是类别属性,其中表示该类的为1,其余的 n − 1 n-1 n−1个指定为0。
下面通过一个实例看一下以上的设计是如何结合在一起的

如上所示,当希望模型关注的是CelebA中的信息时,Mask vector设置为 [ 1 , 0 ] [1,0] [1,0](紫色部分),同时关于CelebA的标签信息不全是零,其中值为1 的表示选择的属性,而RaFD的标签信息全部为零;同理当希望模型关注的是RaFD中的信息时,设置相反。
实验
最后看一下实验的结果,更多的结果可见原论文和官方GitHub。

可以看到,StarGAN可以完成多个域的图像转换,而且生成结果的质量也很高。
而当完成one-to-one域之间的转换工作时,效果也要优于之前的模型
同时作者也通过实验证明了联合训练的结果要更好

END
夜已深,关于CollaGAN的内容以及和StarGAN的对比明天再写喽~~