论文笔记——Multi-Scale Dense Convolutional Networks for Efficient Prediction
Multi-Scale Dense Convolutional Networks for Efficient Prediction -多尺度卷积网络
Gao Huang Cornell University ,Danlu Chen Fudan University,Tianhong Li Tsinghua University, Felix Wu Cornell University Published as a conference paper at ICLR 2018
problem

左边的图像更容易被分类
问题解决思路:
简单图像仅采用浅层的速度较快的网络来分类,难分类图像再采用深层的速度慢一点的网络来分类。
做法:
一张图像先过简单网络,如果输出概率能有较大把握判断该图像的类别,那么就直接输出这个类别。如果输出概率没有较大把握判断该图像的类别(比如概率小于某个阈值),那么就把这张图像再过一下深层网络。
这样的做法带来的问题:
1、对于简单图像而言却是可以节省时间,但是对于难分类的图像显然也增加了时间(可能要过好几个网络,最后的结果也不一定正确)。
2、如果一张图像是难分类的图像,那么就要过好几次网络才能得到结果,而在过后面几个网络的时候,前面网络所提取的特征都没利用到。
Problem in early-exit CNN
•1. The features in the last layer are extracted directly to be used by the classifier, whereas earlier features are not. The inherent dilemma is that different kinds of features need to be extracted depending on how many layers are left until the classification. 底层的特征没有被充分利用
•
•2. The features in different layers of the network may have different scale.(fine&coarse) 不同的层提取的特征尺度不同
Solution
Multi-Scale Densenet网络:在一个网络中有多个分类出口,对于简单图像可以直接从前面某个分类出口得到结果,而难分类的网络可能要到网络后面的某一层才能得到可靠的结果,而且这些分类出口并不是简单在一个网络的一些层直接引出,毕竟浅层特征直接用来分类的效果是非常差的,因此采用的是multi-scale的特征。
Computational constraints
•anytime prediction:对于每一张输入图像x都有一个计算资源限制条件(computational budget)B>0,相当于每次给模型输入一张图像,然后根据计算资源限制来给出预测结果。
•
•budgeted batch classification:每一个batch的输入图像都有一个computational budget B>0,假设这个batch里面包含M张图像,那么可能简单图像的耗时要小于B/M,而复杂图像的耗时要大于B/M。
Solution : intermediate early-exit classifiers
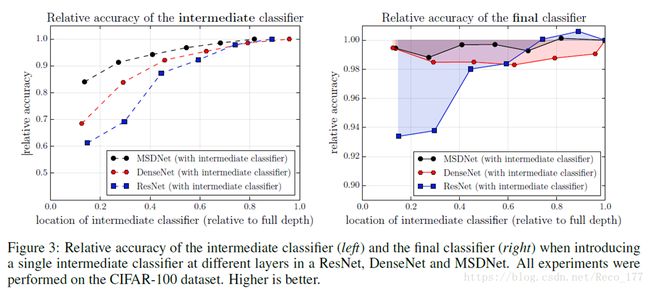
1、early classifiers lack coarse-level features
2、classifiers throughout interfere with the feature generation process.
MSDNet
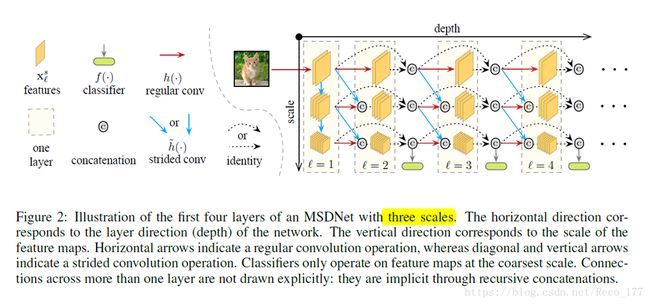
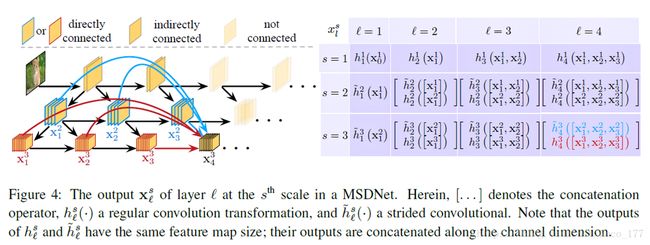
Classification
•The classifiers :Each classifier consists of two convolutional layers, followed by one average pooling layer and one linear layer. In practice, we only attach classifiers to some of the intermediate layers, and we let fk(.) denote the kth classifier.
•anytime prediction : During testing in the anytime setting we propagate the input through the network until the budget is exhausted and output the most recent prediction.
•batch budget classification : In the batch budget setting at test time, an example traverses the network and exits after classifier fk if its prediction confidence (we use the maximum value of the softmax probability as a confidence measure) exceeds a pre-determined threshold k
Experiment result
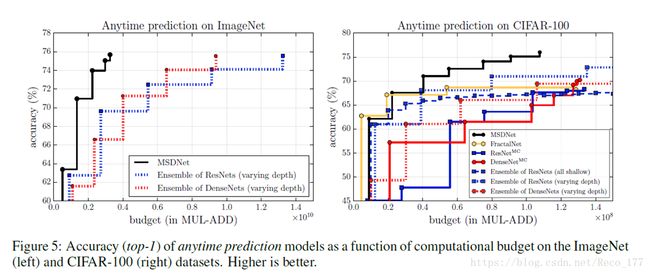
•Anytime Prediction:左边是在InageNet(2012)数据集上的结果,右边是在CIFAR-100数据集上的结果。横坐标就是computational budget,也就是计算复杂度的标识。

•Budgeted Batch Classification:右图包含3条不同网络深度的MSDNet结果,可以看出在average budget比较小的时候,MSDNet的效果要远远好于ResNet和DenseNet.