精通安卓性能优化-第三章(二)
颜色转换
在图形程序中一个通用的操作是将颜色从一种格式转换成另外一种。比如,32位的值代表的颜色,有4个8位的通道(alpha, red, green, blue)可以被转换为16位的值,带有3个通道(5位代表红色,6位代表绿色,5位代表蓝色,没有alpha)。这两种格式通常被称为分别称为ARGB8888和RGB565。
Listing 3-11给出了这样一个转换的通常实现
Listing 3-11 实现颜色转换功能
unsigned int argb888_to_rgb565 (unsigned int color)
{
/*
input: aaaaaaaarrrrrrrrggggggggbbbbbbbb
output: 000000000000000rrrrrggggggbbbbb
*/
return
/* red */ ((color >> 8) & 0xF800) |
/* green */ ((color >> 5) & 0x07E0) |
/* blue */ ((color >> 3) & 0x001F);
}再次,5段汇编代码可以被分析。Listing 3-12给出了x86汇编代码,Listing 3-13给出了ARM模式的ARMv5汇编代码,Listing 3-14给出了ARM模式的ARMv7代码,Listing 3-15给出了Thumb模式的ARMv5代码,Listing 3-16给出了Thumb模式下的ARMV7代码。
Listing 3-12 x86汇编代码

Listing 3-13 ARMv5汇编代码(ARM模式)
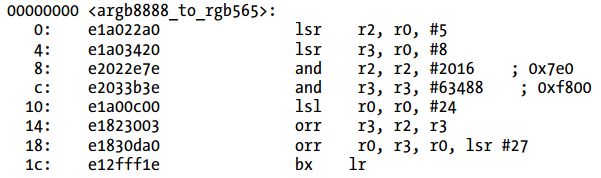
Listing 3-14 ARMv7汇编代码(ARM模式)
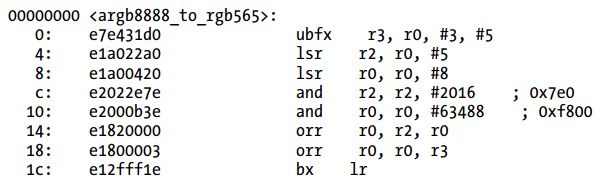
Listing 3-15 ARMv5汇编代码(Thumb模式)
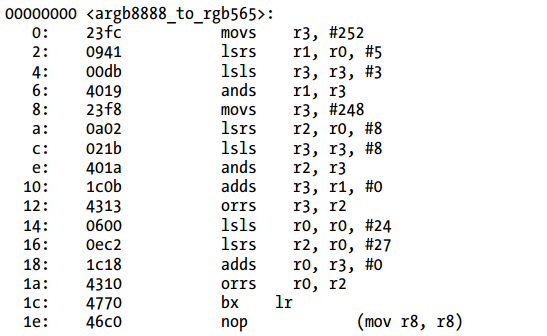
Listing 3-16 ARMv7 汇编代码(Thumb模式)

简单的观察产生了多少指令,Thumb模式下的ARMv5代码是最低效的。也就是说,计算指令的数量不是决定一段代码执行速度快慢的精确方式。为了得到一个更接近的估计,需要去计算每个指令完成需要多少个周期。比如,”orr r3, r2”指令仅需要一个周期。现在的CPU使得计算最终需要多少个周期很困难,因为他们可以一个周期执行多条指令,甚至有些情况下不按顺序执行指令以最大化吞吐量。
NOTE: 比如,参考Cortex-A9技术手册去学习指令周期的更多。
现在可以写一个稍有不同的版本去实现同样的转换函数,使用UBFX和BFI指令,如Listing 3-17所示。Listing 3-17 手写汇编代码
.global argb8888_to_rgb565_asm
.func argb8888_to_rgb565_asm
argb8888_to_rgb565_asm:
// r0=aaaaaaaarrrrrrrrggggggggbbbbbbbb
// r1=undefined (scratch register)
ubfx r1, r0, #3, #5
// r1=000000000000000000000000000bbbbb
lsr r0, r0, #10
// r0=0000000000aaaaaaaarrrrrrrrgggggg
bfi r1, r0, #5, #6
// r1=000000000000000000000ggggggbbbbb
lsr r0, r0, #9
// r0=0000000000000000000aaaaaaaarrrrr
bfi r1, r0, #11, #5
// r1=0000000000000000rrrrrggggggbbbbb
mov r0, r1
// r0=0000000000000000rrrrrggggggbbbbb
bx lr
.endfunc
.end因为代码使用到了UBFX和BFI指令(都在ARMv6T2架构引入),将不能编译为armeabi ABI(ARMv5)。显然的,它也不可以编译为x86 ABI。
和Listing 3-9相似,你的Android.mk需要保证文件使用正确的ABI编译。Listing 3-18给出了需要添加的rgb.c和rgb_asm.S文件。
Listing 3-18 Android.mk
LOCAL_PATH := $(call my-dir)
include $(CLEAR_VARS)
LOCAL_MODULE := chapter3
LOCAL_SRC_FILES := gcd.c rgb.c
ifeq ($(TARGET_ARCH_ABI), armeabi)
LOCAL_SRC_FILES += gcd_asm.S
endif
ifeq ($(TARGET_ARCH_ABI), armeabi-v7a)
LOCAL_SRC_FILES += gcd_asm.S rgb_asm.S
endif
include $(BUILD_SHARED_LIBRARY)如果你将rgb_asm.S添加到armeabi ABI的列表,将得到如下的Error:
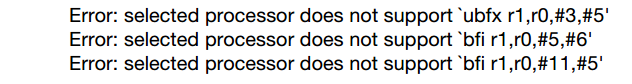
平均值并行计算
在这个例子中,我们将32位的值作为4个独立的8位数值运算,以字节为单位运算两个值的平均值。比如,0x10FF3040和0x50FF7000的平均值是0x30FF5020(0x10和0x50的平均值是0x30, 0xFF和0xFF的平均值是0xFF)。
Listing 3-19给出这种功能的一个实现:
Listing 3-19 实现并行计算
unsigned int avg8 (unsigned int a, unsigned int b)
{
return
((a >> 1) & 0x7F7F7F7F) +
((b >> 1) & 0x7F7F7F7F) +
(a & b & 0x01010101);
}就像之前的两个示例,Listing 3-20到Listing 3-24给出了5段汇编代码。
Listing 3-20 x86汇编代码

Listing 3-21 ARMv5汇编代码(ARM模式)
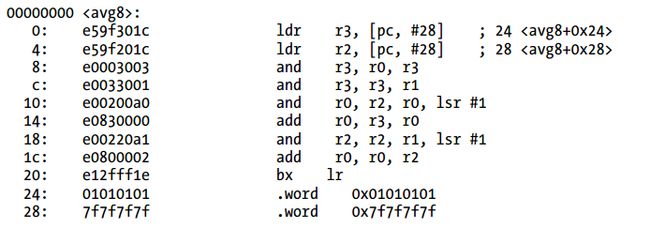
因为ARMv5的MOV指令不支持简单的将值拷贝到寄存器,使用LDR指令去复制0x01010101到寄存器r3。相似的,另外一个LDR指令用来拷贝0x7f7f7f7f到r2。
Listing 3-22 ARMv7汇编代码(ARM模式)
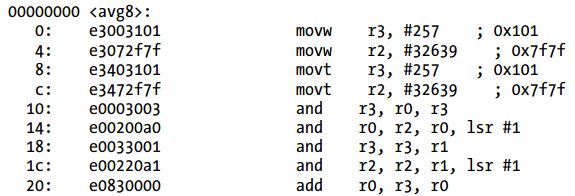
![]()
ARMv7使用两个MOV指令而不是LDR指令将0x01010101复制到r3:第一个MOVW用来拷贝一个16位的值(0x0101)到r3的低16位;第二个,MOVT拷贝0x0101到r3的高16位。在这两个指令之后,r3实际上包含0x01010101。剩余的代码和ARMv5的汇编代码相似。
Listing 3-23 ARMv5汇编代码(Thumb模式)
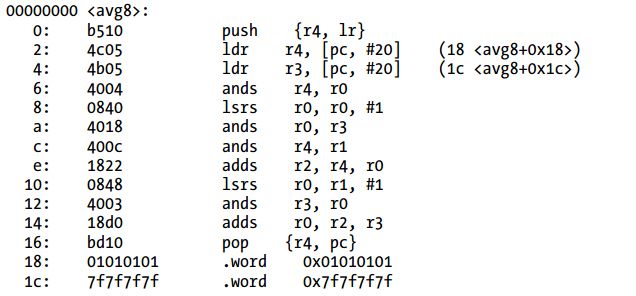
因为这段代码利用了r4寄存器,需要保存到栈上稍后恢复。
Listing 3-24 ARMv7汇编代码(Thumb模式)

Thumb2汇编代码更加紧凑,拷贝0x01010101和0x7f7f7f7f到r3和r0仅需要一个指令。
在决定写优化的汇编代码之前,你需要停下来想一下C代码本身如何被优化。在一段时间的思考后,你最终的代码如Listing 3-25所示。
Listing 3-25 平均值并行计算的更快实现

C代码比第一版更加紧凑,而且运行速度更快。第一版用到了两个>>,4个&,和两个+操作符(共有8个基本操作符),新版只有5个基本操作符。直觉上第二种实现更快。实际上也是这样。
Listing 3-26给出了ARMv7 Thumb汇编代码。
Listing 3-26 ARMv7汇编代码(Thumb模式)

更快的实现导致更快的更紧凑的代码(不包括从函数中返回的指令,4个指令而不是8个)。
尽管这听起来很了不起,更加深入的去看ARM指令揭示了UHADD8指令,可以执行以无符号字节为单位的加操作,使结果缩到了一半。这种情况正是我们想要计算的。结果,一个更快的实现可以简单的实现,如Listing 3-27所示。
Listing 3-27 手写汇编代码
.global arg8_asm
.func avg8_asm
avg8_asm:
uhadd8 r0, r0, r1
bx lr
.endfunc
.end其他的并行指令存在。比如,UHADD16比较像UHADD8,不过以半个字为单位计算加操作而不是字节为单位。这些指令可以显著的提升性能,但是因为编译器很少使用它们产生代码,为了利用他们,经常需要手动去写这些汇编代码。
NOTE:并行指令在ARMv6引入,所以你不可以在为armeabi ABI(ARMv5)编译的时候使用它们。
使用汇编代码写整个函数将会很快变得乏味。在许多情况下,仅部分代码会从使用汇编受益,其他的可以用C或者C++写。GCC编译器允许你混合C/C++和汇编,如Listing 3-28所示。
Listing 3-28 C代码混合汇编代码

NOTE: 参考http://gcc.gnu.org/onlinedocs/gcc/Extended-Asm.html关于asm更多的信息和http://gcc.gnu.org/onlinedocs/gcc/Constraints.html关于常量的细节。一个asm()语句块可以包含多个指令。
更新后的Android.mk如Listing 3-29所示。
Listing 3-29 Android.mk

这个示例表示,为了达到最好的性能有时候对指令集的很好的理解是必须的。因为安卓设备大多数基于ARM架构,你需要集中你的注意力在ARM指令集。ARM网站的ARM文档(infocenter.arm.com)质量很高,所以使用它吧。