【AI视野·今日CV 计算机视觉论文速览 第178期】Fri, 17 Jan 2020
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 17 Jan 2020
Totally 62 papers
上期速览✈更多精彩请移步主页

Interesting:
****图像分割综述, (from NYU et.al)
//作者们:
https://personal.utdallas.edu/~kehtar/
http://web.cs.ucla.edu/~dt/
https://www.umbc.edu/rssipl/people/aplaza/
http://www.porikli.com/
segmentation: http://www.csd.uwo.ca/~yuri/index.html
https://sites.google.com/site/shervinminaee/home
***参数化图像提升方法, (from Tel Aviv University facebook)

**MeliusNet二进制神经网络超过MobileNet, (from 波茨坦大学 阿里巴巴 )
**Wi2V基于wifi信号生成视频, (from Amirkabir University of Technology Iran)
三维位置估计, (from Technical University of Berlin 柏林)
自动驾驶中天气扰动的影响, (from IIT 印度)
**PDANet基于金字塔的人群计数方法, (from University of Technology Sydney)
SketchDesc基于草图的局域多视角描述子学习, (from 香港城市大学)
基于残差注意力的细胞边缘检测和分割, (from 哥伦比亚大学)
多源数据融合框架
逆问题的相关论文:
Learning Inverse Depth Regression
Computational Mirrors

Inverse Graphics

Solving Forward and Inverse Problems Using Autoencoders
Learned SVD: solving inverse problems via hybrid autoencoding
The troublesome kernel: why deep learning for inverse problems is typically unstable
Deep Learning-based Solvability of Underdetermined Inverse Problems
Daily Computer Vision Papers
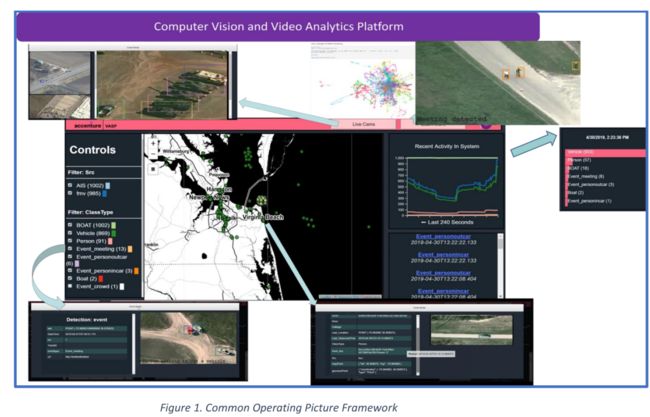
| A Common Operating Picture Framework Leveraging Data Fusion and Deep Learning Authors Benjamin Ortiz, David Lindenbaum, Joseph Nassar, Brendan Lammers, John Wahl, Robert Mangum, Margaret Smith, Marc Bosch 组织开始意识到数据和数据驱动算法模型的结合功能,以获取洞察力,态势感知并推进其任务。获得见解的一个常见挑战是连接固有的不同数据集。这些数据集例如地理编码功能,视频流,原始文本,社交网络数据等分别提供了非常狭窄的答案,但是它们可以共同提供新功能。在这项工作中,我们提出了一个数据融合框架,用于加速处理,开发和传播PED解决方案。我们的平台是一个服务集合,可通过利用深度学习和其他处理方式从多个数据源中分别提取信息。此信息由一组分析引擎合并,这些引擎执行数据关联,搜索和其他建模操作,以合并来自不同数据源的信息。结果,感兴趣的事件被检测,地理定位,记录并呈现为共同的操作画面。这种通用的操作画面使用户可以实时地可视化所有数据源,每个数据源都是单独的以及它们的集体协作。此外,法医活动已经实施并通过该框架提供。用户可以查看存档的结果,并将其与操作环境的最新快照进行比较。在我们的第一次迭代中,我们专注于视觉数据FMV,WAMI,CCTV PTZ摄像机,开源视频等,以及AIS数据流卫星和地面源。作为概念的证明,在我们的实验中,我们展示了如何将FMV检测与来自AIS来源的船只跟踪信号相结合,以确认身份,进行提示和提示空中侦察,并监视区域中的船只活动。 |
| Contextual Sense Making by Fusing Scene Classification, Detections, and Events in Full Motion Video Authors Marc Bosch, Joseph Nassar, Benjamin Ortiz, Brendan Lammers, David Lindenbaum, John Wahl, Robert Mangum, Margaret Smith 随着成像传感器的激增,多模式成像的数量远远超过了人类分析者充分利用和利用它的能力。全动态视频FMV面临的挑战是包含大量冗余时间数据。我们旨在满足人类分析师使用空中FMV来消费和利用数据的需求。我们已经研究并设计了一种系统,该系统能够检测与给定的FMV进给值偏离观察的基线模式的事件和活动。我们已将问题分为三个任务:上下文感知,2对象分类和3事件检测。上下文感知的目的是限制视频数据中的视觉搜索和检测问题。自定义图像分类器使用一个或多个标签对场景进行分类,以标识操作上下文和环境。此步骤有助于减少下游任务的语义搜索空间,以提高其准确性。第二步是对象分类,其中一组对象检测器定位并标记在场景中发现的人,车辆,船,飞机,建筑物等中的任何已知对象。最后,上下文信息和检测信息将发送到事件检测引擎,以监视某些行为。一系列分析通过跟踪对象计数和对象交互来监视场景。如果未声明这些对象交互在当前场景中普遍可见,则系统将报告,地理定位和记录事件。感兴趣的事件包括识别聚会或人群的聚会,在海滩上有船卸下货物时发出警报,进入建筑物的人数增加,人们进出感兴趣的车辆的人数等等。已将我们的方法应用于来自不同地理区域的不同分辨率的不同传感器的数据。 |
| Continual Learning for Domain Adaptation in Chest X-ray Classification Authors Matthias Lenga, Heinrich Schulz, Axel Saalbach 在过去的几年中,深度学习已成功应用于广泛的医疗应用中。尤其是在胸部X射线分类的情况下,已报道的结果与经验丰富的放射科医生相当,甚至更高。尽管在受控的实验环境中取得了成功,但已经注意到,深度学习模型将来自具有潜在不同任务的新域中的数据概括化的能力通常受到限制。为了解决这一挑战,我们研究了持续学习CL领域的技术,包括联合训练JT,弹性重量合并EWC和“学习不忘LWF”。使用ChestX ray14和MIMIC CXR数据集,我们从经验上证明了这些方法提供了有希望的选择,以改善目标域上的深度学习模型的性能并有效缓解源域的灾难性遗忘。为此,使用JT可获得最佳的整体性能,而对于LWF,即使不从源域访问数据也可以取得竞争性结果。 |
| Assessing Robustness of Deep learning Methods in Dermatological Workflow Authors Sourav Mishra, Subhajit Chaudhary, Hideaki Imaizumi, Toshihiko Yamasaki 本文旨在评估当前深度学习方法对临床工作流程的适用性,尤其是关注皮肤病学。尽管尝试了深度学习方法以在几种单独的情况下获得皮肤科医生水平的准确性,但尚未针对常见的临床不适进行严格的测试。大多数项目都涉及在良好控制的实验室条件下获取的数据。在相应的图像质量并不总是理想的情况下,这可能无法反映出常规的临床评估。我们通过在十种疾病的用户提交图像上模拟非理想特征来测试深度学习方法的鲁棒性。通过模拟条件进行评估,尽管训练有素,但在许多情况下,我们发现整体准确性下降,并且各个预测都发生了显着变化。 |
| Show, Recall, and Tell: Image Captioning with Recall Mechanism Authors Li Wang, Zechen Bai, Yonghua Zhang, Hongtao Lu 在图像字幕中生成自然而准确的描述一直是一个挑战。在本文中,我们提出了一种新颖的召回机制,以模仿人类行为字幕的方式。我们的召回机制召回单元包括三个部分:语义指南SG和被召回的单词槽RWS。召回单元是文本检索模块,旨在检索图像的召回词。 SG和RWS的设计旨在最大程度地利用召回的单词。 SG分支可以生成召回的上下文,这可以指导字幕的生成过程。 RWS分支负责将调用的单词复制到标题。通过在文本摘要中指出机制的启发,我们采用了一种软开关来平衡SG和RWS之间生成的单词概率。在CIDEr优化步骤中,我们还引入了一个个体化的单词奖励WR来增强训练。我们建议的SG RWS WR方法在MSCOCO Karpathytest分割上实现BLEU 4 CIDEr SPICE得分为36.6 116.9 21.3(具有交叉熵损失)和38.7 129.1 22.4(具有CIDEr优化),这超过了其他方法的结果。 |
| Filter Grafting for Deep Neural Networks Authors Fanxu Meng, Hao Cheng, Ke Li, Zhixin Xu, Rongrong Ji, Xing Sun, Gaungming Lu 本文提出了一种称为过滤器嫁接的新学习范例,旨在提高深度神经网络DNN的表示能力。动机是DNN具有不重要的无效过滤器,例如l1范数接近0。这些过滤器限制了DNN的潜力,因为它们被认为对网络影响不大。尽管出于效率考虑,过滤器修剪会删除这些无效的过滤器,但从提高精度的角度来看,过滤器嫁接会重新激活它们。通过将外部信息权重移植到无效过滤器中来处理激活。为了更好地执行嫁接过程,我们开发了一种基于熵的标准来测量过滤器的信息,并提出了一种自适应加权策略来平衡网络之间的嫁接信息。嫁接操作之后,与原始状态相比,网络具有很少的无效过滤器,从而为模型提供了更多的表示能力。我们还对分类和识别任务进行了广泛的实验,以证明我们方法的优越性。例如,在CIFAR 100数据集上,嫁接的MobileNetV2优于非嫁接的MobileNetV2约7%。 |
| Ensemble based discriminative models for Visual Dialog Challenge 2018 Authors Shubham Agarwal, Raghav Goyal 这份手稿描述了我们为Visual Dialog Challenge 2018设计的方法。在最终提交中,我们使用三个具有区别的编码器和解码器的判别模型的集合。我们在测试标准分割上表现最好的模型获得了NDCG得分55.46和MRR值63.77,在挑战赛中排名第三。 |
| Weakly Supervised Video Summarization by Hierarchical Reinforcement Learning Authors Yiyan Chen, Li Tao, Xueting Wang, Toshihiko Yamasaki 传统的基于强化学习的视频总结方法存在的问题是,只有在生成整个总结后才能获得奖励。这种奖励很少,并且使强化学习难以融合。另一个问题是标记每个帧很繁琐且成本高昂,这通常会禁止构建大规模数据集。为了解决这些问题,我们提出了一个弱监督的层次强化学习框架,该框架将整个任务分解为几个子任务,以提高摘要质量。该框架由管理者网络和工作者网络组成。对于每个子任务,管理人员仅通过任务级别的二进制标签来训练设置子目标,与常规方法相比,该标签需要的标签要少得多。在子目标的指导下,工作人员可以根据全局奖励和创新的定义子奖励来通过策略梯度来预测子任务中视频帧的重要性分数,以克服稀疏问题。在两个基准数据集上进行的实验表明,我们的建议取得了最佳性能,甚至优于监督方法。 |
| An Investigation of Feature-based Nonrigid Image Registration using Gaussian Process Authors Siming Bayer, Ute Spiske, Jie Luo, Tobias Geimer, William M. Wells III, Martin Ostermeier, Rebecca Fahrig, Arya Nabavi, Christoph Bert, Ilker Eyupoglo, Andreas Maier 对于诸如自适应治疗计划或术中图像更新等广泛的临床应用,基于特征的可变形配准FDR方法由于其简单性和低计算复杂性而被广泛采用。 FDR算法通过内插稀疏场来估计密集位移场,稀疏场由选定特征之间已建立的对应关系给出。在本文中,我们将变形场视为高斯过程GP,而将所选特征视为有效变形的先验信息。使用GP,我们能够同时估计密集位移场和相应的不确定度图。此外,我们分别使用合成,幻像和临床数据评估平方指数内核的不同超参数设置的性能。定量比较表明,基于GP的插值具有与最新的B样条插值相同的性能。基于GP的插值的最大临床好处是,它可以可靠地估计所计算的密集位移图的数学不确定性。 |
| Deep learning achieves perfect anomaly detection on 108,308 retinal images including unlearned diseases Authors Ayaka Suzuki, Yoshiro Suzuki 光学相干断层扫描OCT扫描可用于检测各种视网膜疾病。但是,在世界许多地方,没有足够的眼科医生可以诊断视网膜OCT图像。为了廉价且广泛地提供OCT筛查,自动化诊断系统是必不可少的。尽管已经提出了许多机器学习技术来协助眼科医生诊断视网膜OCT图像,但是没有一种技术可以在不依赖眼科医生的情况下进行独立诊断,即没有一种技术可以不忽视任何异常现象,包括未经学习的疾病。只要存在使用某种技术忽视疾病的风险,眼科医生甚至必须仔细检查该技术分类为正常的图像。在这里,我们表明基于深度学习的二元分类器正常或异常在108,308个二维视网膜OCT图像上实现了完美分类,即真实正率1.000000和真实负率1.000000,因此ROC曲线下的面积为1.0000000。尽管测试集包括三种类型的疾病,但其中两种没有用于训练。但是,所有测试图像均已正确分类。此外,我们证明了我们的方案能够应对患者种族的差异。没有常规的方法可以达到上述性能。我们的工作有足够的可能性将视网膜OCT图像的自动诊断技术从眼科医生的助手提升到没有眼科医生的独立诊断系统。 |
| The problems with using STNs to align CNN feature maps Authors Lukas Finnveden, Ylva Jansson, Tony Lindeberg 空间转换器网络STN旨在使CNN能够学习图像变换的不变性。最初建议使用STN来转换CNN特征图以及输入图像。这样可以在预测转换参数时使用更复杂的功能。但是,由于STN仅执行空间变换,因此通常情况下,它们不具有将变换后的图像及其原始图像的特征图对齐的能力。我们为此提供了一个理论上的论据并调查了实际的含义,表明这种无用性与降低的分类精度相结合。我们主张通过在分类和本地化网络之间共享参数来利用更深层中更复杂的功能。 |
| The Effect of Data Ordering in Image Classification Authors Ethem F. Can, Aysu Ezen Can 深度学习模型的成功案例每天都在增加,涉及从图像分类到自然语言理解的不同任务。随着这些模型的日益普及,科学家们花费越来越多的时间来寻找适合其任务的最佳参数和最佳模型架构。在本文中,我们将重点放在为这些机器提供数据的要素上。我们假设数据排序会影响模型的性能。为此,我们使用ImageNet数据集对图像分类任务进行了实验,结果表明,在获得更高分类精度方面,某些数据排序要优于其他数据排序。实验结果表明,与模型架构,学习率和批处理大小无关,数据的排序会显着影响结果。我们使用不同的度量NDCG,准确度1和准确度5显示这些发现。我们的目标是证明不仅参数和模型架构,而且数据排序在获取更好的结果方面都有发言权。 |
| Domain Independent Unsupervised Learning to grasp the Novel Objects Authors Siddhartha Vibhu Pharswan, Mohit Vohra, Ashish Kumar, Laxmidhar Behera 基于视觉的抓握中的主要挑战之一是在与新颖物体相互作用时选择可行的抓握区域。最近的方法利用卷积神经网络CNN的功能来实现准确的掌握,但要付出高计算能力和时间的代价。在本文中,我们提出了一种新颖的基于无监督学习的算法,用于选择可行的抓握区域。无监督学习可以推断出数据集中的模式,而无需任何外部标签。我们在图像平面上应用k均值聚类以识别抓握区域,然后采用轴分配方法。我们定义了“抓握决策指数GDI”的新概念,以选择图像平面中的最佳抓握姿势。我们已经在杂乱或孤立的环境中对Amazon Robotics Challenge 2017和Amazon Picking Challenge 2016的标准对象进行了多次实验。我们将结果与基于先前学习的方法进行了比较,以验证我们算法对多种新颖对象的鲁棒性和自适应性。不同的域。 |
| Deep Learning Enabled Uncorrelated Space Observation Association Authors Jacob J Decoto, David RC Dayton 不相关的光学空间观测协会代表大海捞针问题的经典代表。目的是从所有不相关的观测值的大得多的人群中找到可能属于相同驻地空间目标RSO的一小组观测值。这些观察可能在时间上以及相对于观察传感器位置有很大的不同。通过在大型代表性数据集上进行训练,本文表明,无需物理或轨道力学编码知识即可使用深度学习的学习模型可以学习用于识别常见物体观测的模型。当显示具有50个匹配观察对的平衡输入集时,学习的模型能够正确识别观察对是否在同一时间的RSO 83.1。然后将所得的学习模型与搜索算法结合使用,在不平衡的演示集(包含1000个不同的模拟不相关观察值)上进行展示,并被证明能够成功识别代表人口总数142个对象中的111个的真实的三个观察集。在三个观察三元组中识别大多数对象。这是在仅探索1.66e8可能的唯一三元组组合的搜索空间的0.06时完成的。 |
| Identifying Table Structure in Documents using Conditional Generative Adversarial Networks Authors Nataliya Le Vine, Claus Horn, Matthew Zeigenfuse, Mark Rowan 例如,在许多行业以及学术研究中,信息主要以非结构化文档的形式传输。层次结构相关的数据呈现为表格,而从此类文档中的表格中提取信息提出了重大挑战。许多现有方法采用自下而上的方法,首先将线集成到单元中,然后将单元集成到行或列中,最后从所得的2D布局中推断出结构。但是这样的方法忽略了与表结构有关的可用先验信息,即表只是潜在逻辑结构的任意表示。我们提出了一种自上而下的方法,首先使用条件生成对抗网络将表格图像映射到表示没有表格内容的近似行和列边界的标准化骨架表格形式,然后使用xy切割投影和遗传算法优化来推导潜在表格结构。该方法很容易适应不同的表配置,并且需要较小的数据集大小进行培训。 |
| TBC-Net: A real-time detector for infrared small target detection using semantic constraint Authors Mingxin Zhao, Li Cheng, Xu Yang, Peng Feng, Liyuan Liu, Nanjian Wu 红外小目标检测是红外搜索和跟踪IRST系统中的一项关键技术。尽管近来深度学习已广泛用于可见光图像的视觉任务中,但由于难以学习小目标特征,因此很少用于红外小目标检测。在本文中,我们提出了一种新型的轻型卷积神经网络TBC网络用于红外小目标检测。 TBCNet由目标提取模块TEM和语义约束模块SCM组成,它们分别用于从红外图像中提取小目标并在训练过程中对提取的目标图像进行分类。同时,我们提出了关节损失函数和训练方法。 SCM通过结合高级分类任务对TEM施加语义约束,解决了类不平衡问题导致的特征学习困难的问题。在训练期间,从输入图像中提取目标,然后由SCM对目标进行分类。在推断过程中,仅使用TEM来检测小目标。我们还提出了一种数据综合方法来生成训练数据。实验结果表明,与传统方法相比,TBC Net可以更好地减少背景复杂造成的虚警,所提出的网络结构和联合损失对小目标特征学习有明显的改善。此外,TBC Net可以在NVIDIA Jetson AGX Xavier开发板上实现实时检测,适用于诸如带有红外传感器的无人机的现场研究等应用。 |
| Embedding of FRPN in CNN architecture Authors Alberto Rossi, Markus Hagenbuchner, Franco Scarselli, Ah Chung Tsoi 本文将用于矢量输入的完全递归感知器网络FRPN模型扩展到包括可以接受多维输入的深度卷积神经网络CNN。 FRPN由递归层组成,递归层在给定固定输入的情况下,迭代计算平衡状态。通过这种迭代机制实现的展开可以模拟具有任意数量层的深度神经网络。 FRPN到CNN的扩展形成了一种架构,我们称之为卷积FRPN C FRPN,其中卷积层是递归的。在几种图像分类基准上对该方法进行了评估。结果表明,C FRPN始终优于具有相同数量参数的标准CNN。对于小型网络,性能上的差距特别大,这表明C FRPN是一种非常强大的体系结构,因为与深度CNN相比,它可以用较少的参数获得等效的性能。 |
| Application of Deep Learning in Generating Desired Design Options: Experiments Using Synthetic Training Dataset Authors Zohreh Shaghaghian, Wei Yan 大多数设计方法都包含一个前向框架,该框架要求建筑物的主要规格以生成输出或评估其性能。但是,尽管不确定适当的设计参数,但建筑师仍要求实现特定目标。深度学习DL算法提供了智能的工作流程,系统可以在其中从顺序的训练实验中学习。本研究将使用DL算法的方法应用于生成所需的设计选项。在这项研究中,研究对象识别问题以基于包含不同类型的合成2D形状的训练数据集初步预测看不见的样本图像的标签,然后将生成的DL算法应用于训练并为给定标签生成新形状。在下一步中,将训练算法,以基于空间日光自主性sDA度量为所需的光影性能生成窗墙图案。实验表明,在预测看不见的样品形状和生成新的设计选项方面都具有可喜的结果。 |
| Translating multispectral imagery to nighttime imagery via conditional generative adversarial networks Authors Xiao Huang, Dong Xu, Zhenlong Li, Cuizhen Wang 夜间卫星图像已被广泛应用。但是,我们对观察到的光强度是如何形成的以及是否可以模拟的了解有限,这极大地阻碍了它的进一步应用。这项研究探索了条件生成对抗网络cGAN在将多光谱图像转换为夜间图像方面的潜力。采用了流行的cGAN框架pix2pix并对其进行了修改,以使用来自Landsat 8和可见红外成像辐射计套件VIIRS的网格化训练图像对来促进此转换。这项研究的结果证明了将多光谱图像转换为夜间图像的可能性,并进一步表明,通过附加的社交媒体数据,生成的夜间图像可能与地面真实图像非常相似。这项研究填补了了解卫星观测到的夜间光的空白,并提供了新的范例来解决夜间遥感领域中出现的新问题,包括夜间序列构造,光去饱和和多传感器校准。 |
| End-to-End Pixel-Based Deep Active Inference for Body Perception and Action Authors Cansu Sancaktar, Pablo Lanillos 我们提出了一种基于像素的深度主动推理算法PixelAI,该算法启发了人体感知并成功地验证了机器人的人体感知和动作(作为用例)。我们的算法结合了源于变分推理的神经科学自由能原理和深度卷积解码器来对算法进行缩放,以直接处理图像输入并提供在线自适应推理。该方法使机器人仅使用原始的单眼摄像机图像即可执行1次手臂的动态人体估计,并自动执行2次操作以达到视觉空间中想象的手臂姿势。我们对模拟的和真实的Nao机器人的算法性能进行了统计分析。结果表明,相同的算法如何处理两种感知到的动作,建模为推理优化问题。 |
| Does Time-Delay Feedback Matter to Small Target Motion Detection Against Complex Dynamic Environments? Authors Hongxin Wang, Huatian Wang, Jiannan Zhao, Cheng Hu, Jigen Peng, Shigang Yue 对于通常受限于计算能力的自主微型机器人,在复杂的视觉环境中区分小运动物体是一项重大挑战。依靠良好发展的视觉系统,尽管目标视野的大小只有几个像素,但飞行昆虫可以毫不费力地检测到配偶并快速追踪猎物。这种对小目标运动的灵敏性被称为“小目标运动检测器” STMD的一类专门的神经元所支持。现有的基于STMD的模型通常由通过前馈回路互连的四个顺序排列的神经层组成,以从原始视觉输入中提取有关小目标的运动信息。但是,反馈回路是运动感知的另一个重要调节电路,尚未在STMD通路中进行研究,其在小目标运动检测中的功能作用尚不清楚。在本文中,我们假设存在反馈,并提出了一种基于STMD的视觉系统,该系统具有反馈连接Feedback STMD,其中系统输出在时间上有所延迟,然后反馈到较低的层以介导神经反应。我们比较了带有和不带有延时反馈回路的视觉系统的特性,并讨论了其对小目标运动检测的影响。实验结果表明,反馈STMD更喜欢快速移动的小目标,同时可以显着抑制那些以较低速度移动的背景特征。 |
| An Analytical Workflow for Clustering Forensic Images Authors Sara Mousavi, Dylan Lee, Tatianna Griffin, Dawnie Steadman, Audris Mockus 如果精选了大量的图像,则可以极大地提高许多领域的研究质量。无监督聚类是管理此类数据集的直观而有效的步骤。在这项工作中,我们提出了一种用于无监督地对大量取证图像进行聚类的工作流。除了与领域相关的数据,工作流还利用图像深度特征表示的经典聚类将它们分组在一起。我们的手动评估显示所得簇的纯度为89。 |
| Adversarial Example Generation using Evolutionary Multi-objective Optimization Authors Takahiro Suzuki, Shingo Takeshita, Satoshi Ono 本文提出了一种基于进化多目标优化EMO的对抗示例AE设计方法,该方法在黑盒设置下执行。先前的基于梯度的方法通过更改目标图像的所有像素来生成AE,而先前的基于EC的方法则更改少量像素以生成AE。由于EMO具有基于种群的搜索特性,因此该方法可生成各种类型的AE,其中包括位于前两种方法生成的AE之间的AE,这有助于了解目标模型的特征或了解未知的攻击模式。实验结果表明了该方法的潜力,例如,它可以生成鲁棒的AE,并且借助基于DCT的扰动图生成,可以生成高分辨率图像的AE。 |
| Supervised and Unsupervised Learning of Parameterized Color Enhancement Authors Yoav Chai, Raja Giryes, Lior Wolf 我们将色彩增强问题视为图像翻译任务,我们使用监督学习和无监督学习来解决。与传统图像到图像生成器不同,我们的翻译是使用全局参数化颜色转换执行的,而不是学习直接映射图像信息。在监督的情况下,每个训练图像都与所需的目标图像配对,而卷积神经网络CNN从专家修饰的图像中学习变换的参数。在不成对的情况下,我们采用两种方式的生成对抗网络GAN来学习这些参数并应用圆度约束。与MIT Adobe FiveK基准上的监督配对数据和非监督非配对数据图像增强方法相比,我们获得了最先进的结果。此外,通过将其应用于20世纪初的照片和深色视频帧,我们展示了该方法的泛化能力。 |
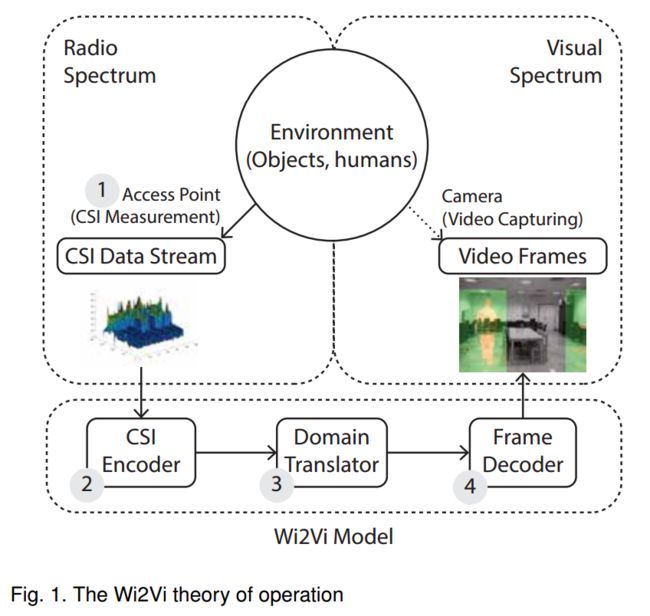
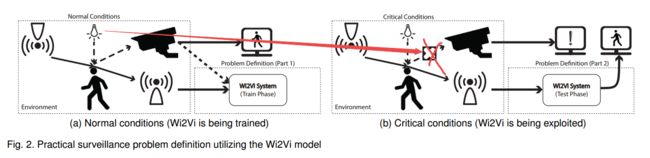
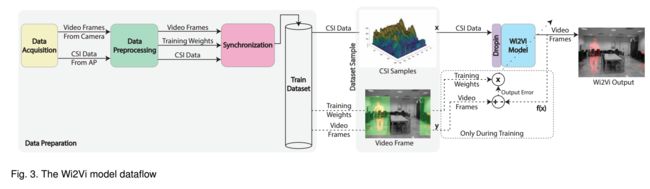
| Wi2Vi: Generating Video Frames from WiFi CSI Samples Authors Mohammad Hadi Kefayati, Vahid Pourahmadi, Hassan Aghaeinia 环境中的物体会影响电磁波。尽管此影响随频率而变化,但它们之间存在相关性,并且具有足够容量的模型可以捕获不同频率下的测量之间的这种相关性。在本文中,我们提出了Wi2Vi模型,用于将WiFi通道状态信息的变化与视频帧相关联。提出的Wi2Vi系统可以完全使用CSI测量来生成视频帧。 Wi2Vi产生的视频帧在紧急情况下为常规监视系统提供了辅助信息。我们对Wi2Vi系统的实施证实了构建能够推导不同频谱中的测量之间的相关性的系统的可行性。 |
| Predicting population neural activity in the Algonauts challenge using end-to-end trained Siamese networks and group convolutions Authors Georgin Jacob, Harish Katti Algonauts面临的挑战是关于以来自视觉大脑区域的代表性相异矩阵RDMS的形式预测对象表示。我们使用暹罗网络和群卷积的概念使用了定制的深度学习模型,以预测与一对图像相对应的神经距离。训练数据最好通过最后一层计算出的距离来解释。 |
| Multi-Layer Content Interaction Through Quaternion Product For Visual Question Answering Authors Lei Shi, Shijie Geng, Kai Shuang, Chiori Hori, Songxiang Liu, Peng Gao, Sen Su 近年来,多模态融合技术极大地提高了基于神经网络的视频描述字幕,视觉问答VQA和视听场景感知对话框AVSD的性能。先前的大多数方法仅探索多层特征融合的最后一层,而忽略了中间层的重要性。为了解决中间层的问题,我们提出了一种有效的四元数块网络QBN,不仅可以学习最后一层的交互,还可以同时学习所有中间层的交互。在我们提出的QBN中,我们使用整体文本功能来指导视觉功能的更新。同时,汉密尔顿四元数产品可以有效地执行从高层到较低层的视觉和文本形式的信息流。评估结果表明,即使使用了超过大规模BERT或可视BERT预先训练的模型,我们的QBN仍改进了VQA 2.0的性能。已经进行了广泛的消融研究,以证明本研究中每个提出的模块的影响。 |
| Discoverability in Satellite Imagery: A Good Sentence is Worth a Thousand Pictures Authors David Noever, Wes Regian, Matt Ciolino, Josh Kalin, Dom Hambrick, Kaye Blankenship 小型卫星星座每天提供对地球陆地的全球覆盖,但是图像丰富化依赖于自动化关键任务(例如变化检测或特征搜索)。例如,要从原始像素提取文本注释,需要两个相关的机器学习模型,一个用于分析开销图像,另一个用于生成描述性字幕。我们根据以前最大的卫星图像字幕基准评估了七个模型。我们将标记的图像样本扩展五倍,然后增加,校正和修剪词汇表以达到大致的最小最大最小单词,最大描述。与以前使用大型预先训练的图像模型进行的工作相比,此结果是有利的,但是当使用对数熵损失进行测量时,模型尺寸减小了一百倍,而不会牺牲整体精度。这些较小的模型提供了新的部署机会,尤其是当推到边缘处理器,人造卫星或分布式地面站时。为了量化字幕的描述性,我们引入了一种新颖的多类混淆或错误矩阵来对人类标记的测试数据和从未标记的图像(包括边界框检测但缺少完整的句子标题)进行评分。这项工作提出了未来的字幕策略,尤其是那些可以使班级覆盖面扩展到土地用途应用之外的策略,并且可以减轻颜色居中和邻接形容词“绿色”,“附近”,“之间”等的使用。许多现代语言转换器通过其庞大的在线语料库中的训练,提供了具有世界知识的新颖且可利用的模型。一个有趣但简单的示例可能学习风与浪之间的关联,从而使海滩场景不仅具有颜色描述,而且可以从原始像素访问而无需文本注释,从而丰富了颜色描述。 |
| Self-Learning AI Framework for Skin Lesion Image Segmentation and Classification Authors Anandhanarayanan Kamalakannan, Shiva Shankar Ganesan, Govindaraj Rajamanickam 图像分割和分类是模式识别的两个主要基本步骤。要使用深度学习模型执行医学图像分割或分类,需要对带有注释的大型图像数据集进行训练。为这项工作考虑的皮肤镜检查影像ISIC档案没有病灶分割的地面真相信息。在此数据集上执行手动标记非常耗时。为了解决这个问题,在两阶段深度学习算法中提出了自学习注释方案。两阶段深度学习算法由带有注释方案的U Net分割模型和CNN分类器模型组成。注释方案使用K均值聚类算法和合并条件来获得用于训练U Net模型的初始标记信息。分类器模型ResNet 50和LeNet 5在图像数据集上进行了训练和测试,无需进行分割以进行比较,而使用U Net进行分割以实现建议的自学习人工智能AI框架。与直接在输入图像上训练的两个分类器模型相比,所提出的AI框架的分类结果实现了93.8的训练精度和82.42的测试精度。 |
| Human Action Recognition and Assessment via Deep Neural Network Self-Organization Authors German I. Parisi 在人类机器人交互HRI领域中,对人类行为的强大识别和评估至关重要。尽管最先进的动作感知模型在大规模动作数据集中显示出显著成果,但它们大多缺乏在自然HRI场景中运行所需的灵活性,鲁棒性和可扩展性,而这些场景需要不断获取感官信息以及进行分类或评估实时检测人体模式。在本章中,我介绍了一组分层模型,用于通过使用神经网络自组织来学习和识别深度图和RGB图像中的动作。这些模型的特殊性是使用不断壮大的自组织网络,这些网络可以快速适应非平稳分布并实现专用机制,以便从时间相关的输入中持续学习。 |
| Short-Term Temporal Convolutional Networks for Dynamic Hand Gesture Recognition Authors Yi Zhang, Chong Wang, Ye Zheng, Jieyu Zhao, Yuqi Li, Xijiong Xie 手势识别的目的是识别人体有意义的运动,而手势识别是计算机视觉中的重要问题。在本文中,我们提出了一种基于3D密集卷积网络3D DenseNets和改进的时间卷积网络TCN的多模式手势识别方法。我们方法的关键思想是找到一种紧凑而有效的空间和时间特征表示,将手势视频分析的任务有序且分别地分为空间分析和时间分析两个部分。在空间分析中,我们采用3D DenseNets有效地学习短期时空时态特征。随后,在时间分析中,我们使用TCN提取时间特征,并使用改进的挤压和激励网络SENet来增强每个TCN层的时间特征的表示能力。该方法已在VIVA和NVIDIA Gesture动态手势数据集上进行了评估。我们的方法在分类精度为91.54的VIVA基准上获得了非常有竞争力的性能,并在NVIDIA基准上以86.37的精度实现了最先进的性能。 |
| A Two-Stream Meticulous Processing Network for Retinal Vessel Segmentation Authors Shaoming Zheng, Tianyang Zhang, Jiawei Zhuang, Hao Wang, Jiang Liu 眼底血管分割是眼科的关键诊断能力,这项基本任务仍然面临着各种挑战。早期方法表明,由于具有不同厚度级别的血管像素的不平衡,通常难以在细血管和边界区域上获得理想的分割性能。在本文中,我们提出了一种新颖的两流精细处理网络MP Net来解决这个问题。为了更加关注细血管和边界区域,我们首先提出了一个有效的分层模型,该模型自动将地面真光掩模分层为不同的厚度级别。然后,引入一种新颖的两流对抗网络,利用具有平衡损失函数的分层结果和积分运算来获得更好的性能,特别是在细血管和边界区域检测中。实践证明,我们的模型优于DRIVE,STARE和CHASE DB1数据集上的最新方法。 |
| ScaIL: Classifier Weights Scaling for Class Incremental Learning Authors Eden Belouadah, Adrian Popescu 如果AI代理需要集成流中的数据,则增量学习很有用。如果代理程序在有限的计算预算上运行并且对过去的数据进行有限的存储,那么问题就不小了。在深度学习方法中,恒定的计算预算要求所有增量状态都使用固定的体系结构。有界内存会产生有利于新类的数据不平衡,并且出现对新类的预测偏差。通常,除了基本的网络训练外,还通过引入数据平衡步骤来消除这种偏见。我们偏离了这种方法,并建议对过去的分类器权重进行简单而有效的缩放,以使其与新类别的权重更具可比性。缩放利用增量状态级别统计信息,并将其应用于在类的初始状态中学习的分类器,以便从其所有可用数据中获利。通过将其与有限内存存在下的香草精调进行比较,我们还质疑了增量学习算法中广泛使用的蒸馏损失分量的实用性。使用四个公共数据集,根据竞争基准进行评估。结果表明,分级器的重量定标和蒸馏的去除都是有益的。 |
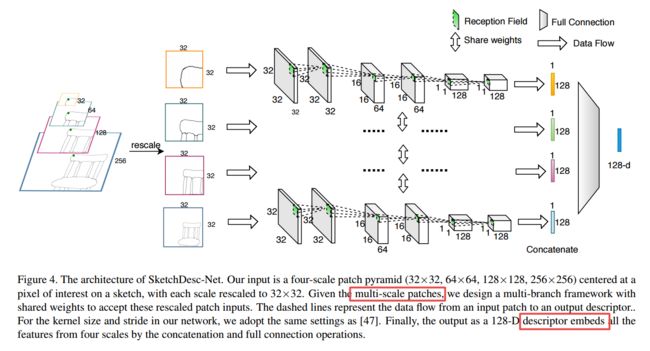
| SketchDesc: Learning Local Sketch Descriptors for Multi-view Correspondence Authors Deng Yu, Lei Li, Youyi Zheng, Manfred Lau, Yi Zhe Song, Chew Lan Tai, Hongbo Fu 在本文中,我们研究了多视图草图对应的问题,我们将多个具有相同对象的不同视图的徒手草图作为输入,并预测草图之间的语义对应。这个问题具有挑战性,因为在不同视图中相应点的视觉特征可能会非常不同。为此,我们采用了一种深度学习方法,并从数据中学习了一种新颖的局部草图描述符。我们通过为从3D形状合成的多视图线图生成像素级别对应关系来贡献训练数据集。为了处理草图的稀疏性和歧义性,我们设计了一种新颖的多分支神经网络,该网络集成了基于补丁的表示形式和多尺度策略,以学习多视图草图之间的pixelLevel对应关系。我们通过对手绘草图进行的大量实验以及从多个3D形状数据集渲染的多视图线图来证明我们提出的方法的有效性。 |
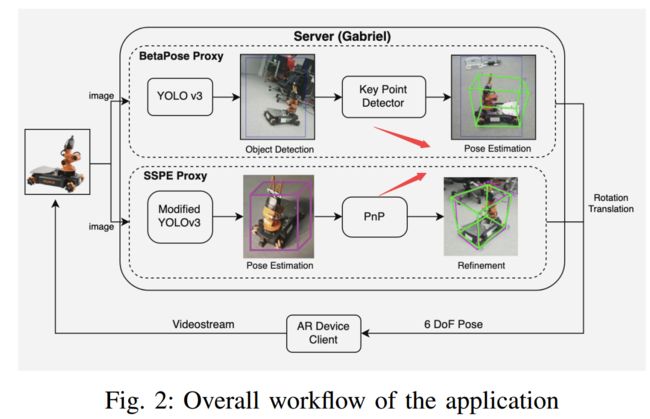
| A Markerless Deep Learning-based 6 Degrees of Freedom PoseEstimation for with Mobile Robots using RGB Data Authors Linh K stner, Daniel Dimitrov, Jens Lambrecht 增强现实技术具有增强人机交互和理解的能力,因此在行业内需要进行各种集成工作。神经网络在计算机视觉领域取得了显著成果,具有巨大的潜力来协助和促进增强现实体验。但是,大多数神经网络的计算量很大,因此需要巨大的处理能力,因此不适合在增强现实设备上进行部署。在这项工作中,我们提出了一种在增强现实设备上部署用于实时3D对象定位的先进神经网络的方法。因此,我们提供了一种使用移动机器人系统校准AR设备的更加自动化的方法。为了加快校准过程并增强用户体验,我们专注于快速2D检测方法,该方法仅使用2D输入即可快速,准确地提取对象的3D姿态。结果将实现到增强现实应用程序中,以实现直观的机器人控制和传感器数据可视化。对于2D图像的6D注释,我们开发了注释工具,据我们所知,这是第一个可用的开源工具。我们获得了可行的结果,该结果通常适用于任何AR设备,因此使这项工作有望在将高要求的神经网络与物联网设备相结合的基础上进行进一步的研究。 |
| Learning Spatiotemporal Features via Video and Text Pair Discrimination Authors Tianhao Li, Limin Wang 当前的视频表示形式严重依赖于从手动注释的视频数据集中学习。但是,获取大规模的,带有标签的视频数据集既昂贵又耗时。我们注意到,视频自然伴随着丰富的文本信息,例如YouTube标题和电影脚本。在本文中,我们利用这种视觉文本连接以有效的弱监督方式学习有效的时空特征。我们提出了一个通用的交叉模态对判别CPD框架,以捕获剪辑及其关联文本之间的这种相关性,并采用噪声对比估计技术来解决由大量对实例类所施加的计算问题。具体来说,我们从两个视频文本对来源调查了CPD框架,并设计了一种实用的课程学习策略来培训CPD。无需进行进一步的微调,学习的模型就可以根据通用的线性分类协议在Kinetics数据集上进行动作分类,从而获得有竞争力的结果。此外,我们的视觉模型提供了非常有效的初始化,可以对下游任务数据集进行微调。实验结果表明,与最新的自我监督训练方法相比,我们的弱监督预训练在UCF101和HMDB51数据集上的动作识别方面具有显着的性能提升。此外,我们的CPD模型通过直接利用学习到的可视文本嵌入,为UCF101上的零击动作识别提供了一种最新的技术。 |
| Probabilistic 3D Multi-Object Tracking for Autonomous Driving Authors Hsu kuang Chiu, Antonio Prioletti, Jie Li, Jeannette Bohg 3D多对象跟踪是自动驾驶应用程序中的关键模块,可为计划模块提供可靠的世界动态表示。在本文中,我们介绍了在线跟踪方法,该方法在NeurIPS 2019的AI驾驶奥林匹克研讨会上举行的NuScenes跟踪挑战赛中名列第一。我们的方法通过采用卡尔曼滤波器来估计对象状态。我们使用训练集中的统计数据初始化状态协方差以及过程和观察噪声的协方差。我们还通过测量预测对象状态和当前对象检测之间的Mahalanobis距离,在数据关联步骤中使用来自Kalman滤波器的随机信息。我们在NuScenes验证和测试集上的实验结果表明,在平均多对象跟踪精度AMOTA指标中,我们的方法比AB3DMOT基线方法要大得多。 |
| Rethinking Motion Representation: Residual Frames with 3D ConvNets for Better Action Recognition Authors Li Tao, Xueting Wang, Toshihiko Yamasaki 最近,3D卷积网络在动作识别方面表现出良好的性能。然而,仍然需要光流来确保更好的性能,其成本非常高。在本文中,我们提出了一种快速而有效的方法,该方法利用残留帧作为3D ConvNets中的输入数据从视频中提取运动特征。通过用残差帧替换传统的堆叠RGB帧,从头开始训练时,UCF101和HMDB51数据集的精度最高可提高10.5和20.5。由于残差帧包含的对象外观信息很少,因此我们进一步使用2D卷积网络来提取外观特征,并将其与残差帧的结果组合起来以形成两条路径的解决方案。在三个基准数据集中,我们的两条路径解决方案取得了比使用其他光流方法更好或更可比的性能,尤其是优于Mini动力学数据集上的最新模型。进一步的分析表明,使用带有3D ConvNets的残差帧可以提取更好的运动特征,并且我们的残差帧输入路径是现有RGB帧输入模型的良好补充。 |
| LE-HGR: A Lightweight and Efficient RGB-based Online Gesture Recognition Network for Embedded AR Devices Authors Hongwei Xie, Jiafang Wang, Baitao Shao, Jian Gu, Mingyang Li 在线手势识别HGR技术在增强现实AR应用程序中至关重要,可实现自然的人机交互和通信。近年来,低成本AR设备的消费市场一直在迅速增长,而该领域的技术成熟度仍然有限。这些设备通常价格低廉,内存有限以及资源受限的计算单元,这使得在线HGR成为一个具有挑战性的问题。为解决此问题,我们提出了一种轻量级且计算效率高的HGR框架,即LE HGR,以实现具有低计算能力的嵌入式设备上的实时手势识别。我们还表明,提出的方法具有很高的准确性和鲁棒性,能够在各种复杂的交互环境中达到高端性能。为了实现我们的目标,我们首先提出了一个级联的多任务卷积神经网络CNN,以同时预测在线进行手部检测和手部关键点位置回归的概率。我们表明,通过提出的级联体系结构设计,可以大大消除误报估计。另外,引入了关联的映射方法以经由预测位置跟踪手迹,这解决了多手性的干扰。随后,我们提出了跟踪序列神经网络TraceSeqNN,以通过利用跟踪轨迹的运动特征来识别手势。最后,我们提供了各种实验结果,表明所提出的框架能够以显着降低的计算成本来实现最新的准确性,这是在低成本商用设备(例如移动设备和移动设备)中实现实时应用的关键特性AR VR耳机。 |
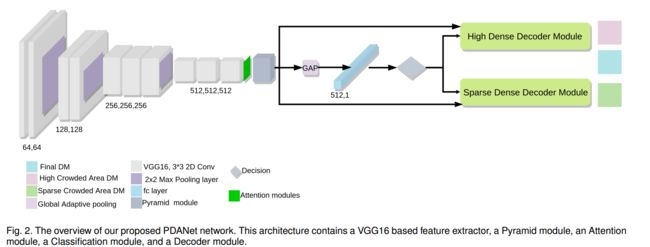
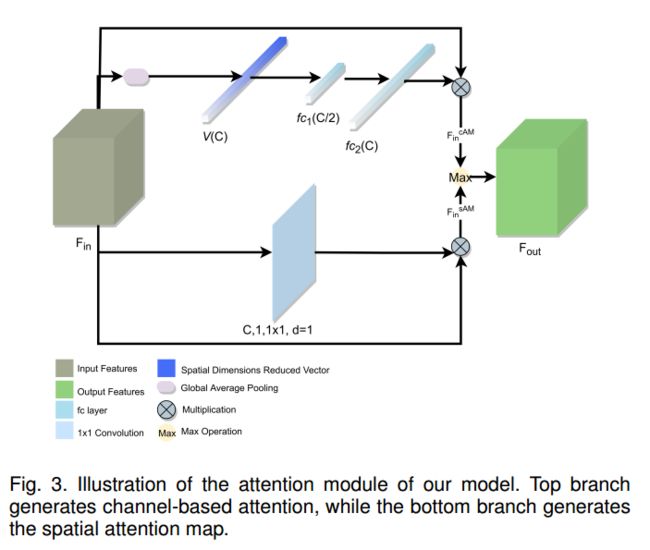
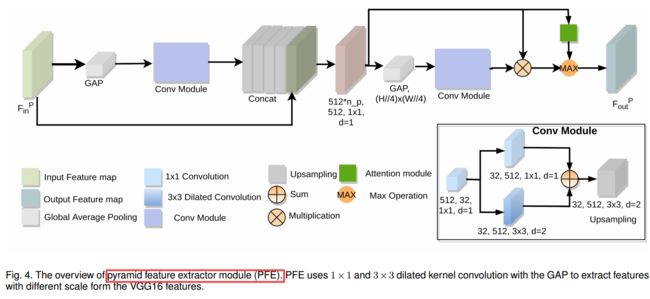
| PDANet: Pyramid Density-aware Attention Net for Accurate Crowd Counting Authors Saeed Amirgholipour, Xiangjian He, Wenjing Jia, Dadong Wang, Lei Liu 人群计数,即估计拥挤区域的人数,引起了研究界的极大兴趣。尽管已进行了许多尝试,但由于感兴趣区域内人群密度的巨大规模变化以及人群之间的严重遮挡,人群计数仍然是一个开放的现实世界问题。在本文中,我们提出了一个新颖的基于金字塔密度感知注意的网络,简称为PDANet,该网络利用注意力,金字塔尺度特征和两个分支解码器模块来进行密度感知人群计数。 PDANet利用这些模块来提取不同的比例尺特征,关注相关信息并消除误导性信息。我们还使用专用的密度感知解码器DAD解决了不同图像之间拥挤程度的变化。为此,分类器评估输入要素的密度级别,然后将其传递给相应的拥挤的DAD模块。最后,我们通过将低拥挤密度图和高拥挤密度图的总和视为空间注意力来生成总体密度图。同时,我们使用两个损失为输入场景创建精确的密度图。在具有挑战性的基准数据集上进行的广泛评估很好地证明了所提出的PDANet在计数和生成的密度图的准确性方面优于众所周知的现有技术的优越性能。 |
| Self-supervised visual feature learning with curriculum Authors Vishal Keshav, Fabien Delattre 自我监督学习技术已经显示出学习有意义的特征表示的能力。通过在仅需查找输入或输入部分之间的相关性的借口任务上训练模型就可以实现这一点。但是,需要仔细手动选择此类前置任务,以避免可能使这些前置任务变得微不足道的低电平信号。此外,删除这些快捷方式通常会导致一些语义上有价值的信息丢失。我们表明,它直接影响下游任务学习的速度。在本文中,我们从课程学习中汲取了灵感,逐步消除了低水平的信号,并表明它显着提高了下游任务的收敛速度。 |
| Delving Deeper into the Decoder for Video Captioning Authors Haoran Chen, Jianmin Li, Xiaolin Hu 视频字幕是一项高级的多模式任务,旨在使用自然语言句子描述视频剪辑。编码器解码器框架是近年来用于此任务的最流行的范例。但是,在视频字幕模型的解码器中仍然存在一些不可忽略的问题。我们对解码器进行了深入研究,并采用了三种技术来改善模型的性能。首先,将变差辍学和图层归一化的组合嵌入到循环单元中,以缓解过度拟合的问题。其次,提出了一种在验证集上评估模型性能的新方法,以便选择最佳的检查点进行测试。最后,提出了一种称为文本专业学习的新培训策略,该策略可以开发字幕模型的优点,而可以克服其缺点。在Microsoft Research Video Description Corpus MSVD和MSR Video to Text MSR VTT数据集上的实验中证明,我们的模型获得了由BLEU,CIDEr,METEOR和ROUGE L指标评估的最佳结果,在MSVD和与之前的最新模型相比,MSR VTT的排名为5。 |
| Synergetic Reconstruction from 2D Pose and 3D Motion for Wide-Space Multi-Person Video Motion Capture in the Wild Authors Takuya Ohashi, Yosuke Ikegami, Yoshihiko Nakamura 尽管已经对无标记运动捕捉进行了许多研究,但尚未将其应用于真实的运动或音乐会。在本文中,我们提出了一种无标记运动捕获方法,即使在宽广的多人环境中,该方法也可以从多个摄像机获得时空精度和平滑度。关键思想是预测每个人的3D姿势并确定足够小的多摄像机图像的边界框。这种基于人体骨骼结构的预测和时空过滤可简化人的3D重建并产生准确性。然后,将准确的3D重建用于预测下一帧中每个摄像机图像的边界框。这是从3D运动到2D姿势的反馈,并为视频运动捕获的总体性能提供了协同作用。我们使用各种数据集和一个真实的运动场演示了该方法。实验结果表明,在五个人动态运动的情况下,每个关节位置的平均误差为31.6mm,正确部位的百分比为99.3,满足运动范围。视频演示,数据集和其他资料已发布在我们的项目页面上。 |
| VSEC-LDA: Boosting Topic Modeling with Embedded Vocabulary Selection Authors Yuzhen Ding, Baoxin Li 主题建模已在许多问题中得到了广泛应用,在这些问题中,数据的潜在结构对于典型的推理任务至关重要。当应用主题模型时,相对标准的预处理步骤是首先构建常用单词的词汇表。这样的一般预处理步骤通常与主题建模阶段无关,因此不能保证预先生成的词汇表可以支持适用于给定任务的某些最佳甚至有意义的主题模型的推断,尤其是涉及以下内容的计算机视觉应用程序:视觉词。在本文中,我们提出了一种新的主题建模方法,称为词汇选择嵌入式对应LDA VSEC LDA,它可以在学习潜在模型的同时选择最相关的单词。单词的选择由基于熵的度量来驱动,该度量测量单词对基础模型的相对贡献,并在学习模型时动态进行。我们介绍了VSEC LDA的三种变体,并通过对来自不同应用程序的合成数据库和真实数据库进行实验,评估了提出的方法。结果证明了内置词汇选择的有效性及其在改善主题建模性能方面的重要性。 |
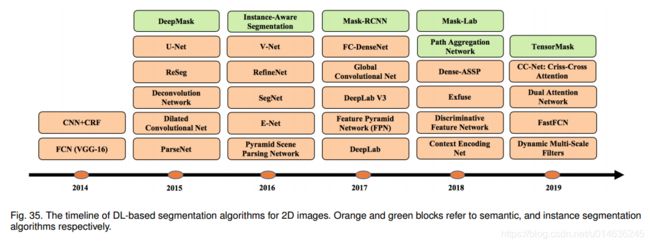
| Image Segmentation Using Deep Learning: A Survey Authors Shervin Minaee, Yuri Boykov, Fatih Porikli, Antonio Plaza, Nasser Kehtarnavaz, Demetri Terzopoulos 图像分割是图像处理和计算机视觉中的关键主题,其应用包括场景理解,医学图像分析,机器人感知,视频监视,增强现实和图像压缩等。在文献中已经开发了用于图像分割的各种算法。最近,由于深度学习模型在各种视觉应用中的成功,已经有大量旨在利用深度学习模型开发图像分割方法的工作。在本次调查中,我们在撰写本文时提供了对文献的全面回顾,涵盖了语义和实例级别分割的各种开创性作品,包括全卷积像素标记网络,编码器-解码器体系结构,基于多尺度和金字塔的方法,对抗网络中的循环网络,视觉注意模型和生成模型。我们研究了这些深度学习模型的相似性,优势和挑战,研究了使用最广泛的数据集,报告了性能,并讨论了该领域有希望的未来研究方向。 |
| A "Network Pruning Network" Approach to Deep Model Compression Authors Vinay Kumar Verma, Pravendra Singh, Vinay P. Namboodiri, Piyush Rai 我们提出了使用多任务网络进行深度模型压缩的过滤修剪方法。我们的方法基于学习修剪器网络以修剪经过预先训练的目标网络。修剪器本质上是一个具有二进制输出的多任务深度神经网络,可帮助识别原始网络各层中对模型没有重大贡献的过滤器,因此可以对其进行修剪。修剪器网络具有与原始网络相同的体系结构,不同之处在于它具有多任务多输出最后一层,其中每个过滤器包含二进制值输出,该层指示必须修剪哪些过滤器。修剪器的目标是通过将零权重分配给相应的输出特征图来最大程度地减少原始网络中的滤波器数量。与大多数现有方法相比,我们的方法无需依赖迭代修剪,而可以一次性修剪网络原始网络,而且不需要指定每一层的修剪程度,而是可以学习它。我们的方法产生的压缩模型是通用的,不需要任何特殊的硬件软件支持。此外,使用其他方法(例如知识蒸馏,量化和连接修剪)进行扩充可以增加所提出方法的压缩程度。我们展示了我们提出的方法用于分类和对象检测任务的功效。 |
| CDGAN: Cyclic Discriminative Generative Adversarial Networks for Image-to-Image Transformation Authors Kancharagunta Kishan Babu, Shiv Ram Dubey 图像到图像的转换是一种问题,其中一个视觉表示的输入图像被转换为另一视觉表示的输出图像。自2014年以来,Generative Adversarial Networks GAN通过在其架构中引入生成器和鉴别器网络,为解决该问题提供了新的方向。 Pix2Pix,CycleGAN,DualGAN,PS2MAN和CSGAN等许多最近的工作通过所需的生成器和鉴别器网络以及目标函数中使用的不同损耗的选择来解决了这个问题。尽管进行了这些工作,但在生成的图像的质量方面仍然存在差距,这些质量看起来应该更加逼真并且尽可能接近地面真实图像。在这项工作中,我们引入了一个新的图像到图像转换网络,称为循环判别式生成对抗网络CDGAN,它填补了上述空白。拟议的CDGAN通过添加除CycleGAN原始体系结构之外的其他循环图像鉴别器网络来生成高质量和更逼真的图像。为了证明所提出的CDGAN的性能,在三个不同的基准图像到图像转换数据集上进行了测试。诸如像素逐点相似度,结构水平相似度和感知水平相似度之类的量化指标可用来判断性能。此外,还对定性结果进行了分析,并与现有方法进行了比较。在三个基准图像到图像转换数据集上进行比较时,所提出的CDGAN方法明显优于所有现有技术。 |
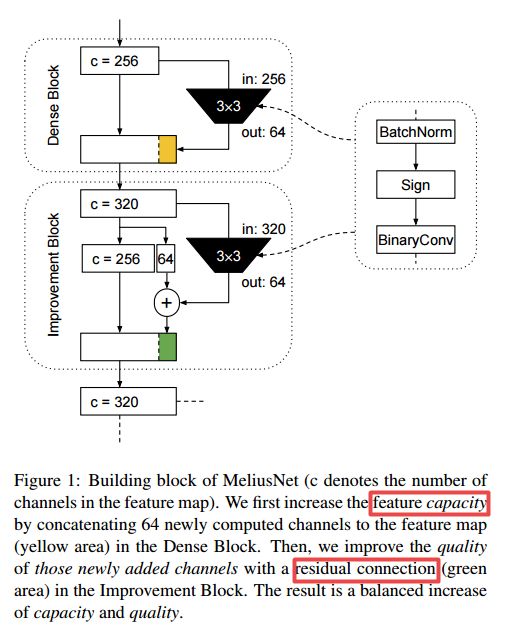
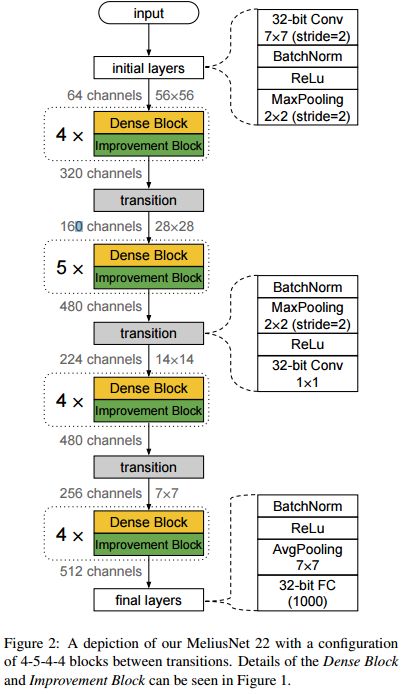
| MeliusNet: Can Binary Neural Networks Achieve MobileNet-level Accuracy? Authors Joseph Bethge, Christian Bartz, Haojin Yang, Ying Chen, Christoph Meinel 二进制神经网络BNN是使用二进制权重和激活而不是典型的32位浮点值的神经网络。它们减小了模型尺寸,并允许在功率和计算资源有限的情况下在移动或嵌入式设备上进行有效推断。但是,权重和激活的二值化导致特征图的质量和容量较低,因此与传统网络相比,准确性下降。先前的工作增加了通道的数量,或使用多个二进制库来缓解这些问题。相反,在本文中,我们提出了由交替的两个模块设计组成的MeliusNet,该设计连续增加了特征的数量,然后提高了这些特征的质量。另外,我们建议对先前方法中使用32位值的那些层进行重新设计,以减少所需的操作数。在ImageNet数据集上进行的实验证明,在节省计算和准确性方面,我们的MeliusNet优于各种流行的二进制体系结构。此外,通过我们的方法,我们训练了BNN模型,该模型首次可以在模型大小和准确性上与流行的紧凑型网络MobileNet的准确性相匹配。我们的代码在线发布 |
| MixPath: A Unified Approach for One-shot Neural Architecture Search Authors Xiangxiang Chu, Xudong Li, Yi Lu, Bo Zhang, Jixiang Li 搜索空间的表达是神经体系结构搜索NAS的关键问题。先前的块级方法主要集中于搜索网络,这些网络将一个操作与另一个操作链接在一起。将多路径搜索空间与一枪理论相结合仍然是有待解决的。在本文中,我们研究了多路径设置(称为MixPath)下的超级网络行为。对于采样训练,简单地打开和关闭多个路径会导致严重的特征不一致,从而恶化收敛性。为了纠正这种影响,我们采用称为“影子阴影批处理规范化” SBN来遵循各种路径模式。在CIFAR 10上进行的实验表明,无论允许路径的数量如何,我们的方法都是有效的。在ImageNet上进行了进一步的实验,以与最新的NAS方法进行合理的比较。我们的代码将可用 |
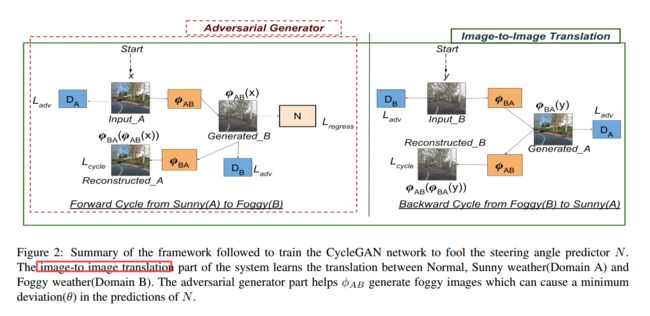
| A Little Fog for a Large Turn Authors Harshitha Machiraju, Vineeth N Balasubramanian 精心制作的小扰动称为对抗扰动,很容易使神经网络蒙昧。但是,这些干扰在很大程度上是累加的,并非自然而然地发现。我们将注意力转向自动导航领域,其中不利的天气条件(例如雾)会对这些系统的预测产生重大影响。这些天气条件能够像自然对手一样发挥作用,有助于测试模型。为此,我们引入了对抗性摄动的一般概念,可以使用生成模型来创建对抗性摄动,并提供一种方法,该方法受周期一致的生成对抗性网络启发,为给定图像生成对抗性天气条件。我们的公式和结果表明,这些图像为自主导航模型中使用的转向模型提供了合适的测试平台。我们的工作还基于感知相似性提出了更自然,更笼统的对抗性扰动定义。 |
| Run-time Deep Model Multiplexing Authors Amir Erfan Eshratifar, Massoud Pedram 我们提出了一个框架来设计轻型神经多路复用器,该框架在给定输入和资源预算的情况下,决定要进行推理的适当模型。移动设备可以使用此框架将硬输入卸载到云中,同时在本地推断简单的输入。此外,在基于云的大规模智能应用程序中,不必复制最精确的模型,而是可以根据输入的复杂性和资源预算来复用一系列大小模型。我们的实验结果表明,该框架对移动用户和云提供商均有益。 |
| Diabetic Retinopathy detection by retinal image recognizing Authors Gilberto Luis De Conto Junior 全球许多人都患有糖尿病。该疾病可能具有1型和2型。糖尿病会带来多种并发症,包括糖尿病性视网膜病,如果不正确治疗,该疾病会导致患者视力不可逆转的损害。检测到越早,患者不会失去视力的机会就越好。目前有手动程序自动化的方法,而视网膜病变的诊断过程是由医生在监视器上分析患者视网膜的手动过程。图像识别的实践可以通过识别糖尿病性视网膜病变模式并将其与患者视网膜进行诊断相比较,来帮助进行这种检测。此方法还可以帮助进行远程医疗,在这种情况下,无法访问检查的人可以从应用程序提供的诊断中受益。应用程序开发是通过卷积神经网络进行的,该系统对每个图像像素进行数字图像处理。使用VGG 16作为应用程序的预训练模型非常有用,最终模型的准确性为82。 |
| Spinal Metastases Segmentation in MR Imaging using Deep Convolutional Neural Networks Authors Georg Hille, Johannes Steffen, Max D nnwald, Mathias Becker, Sylvia Saalfeld, Klaus T nnies 这项研究的目的是使用基于深度学习的方法在诊断性MR图像中分割脊柱转移。此类病变的分割可成为朝着增强治疗计划和验证以及在微创和影像引导手术(如射频消融)期间提供干预支持的关键步骤。为此,我们使用了类似于U Net的体系结构,对40例临床案例进行了培训,包括溶解性和硬化性病变类型以及各种MR序列。我们针对各种影响分割质量的因素(例如,使用的MR序列和输入维。我们使用Dice系数,敏感性和特异性率定量评估了我们的实验。与专业注释的病变分割相比,实验产生了令人鼓舞的结果,平均Dice得分高达77.6,平均敏感度高达78.9。据我们所知,我们提出的研究是解决这一特定问题的第一个研究,该研究限制了与相关作品的直接可比性。对于类似的基于深度学习的病变分割,例如在肝脏MR图像或脊柱CT图像中,我们的实验显示出相似的或在某些方面更高的分割质量。总体而言,我们的自动方法可以在这项具有挑战性和雄心勃勃的任务中提供几乎专家级的细分精度。 |
| Probabilistic 3D Multilabel Real-time Mapping for Multi-object Manipulation Authors Kentaro Wada, Kei Okada, Masayuki Inaba 概率3D映射已应用于具有多个相机视点的对象分割,但是,常规方法缺乏实时效率和多标签对象映射的功能。在本文中,我们提出了一种实时生成具有多标签占用的三维地图的方法。扩展了以前仅映射目标标签占用率的工作,我们通过一次环顾四周的操作即可实现多标签对象细分。我们通过测试39个不同对象的分割精度并将其应用于实验中多个对象的处理任务来评估我们的方法。我们的基于映射的方法比传统的基于投影的方法优越40 96相对12.6均值IU 3d,并且机器人在严重遮挡的环境中成功识别了86.9并操纵了多个对象60.7。 |
| A Technology-aided Multi-modal Training Approach to Assist Abdominal Palpation Training and its Assessment in Medical Education Authors A. Asadipour, K. Debattista, V. Patel, A. Chalmers 计算机辅助多模式训练是学习各种应用中复杂运动技能的有效方法。在特定的学科,例如。医疗保健在执行检查时手法灵巧,临床触诊可能会导致错误的症状诊断,严重的伤害甚至死亡。此外,高质量的临床检查可以消除不必要的医学影像,从而有助于排除重大病理,并减少诊断时间和成本。在全球范围内,常规使用触诊作为一种有效的初步诊断方法,但当前需要多年的培训才能获得胜任力。本文着重于多模式触诊训练系统,以教授和改善与腹部相关的临床检查技能。我们的目标是通过增加彩排的频率来显着缩短触诊训练的时间,并就如何执行各种腹部触诊技术提供必要的增强反馈,该技术已从医学专家那里获取并建模。邀请23名一年级医学生分为对照组n 8,半视觉训练的n 8和完全视觉训练的n 7,以执行三个触诊任务,分别是浅层,深层和肝脏。使用基于计算机的方法和基于人的方法对医学生的表现进行了评估,其中所产生的得分之间呈正相关,r.62,p尾标为.05。视力训练的小组明显优于对照组,在每次触诊检查中,他们均向学生提供了施加力及其手掌位置的抽象可视化p .05。此外,当呈现视觉反馈时,在各组之间观察到正趋势,J 132,z 2.62,r 0.55。 |
| Adaptive Direction-Guided Structure Tensor Total Variation Authors Ezgi Demircan Tureyen, Mustafa E. Kamasak 方向引导的结构张量总变化量DSTV是最近提出的正则化术语,其目的是提高结构张量总变化量STV对朝向预定方向的变化的敏感性。尽管在单向图像上获得了合理的结果,但DSTV模型不适用于现实世界的多方向图像。在这项研究中,我们建立了一个两阶段框架,为DSTV带来了适应性。我们设计了STV的替代方案,该方案在空间变化的方向描述符(即方向和各向异性剂量)的指导下对本地邻域内的一阶信息进行编码。为了估计这些描述符,我们提出了一种有效的预处理器,该预处理器基于结构张量捕获局部几何形状。通过广泛的实验,通过将所提出的方法与基于最新分析的降噪模型进行比较,我们在还原质量和计算效率方面证明了方向信息在STV中的参与是多么有益。 |
| Combining Progressive Rethinking and Collaborative Learning: A Deep Framework for In-Loop Filtering Authors Dezhao Wang, Sifeng Xia, Wenhan Yang, Jiaying Liu 本文旨在基于现代编解码器的环路滤波器解决深度学习中的两个关键问题1如何在编码场景中更有效地建模空间和时间冗余2可以从编解码器推断出哪些辅助信息辅助信息有利于环路滤波器模型以及如何注入此辅助信息。对于第一个问题,我们设计了具有渐进式重新思考和协作学习机制的深度网络,以分别提高重构的帧内和帧间的质量。对于帧内编码,设计了渐进式重新思考块PRB及其堆叠的渐进式重新思考网络PRN,以模拟用于有效空间建模的人工决策机制。典型的级联深度网络在每个块的末尾使用瓶颈模块来减小特征的尺寸大小,以生成对过去经验的总结。我们设计的积木逐步进行反思,即引入附加的积木内部连接,以绕过积木中的高维信息功能,以回顾过去完整的记忆经验。对于帧间编码,该模型可以协作学习时间建模。当前重建的帧与参考帧的峰值质量帧以及最近的相邻帧在特征级别上逐渐相互作用。对于第二个问题,边信息利用率,我们提取了帧内和帧间边信息,以进行更好的上下文建模。基于HEVC分区树的粗略精细分区图被构建为帧内边信息。此外,提供参考帧的扭曲特征作为帧间边信息。得益于我们的精巧设计,在全帧内AI,低延迟B LDB,低延迟P LDP和随机访问RA配置下,我们的PRN分别平均降低了9.0,9.0,10.6和8.0 BD速率。 |
| Predicting Target Feature Configuration of Non-stationary Objects for Grasping with Image-Based Visual Servoing Authors Jesse Haviland, Feras Dayoub, Peter Corke 在本文中,我们考虑了闭环抓取的最后进近阶段的问题,其中RGB D摄像机不再能够提供有效的深度信息。这对于在当前的机器人抓握控制器出现故障的情况下抓握非静止物体至关重要。我们预测最终抓握姿势下观察到的图像特征的图像平面坐标,并使用基于图像的视觉伺服将机器人引导到该姿势。基于图像的视觉伺服是一种完善的控制技术,可以在3D空间中移动相机,以将图像平面特征配置驱动到某些目标状态。在先前的工作中,假设目标特征配置是已知的,但是对于某些应用,如果例如相对于场景第一次执行运动,则这可能不可行。我们提出的方法针对抓握最后阶段的场景运动以及机器人运动控制中的错误提供了鲁棒性。我们在动态闭环把握的背景下提供实验结果。 |
| Substituting Gadolinium in Brain MRI Using DeepContrast Authors Haoran Sun, Xueqing Liu, Xinyang Feng, Chen Liu, Nanyan Zhu, Sabrina J. Gjerswold Selleck, Hong Jian Wei, Pavan S. Upadhyayula, Angeliki Mela, Cheng Chia Wu, Peter D. Canoll, Andrew F. Laine, J. Thomas Vaughan, Scott A. Small, Jia Guo 脑血容量CBV与氧代谢的血流动力学相关,反映了大脑的活动和功能。可以使用稳态g增强MRI技术生成高分辨率CBV图。这种技术需要静脉注射基于外源g的造影剂GBCA,最近的研究表明,GBCA在频繁使用后会积聚在大脑中。我们假设,最常规和最常用的结构MRI中可能存在内源性对比源,从而可能消除了对外源性对比的需求。在这里,我们通过开发和优化小鼠中的深度学习算法(称为DeepContrast)来检验该假设。我们发现DeepContrast在绘制正常大脑组织的CBV和增强胶质母细胞瘤方面表现与外源性GBCA一样好。总之,这些研究证实了我们的假设,即深度学习方法可以替代脑部MRI中对GBCA的需求。 |
| Supervised Segmentation of Retinal Vessel Structures Using ANN Authors Esra Kaya, smail Sar ta , Ilker Ali Ozkan 在这项研究中,使用人工神经网络ANN在RGB图像的绿色通道上执行了有监督的视网膜血管分割过程。优选绿色通道,因为可以最清楚地将视网膜血管结构与RGB图像的绿色通道区分开。该研究是使用DRIVE数据集中的20张图像进行的,DRIVE数据集是已知的最常见的视网膜数据集之一。图像经过一些预处理阶段,例如对比度受限的自适应直方图均衡化CLAHE,颜色强度调整,形态学运算以及中值和高斯滤波,以获得良好的分割效果。视网膜血管结构通过高顶礼帽和自动礼帽形态学操作突出显示,并通过全局阈值转换为二进制图像。然后,通过在数据集中指定为训练图像的图像的二进制版本来训练网络,而目标是由专家手动分割的图像。发现20幅图像的平均分割精度为0.9492。 |
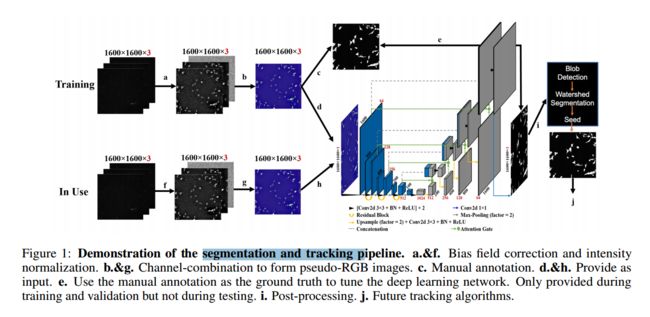
| Segmentation with Residual Attention U-Net and an Edge-Enhancement Approach Preserves Cell Shape Features Authors Nanyan Zhu, Chen Liu, Zakary S. Singer, Tal Danino, Andrew F. Laine, Jia Guo 在活的单细胞中外推基因表达动态的能力需要鲁棒的细胞分裂,而挑战之一是无定形或不规则形状的细胞边界。为了解决此问题,我们修改了U Net架构,以在荧光宽视场显微镜图像中分割细胞并定量评估其性能。我们还提出了一种新颖的损失函数方法,该方法强调了细胞边界上的分割精度并鼓励了形状特征的保留。我们的方法具有97的灵敏度,93的特异性,91的Jaccard相似度和95的Dice系数,我们提出的具有边缘增强功能的残余注意力U Net在分割性能方面已超过了传统的U Net(通过传统指标评估)。更值得注意的是,在保留宝贵的形状特征(即面积,偏心率,主轴长度,坚固性和方向性)方面,同一候选人也表现最好。形状特征保留的这些改进可以用作有用的资产,用于下游单元跟踪和量化单元统计量或特征随时间的变化。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com