深度学习调参技巧(数据预处理、归一化BN(解决数据分布问题)、学习率设定总结)
1、 权重参数初始化
下面几种方式,随便选一个,结果基本都差不多。但是一定要做。否则可能会减慢收敛速度,影响收敛结果,甚至造成Nan等一系列问题。
1、参见这篇博客——权重参数初始化方法总结
2、数据预处理方式
数据预处理在构建网络模型时是非常重要的,往往能够决定训练结果。当然对于不同的数据集,预处理的方法都会有或多或少的特殊性和局限性。在这里介绍三种当前最为普遍被广泛使用的预处理方法。
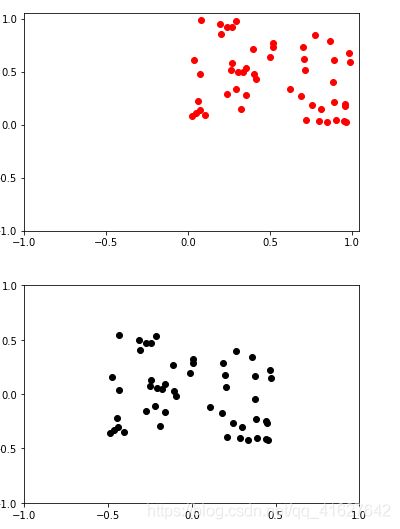
1、zero-center ,这个挺常用的.零均值化就是将每一维原始数据减去每一维数据的平均值,将结果代替原始数据。
import numpy as np
import matplotlib.pyplot as plt
from numpy import random
x = random.rand(50,2) #随机生成一个50*2(50个样本,2维)的实数矩阵
# print(x)
plt.scatter(x[:,1],x[:,0],color="red") #以x的第二列为各点的横坐标,第一列为纵坐标
new_ticks = np.linspace(-1, 1, 5) #固定坐标轴在-1到1之间,共5个值
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.show()
#***************零值化******************#
x -= np.mean(x,axis = 0) #求取每一列的均值,然后去均值
#print(x)
plt.scatter(x[:,1],x[:,0],color="black")
new_ticks = np.linspace(-1, 1, 5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.show()
2、归一化,Normalize
归一化就是将原始数据归一到相同尺度,通常有两种方法来实现归一化:
原始数据除以数据绝对值的最大值,以保证所有的数据归一化后都在-1到1之间。
原始数据零均值后,再将每一维的数据除以每一维数据的标准差。
这里利用python实现第二种:
X -= np.mean(X, axis = 0) # zero-center
X /= np.std(X, axis = 0) # normalize
3、PCA(数据降维操作) 和白化(whitening),这个用的比较少.
PCA:主成成分分析,首先将数据变成0均值的,然后计算数据的协方差矩阵来得到数据不同维度之间的相关性,协方差矩阵的第(i,j)个元素表示数据第i维和第j维特征的相关性,特别地,对角线上的元素表示方差。
另外,协方差矩阵是对称并且半正定的。可以对该协方差矩阵进行SVD分解,其中U矩阵的列为特征向量,S对角线上的元素是奇异值(等同于特征值的平方)。
为了对数据去相关,首先将数据(0均值后的)投影到特征向量上,注意,U的列是相互正交的向量,也因此它们可以被看成基向量。这种投影相当于将数据X旋转、投影到新的基向量轴上。如果再去计算Xrot的协方差矩阵的话,就会发现它是一个对角阵,说明不同维度之间不再相关。np.linalg.svd的一个很好的特性在于返回的U是按照其特征值的大小排序的,排在前面的就是主方向,因此可以通过选取前几个特征向量来减少数据的维度。
1、方差与协方差

cov默认行是变量。实际应用中需要设置rowvar=False才能以列为变量计算

2、白化
把各个特征轴上的数据除以对应特征值,从而达到在每个特征轴上都归一化幅度的结果。也就是在PCA的基础上再除以每一个特征的标准差,以使其归一化,其标准差就是奇异值的平方根。
代码:
import numpy as np
import matplotlib.pyplot as plt
from numpy import random
x = random.rand(50,2)
# print(x)
plt.scatter(x[:,1],x[:,0],color="red")
new_ticks = np.linspace(-1, 1, 5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.show()
#***************PCA和白化***************#
cov1=np.cov(x,rowvar=False) #python内置的协方差函数
print("cov1",cov1.shape)
print("cov1",cov1)
#自己的数据分布进行计算协方差矩阵
x -= np.mean(x) # 去均值
cov = np.dot(x.T, x) / x.shape[0] # 计算协方差矩阵得到相关性
print("-----------------------------------")
print("cov",cov)
U,S,V = np.linalg.svd(cov) # 协方差矩阵奇异值分解,U是特征向量
Xrot = np.dot(x, U) # 去相关,新的X轴得值
Xrot_reduced = np.dot(x,U[:,:100]) # 降维
plt.scatter(Xrot_reduced[:,1],Xrot_reduced[:,0], color = "green")
new_ticks = np.linspace(-1, 1, 5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.show()
##白化数据
Xwhite = Xrot / np.sqrt(S + 1e-5)
plt.scatter(Xwhite[:,1],Xwhite[:,0], color = "purple")
new_ticks = np.linspace(-1, 1, 5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.show()
3、注意(数据与处理只能在训练数据上进行,然后应用到验证/测试数据上)


注意:
个人的一点看法是,归一化相当原特征空间的点映射到新特征空间中,既然是在新特征空间中训练模型,就应当保证测试集和训练集同处于一个空间中,模型才有意义。所以测试集应用训练集的(均值方差)参数是可以的。更进一步的,对于后期模型实际应用,新数据也就当运用旧数据的参数和映射方法进行归一化。 另外,本人也使用了主成分分析方,测试集使用训练集计算出的转换矩阵,才能保证测试集和训练集同处于一个特征空间。
3、训练技巧
3.0 batch size:bath_size通常取值为[16,32,64,128]
128上下开始。batch size值增加,的确能提高训练速度。但是有可能收敛结果变差。如果显存大小允许,可以考虑从一个比较大的值开始尝试。因为batch size太大,一般不会对结果有太大的影响,而batch size太小的话,结果有可能很差。
3.1 深度学习调参经验
2.0 迭代次数
迭代次数是指整个训练集输入到神经网络进行训练的次数,当测试错误率和训练错误率相差较小时,可认为当前迭代次数合适;当测试错误率先变小后变大时则说明迭代次数过大了,需要减小迭代次数,否则容易出现过拟合。
2.1 激活函数的选择:
常用的激活函数有relu、leaky-relu、sigmoid、tanh等。对于输出层,多分类任务用softmax输出,二分类任务选用sigmoid输出。而对于中间隐层,则优先选择relu激活函数。另外,构建RNN时,要优先选用tanh激活函数。
2.2 学习率设定:
一般学习率从0.1或0.01开始尝试。学习率设置太大会导致训练十分不稳定,设置太小会导致损失下降太慢。学习率一般要随着训练进行衰减。衰减系数设0.1,0.3,0.5均可,衰减时机,可以是验证集准确率不再上升时,或固定训练多少个周期以后自动衰减。
2.3 防止过拟合:
一般常用的防止过拟合方法有L1、L2、dropout、提前终止、数据集扩充等。如果模型在训练集上表现良好但在测试集上表现欠佳,可以选择增大L1或L2正则的惩罚力度,或者增大dropout的随机失活概率(经验首先0.5);或者当随着训练的持续,在测试集上不增反降时,使用提前终止训练的方法。
2.3.1dropout对小数据防止过拟合有很好的效果,值一般设为0.5,小数据上dropout+sgd在我的大部分实验中,效果提升都非常明显
2.4 优化器选择:
如果数据是稀疏的,就用自适应方法,即Adagrad, Adadelta, RMSprop, Adam。整体来讲,Adam是最好的选择。SGD虽然能达到极小值,但是比其它算法用的时间长,而且可能被困在鞍点。如果需要更快的收敛,或者是训练更深更复杂的网络,需要用一种自适应的算法。目前Adam是快速收敛且常被使用的优化器。**随机梯度下降(SGD)虽然收敛偏慢,但是加入动量Momentum可加快收敛,同时带动量的随机梯度下降算法有更好的最优解,即模型收敛后会有更高的准确性。**通常若追求速度则用Adam更多。
2.5 BN层:BN层具有加速训练速度,有效防止梯度消失与梯度爆炸,具有防止过拟合的效果。
2.6 自动调参方法:(见上)
2.7 参数随机初始化与数据预处理:参数初始化很重要,它决定了模型的训练速度,与是否可以躲开局部极小。数据预处理方法一般也就是采用数据归一化即可。


遇到Nan怎么办


3、BN层(Batch Normalization)(要增大batch_size的大小)
斯坦福cs231n课程记录——assignment2 BatchNormalization
近年来深度学习捷报连连、声名鹊起,随机梯度下架成了训练深度网络的主流方法。尽管随机梯度下降法对于训练深度网络简单高效,但是它有个毛病,就是需要我们人为的去选择参数,比如学习率、参数初始化、权重衰减系数、Drop out比例等。这些参数的选择对训练结果至关重要,以至于我们很多时间都浪费在这些的调参上。那么学完这篇文献之后,你可以不需要那么刻意的慢慢调整参数。BN算法(Batch Normalization)其强大之处如下:
(1)你可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
(2)你再也不用去理会过拟合中dropout、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
(3)再也不需要使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法,搞视觉的估计比较熟悉),因为BN本身就是一个归一化网络层;
(4)可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度,这句话我也是百思不得其解啊)。
归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
我们知道网络一旦train起来,那么参数就要发生更新,除了输入层的数据外(因为输入层数据,我们已经人为的为每个样本归一化),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。以网络第二层为例:网络的第二层输入,是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。我们把网络中间层在训练过程中,数据分布的改变称之为:“Internal Covariate Shift”。Paper所提出的算法,就是要解决在训练过程中,中间层数据分布发生改变的情况,于是就有了Batch Normalization,这个牛逼算法的诞生。




源码
m = K.mean(X, axis=-1, keepdims=True)#计算均值
std = K.std(X, axis=-1, keepdims=True)#计算标准差
X_normed = (X - m) / (std + self.epsilon)#归一化
out = self.gamma * X_normed + self.beta#重构变换
Batch Normalization在CNN中的使用(在全连接层或者卷积层和激活层之间)
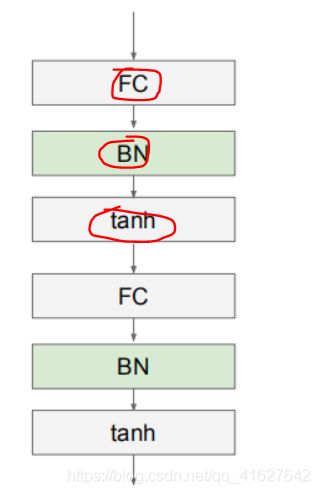
通过上面的学习,我们知道BN层是对于每个神经元做归一化处理,甚至只需要对某一个神经元进行归一化,而不是对一整层网络的神经元进行归一化。既然BN是对单个神经元的运算,那么在CNN中卷积层上要怎么搞?假如某一层卷积层有6个特征图,每个特征图的大小是100100,这样就相当于这一层网络有6100100个神经元,如果采用BN,就会有6100*100个参数γ、β,这样岂不是太恐怖了。因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。
卷积神经网络经过卷积后得到的是一系列的特征图,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),m为min-batch sizes,f为特征图个数,p、q分别为特征图的宽高。在cnn中我们可以把每个特征图看成是一个特征处理(一个神经元),因此在使用Batch Normalization,mini-batch size 的大小就是:mpq,于是对于每个特征图都只有一对可学习参数:γ、β。**说白了吧,这就是相当于求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对这个特征图神经元做归一化。
正向传播
import numpy as np
#BN正向传播
def batchnorm_forward(x, gamma, beta, bn_param):
"""
Input:
- x: Data of shape (N, D)
- gamma: Scale parameter of shape (D,)
- beta: Shift paremeter of shape (D,)
- bn_param: Dictionary with the following keys:
- mode: 'train' or 'test'; required
- eps: Constant for numeric stability
- momentum: Constant for running mean / variance.
- running_mean: Array of shape (D,) giving running mean of features
- running_var Array of shape (D,) giving running variance of features
Returns a tuple of:
- out: of shape (N, D)
- cache: A tuple of values needed in the backward pass
"""
mode = bn_param['mode']
eps = bn_param.get('eps', 1e-5)
momentum = bn_param.get('momentum', 0.9)
N, D = x.shape
running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype))#参数初始化
running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype))#
out, cache = None, None
if mode == 'train': #训练阶段
########################################################
mu = np.mean(x, axis=0) #均值,计算每一批神经元的均值
sigma2 = np.var(x, axis=0) #方差,计算每一批神经元的方差
x_hat = (x - mu) / np.sqrt(sigma2 + eps)
out = gamma * x_hat + beta #scale & shift
########################################################
running_mean = momentum * running_mean + (1 - momentum) * mu #测试阶段的均值
running_var = momentum * running_var + (1 - momentum) * sigma2
inv_sigma = 1. / np.sqrt(sigma2 + eps)
cache = (x, x_hat, gamma, mu, inv_sigma)
elif mode == 'test':
x_hat = (x - running_mean) / np.sqrt(running_var + eps)
out = gamma * x_hat + beta
else:
raise ValueError('Invalid forward batchnorm mode "%s"' % mode)
# Store the updated running means back into bn_param
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return out, cache
反向传播算法



#BN反向传播方法一
def batchnorm_backward(dout, cache):
"""
Inputs:
- dout: Upstream derivatives, of shape (N, D)
- cache: Variable of intermediates from batchnorm_forward.
Returns a tuple of:
- dx: Gradient with respect to inputs x, of shape (N, D)
- dgamma: Gradient with respect to scale parameter gamma, of shape (D,)
- dbeta: Gradient with respect to shift parameter beta, of shape (D,)
"""
dx, dgamma, dbeta = None, None, None
x, x_hat, gamma, mu, inv_sigma = cache
N = x.shape[0]
dbeta = np.sum(dout, axis=0)
dgamma = np.sum(x_hat * dout, axis=0)
dvar = np.sum(-0.5 * inv_sigma ** 3 * (x - mu) * gamma * dout, axis=0)
dmu = np.sum(-1 * inv_sigma * gamma * dout, axis=0)
dx = gamma * dout * inv_sigma + (2 / N) * (x - mu) * dvar + \
(1 / N) * dmu
return dx, dgamma, dbeta
#BN反向传播方法二,红色的推导公式
def batchnorm_backward_alt(dout, cache):
"""
Alternative backward pass for batch normalization.
For this implementation you should work out the derivatives for the batch
normalizaton backward pass on paper and simplify as much as possible. You
should be able to derive a simple expression for the backward pass.
See the jupyter notebook for more hints.
Note: This implementation should expect to receive the same cache variable
as batchnorm_backward, but might not use all of the values in the cache.
Inputs / outputs: Same as batchnorm_backward
"""
dx, dgamma, dbeta = None, None, None
x, x_hat, gamma, mu, inv_sigma = cache
N = x.shape[0]
dbeta = np.sum(dout, axis=0)
dgamma = np.sum(x_hat * dout, axis=0)
dxhat = dout * gamma
dx = (1. / N) * inv_sigma * (N * dxhat - np.sum(dxhat, axis=0) -
x_hat * np.sum(dxhat * x_hat, axis=0))
return dx, dgamma, dbeta

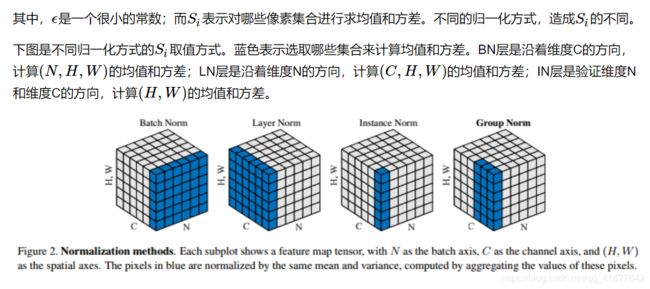
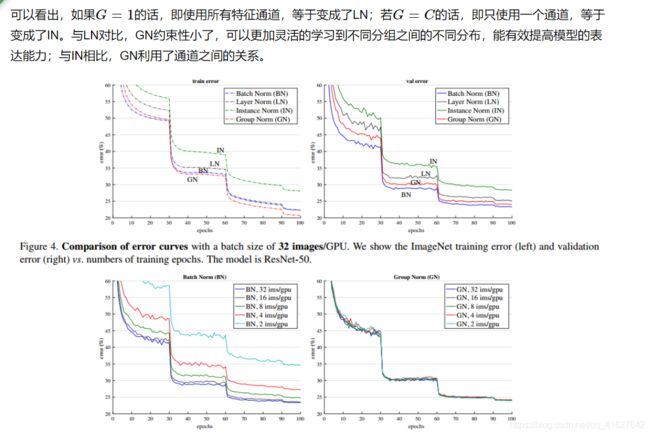
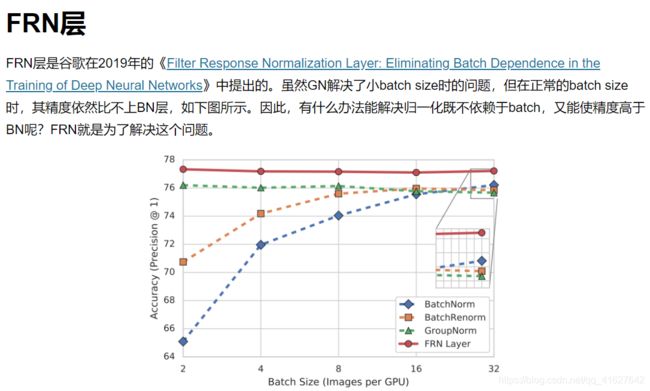
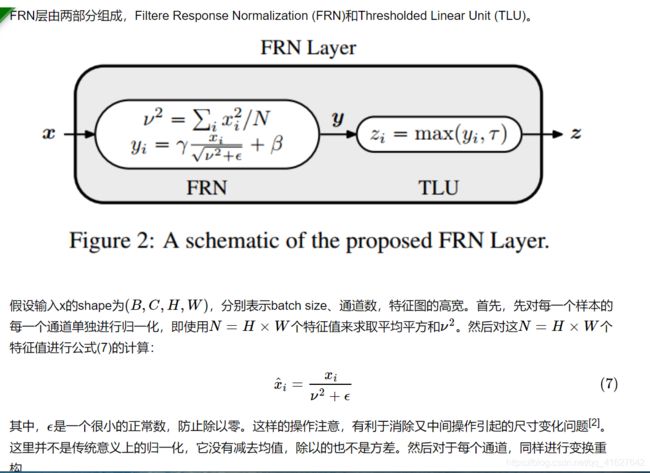
GN