【行为识别】论文阅读笔记1|Two-Stream Convolutional Networks for Action Recognition in Videos
参考山水之间2018的文章,
行为识别(Action Recognition) 的目的是对一个给定的视频片段进行分类。
行为检测(Action Detection) 的目的是知道一个动作在视频中是否发生,以及动作发生在视频中的开始时间和结束时间。 行为识别和行为检测的关系类似于图片分类和目标检测的关系。
目前行为识别有两个主流的结构,一个是Two-Stream,一个是C3D,本文阅读了经典的Two-Stream论文,C3D阅读笔记之后会记录在后面一篇。
进入正文部分。
摘要
针对视频中的行为识别问题,研究进行了判别训练的深度卷积网络(ConvNets)。本研究的挑战在于从静止的帧以及运动的帧与帧中捕获外观的补充信息。同时旨在从数据驱动的学习框架中概括出性能最佳的人工提取的特征。
贡献有三点。 第一,提出了一个包含时间和空间网络的双流ConvNet网络结构。第二,证明即使在缺少训练数据的情况下,在多帧密集光流上训练的ConvNet也能够有良好的性能。第三,证明了应用于两个不同动作分类数据集的多任务学习能够用于增加训练数据量,同时也能够提高训练的效果。
所提出的架构在UCF-101和HMDB-51标准视频动作数据最集上进行训练与评估,同时与目前最先进的架构进行比较。所提出的架构大大超过了以前所使用的用于视频分类的深度网络。
引言
与静态的图像分类相比,视频的时序部分为识别提供了另一种办法。因为基于运动信息,能够可靠地识别出一系列的动作。除此之外,视频为单张图片(视频帧)分类提供了自然的数据增强方法(jittering,抖动)。
本文旨在将最先进的静态图像表示方法深度卷积网络(ConvNets)扩展使用于视频数据中的动作识别方向。最近已经有研究将逐帧视频的堆叠作为网络的输入,但是识别结果却比最好的人工设计浅层表示差得多。我们研究了一个不同于此的基于两个单独的识别流(空间和时间)的体系结构,后期将两个识别流融合起来。空间流从静态视频帧中进行行为识别,经过训练的时间流从密集光流进行行为识别。空间流和时间流都用ConvNets实现。解耦空间流和时间流,能够通过预先在ImageNet数据集中训练好的空间网络,利用大量已标记的图像数据。所提出的架构与双流假说有关——人类视觉皮层包含两个通道:腹侧流(执行目标识别)和背侧流(识别运动)。
相关工作
图像识别方向的进步极大程度推进了视频识别研究工作的发展,常常调整和拓展图像识别方法以处理视频数据。
文章大致介绍了目前图像识别常见的方法:
一、基于局部时空特征的浅层高维编码。
- 检测稀疏时空兴趣点后使用局部时空特征描述的HOG和HOF,特征之后编码到BoF表示,汇总在几个时空网格上(类似于空间金字塔池),并与SVM分类器结合。
- 局部特征的密集采样方法。
- 替代以前在时空长方体上计算局部视频特征的方法,最新的浅层视频表示方法利用了密集点轨迹。例如基于梯度特征,分别对光流进行水平和垂直计算的MBH方法。
二、基于深度架构的视频识别方法。大多都采用将连续的视频帧作为网络输入,所以模型在第一层就要隐式地学习时空运动相关的特征,这是很困难的。
- HMAX架构在第一层预先定义了时空滤波器,之后和空间HMAX模型结合,形成了空间流(类似于腹侧流)和时间流(类似背侧流)。本文工作不像之前的工作使用人工设计的浅层(3层)HMAX模型实现。
- 使用卷积RBM和ISA进行时空特征无监督学习,后将其插入到判别模型中进行行为分类。
本文的时间流ConvNet在多帧密集光流上运行,在能量最小化框架中通过求解位移场(通常为多个图像比例)。使用了一种常用的方法,这种方法基于强度及其梯度以及位移场的平滑度的恒定假设,对能量进行形式化。
Two-Stream网络结构
视频可以被分解空间和时间两部分。空间部分以单独帧的形式存在,携带关于视频中场景和目标描述的信息。时间部分,以贯穿所有帧的运动形式存在,记录了观察者(摄像机)和目标的运动情况。本文针对空间和时间两部分相应设计了视频识别的架构,分为空间流和时间流。
通过图1(Figure 1)可以看到有两条分支,也就是两条流结构。每一条流结构都使用深度ConvNet来实现。在之后将时间流和空间流通过softmax scores融合的方式结合起来。
融合方式考虑了两种方法:平均法和训练一个多任务的线性SVM分类器。
 空间流ConvNet结构在单个视频帧上执行,从静态的图片中有效地进行行为识别。因为某些动作和特定的目标是密切相关的,所以静态的外观本身就已经是一个有用的线索。事实上从静态帧(空间识别流)中进行行为分类是很具挑战性的。空间流ConvNet结构的本质是图片分类架构,所以本文在空间流ConvNet上使用普遍使用的最新的图片识别方法,同时利用大型的图片分类数据集(比如ImageNet数据集)对空间流ConvNet进行预训练。
空间流ConvNet结构在单个视频帧上执行,从静态的图片中有效地进行行为识别。因为某些动作和特定的目标是密切相关的,所以静态的外观本身就已经是一个有用的线索。事实上从静态帧(空间识别流)中进行行为分类是很具挑战性的。空间流ConvNet结构的本质是图片分类架构,所以本文在空间流ConvNet上使用普遍使用的最新的图片识别方法,同时利用大型的图片分类数据集(比如ImageNet数据集)对空间流ConvNet进行预训练。
光流ConvNets
这一节是对组成了Two-Stream架构中的时间识别流ConvNet进行介绍。和之前相关工作中介绍的那些深度网络结构不同,时间流ConvNet的输入是几个连续帧之间的堆叠光流位移场。这样的输入显式描述出视频帧之间的运动状态,也使得视频更加简单,因为网络不用去隐式地估测运动状态。
文中对基于光流输入的几个变量进行了阐述。

图2中的(a)和(b)是一对连续视频帧,在移动的手周围用青色的矩形勾勒出了一个区域。(c)是在所勾勒出的轮廓中的密集光流的特写。(d)是位移向量场的水平分量dx(高密度对应正值,低密度对应负值)。(e)是位移向量场的垂直分量dy。
注意:(d)和(e)是如何强调移动的手和弓箭的。
ConvNet的输入包含了多种光流。
ConveNet的输入结构
前面一直提到光流堆叠(Optical flow stacking),那么到底什么是光流堆叠?
首先,密集光流(Dense optical flow) 可以看做是一堆连续帧第t帧和第t+1帧之间的一组位移向量场dt。dt(u,v)用于表示第t帧中点(u,v)的位移向量场,代表将(u,v)点移动到第t+1帧的对应点上。第t帧的位置向量场的水平和垂直分量分别记录为 d t x \ d_t^x dtx 和 d t y \ d_t^y dty 。这两个分量可以看做是图片通道(图2有阐述)。为了表示一系列帧之间的运动,将L个连续帧的光流通道(水平和垂直) d t x , y \ d_t^{x,y} dtx,y 进行叠加,形成2L个输入通道。将w和h用于表示视频的宽和高。定义了这些符号表达后,如下构建一个任意帧τ的ConvNet输入量Iτ∈ R w × h × 2 L \ ℝ^{w×h×2L} Rw×h×2L:
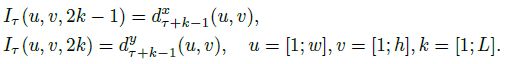
对于任意的一个点(u,v),通道Iτ(u,v,c),c=[1;2L]编码了在L帧序列上该点的运动(如图3的左图所示)。
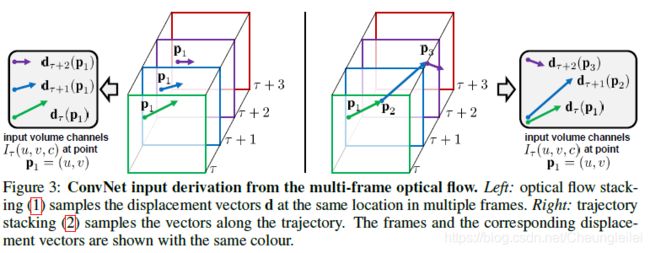
【左图:光流堆叠在多帧的同一个位置对位移向量d采样;右图:轨迹堆叠沿着轨迹对向量采样。】
接下来是轨迹堆叠(Trajectory stacking)。在同样的位置对几个帧沿着运动轨迹采样,帧τ的输入量Iτ以下列形式阐述:
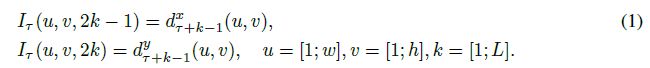
pk是从第τ帧的(u,v)位置开始的轨迹的第k个点,由下列递推关系定义:
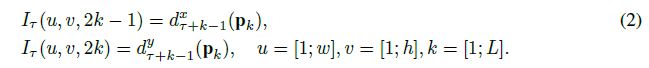
光流堆叠(式(1))的输入量表达式中,通道Iτ(u,v,c)在位置(u,v)上存储了位移向量,轨迹堆叠(式(2))存储了向量采样与轨迹沿线的位置Pk上(如图3右图所示)。
此后是双向光流(Bi-directional optical flow)。光流堆叠和轨迹堆叠都处理的是前向光流,即第t帧位移场dt是定义为它在第t+1帧的像素位置的。于是就引出双向光流的概念,计算相反方向的位移场就能得到双向光流。也就是说Iτ 叠加第τ帧和第 τ+ L 2 \frac{L}{2} 2L 帧之间的 L 2 \frac{L}{2} 2L个前向光流和第 τ- L 2 \frac{L}{2} 2L 帧与第τ帧之间 L 2 \frac{L}{2} 2L个后向光流。那么Iτ 仍然拥有和以前的2L一样的通道数。光流可以用光流堆叠或轨迹堆叠表达。
光流均值减法(Mean flow subtraction)。通常对网络输入进行中心化是有利的,因为中心化可以让模型更好地纠正非线性。本文中,位移向量场的组成部分自然地居中,可以是正值也可以是负值,也就意味着,在各种各样的运动中,往一个方向上运动与往相反方向运动的概率是一样的。然而,给定一对帧,它们之间的光流可以被特殊的位移来控制。例如,被摄像机的运动影响(涉及摄像机运动补偿)。摄像机运动补偿是在评估了一个全局的运动分量后从密集流中减去该分量。本文采用的是更简单的方法:对每一个位移d减去它的均值向量。
以上内容都是获取光流输入的方法。ConvNet要求输入固定大小,从Iτ中采出224×224×2L的子集,将其输入ConvNet。隐藏层的配置与时间流ConvNet中的配置基本相同。测试与空间ConvNet相似。
之后阐述了时间流ConvNet架构与以前的表示的联系。

图4将第一层时间ConvNet的卷积核结果可视化了,这个训练是在UCF-101数据集上执行的。96个卷积核都是7×7的,跨越20个通道,对应着10个叠加的光流位移d的水平和垂直分量(通道)。
一些卷积核可以计算光流的空间导数,获取运动如何随着图像位置的变化而变化,因此产生了基于导数的人工设计描述子(例如MBH)。其他的卷积计算时间导数,获取运动随时间的变化。
多任务学习
空间网络的训练可以预先在例如ImageNet这样的数据集上进行训练,但是时间网络的训练目前视频数据库比较少,所以提出了多任务学习机制。
本文多任务学习是指训练时间网络使用UCF和HMDB-51两个数据集结合。本文将ConvNet改进了一下,在全连接层分别设计了两个softmax分类层,一层计算HMDB-51的分类分数,另一个计算UCF-101的分数。每一层都分别计算损失,然后计算训练损失,即每一个单独任务的损失值总和,反向传播得到网络的权重导数。
实施细节
网络配置(ConvNets configuration)。上文图1结构性展示了时间和空间网络的网络配置。隐藏层的激活函数使用的都是ReLU。最大池化的卷积核大小是3×3,步长为2。局部响应归一化设置和AlexNet方法一致。时间和空间的ConvNet配置唯一不同的是,移除了时间ConvNet的第二个规范化层来减少内存的消耗。
训练(Training)。使用mini-batch随机梯度下降来学习权重,学习率设为0.9。每一次迭代,mini-batch为256,样本来自采样的256个训练视频中随机选取的帧。
在空间网络的训练中,被选取的帧随机裁剪为224×224的子图,然后进行随机水平翻转和RGB抖动处理。视频被预先缩放过,帧的最小边等于256。和AlexNet方法不同,本文方法的子图从整个帧中采样,而不仅仅是中心采样。
在时间网络的去扬中,计算所选训练帧的光流量I。随后从I中随机裁剪和翻转得到一个固定大小的224×224×2L的输入。学习率最初设为10-2 ,从头开始训练ConvNet的时候,在50000次迭代后,学习率会调整到10-3 ,在70000次后,降低到10-4 ,在80000次迭代后,训练介绍。fine-tuning的时候,学习率在14000次迭代后,调整为10-3 ,在20000次后训练结束。
测试(Testing)。给定一个视频,从中取出25帧,帧与帧之间的时间间隔相同。每一帧都从中获得10个ConvNet输入,这10个输入通过裁剪和翻转四个角得到。整个视频的类别得分是通过对取样的帧和由这些帧裁剪出的子图进行取平均分的方式得到。
在ImageNet ILSVRC-2012上预训练。对空间网络进行预训练的时候,训练和测试数据都使用与上文相同的数据增强方法。这样做的效果很好,认为提升的原因可能是对ConvNet输入的采样是从整个图片中来的,而不仅仅是中心采样。
多GPU训练。实验基于Caffe,在安装于一个系统中的多个GPU上并行训练。利用数据的并行性,将每个SGD batch划分到多个GPU中。
光流是在OpenCV框架下用现成的GPU方法计算的。在即时计算时仍会出现瓶颈,所以预计算了光流。避免将位移矢量以浮点数形式存储,光流的水平和垂直分量被线性缩放到[0,255]范围中,以JPEG格式压缩,极大减小了UCF-101数据集的光流量。
评估
数据集和评估协议。评估按照UCF-101和HMDB-51行为识别基准进行。评估协议相同:将数据集划分3份放入训练和测试数据中,性能好坏由在划分数据上的平均分类准确性衡量。
空间网络。三种情况如下:
(i)从头开始在UCF-101上进行训练(From scratch)。
(ii)在ILSVRC-2012上进行预训练,后在UCF-101上对整个网络进行微调(Pre-trained + fine-tuning)。
(iii)保持预先训练的网络固定,仅训练最后一个分类层(Pre-trained + last layer)。
每一种情况,都将dropout ratio设为0.5或0.9,表1的左边小表格可以看到,情况(i)导致了过拟合情况,并且效果不如情况(ii)。对整个网络进行fine-tuning效果只比对最后一层进行fine-tuning好了一点点。最后一行,dropout ratio更高,但效果却更差。在接下来的实验中,选择训练预训练网络的最后一层。

时间网络。接下来用之前介绍过的光流计算方法对时间网络架构进行衡量,方法包括:多个(L={5,10})堆叠起来的光流;轨迹堆叠;光流均值减法;双向光流。时间网络架构在UCF-101上从头开始训练,设置dropout ratio为0.9。表1的右边的小表格是所得结果。
表格第一行和第二行相比,可以看到输入多个(L>1)光流位移效果更好,因为它给网络提供了长期持续的运动信息,多个光流输入比输入一对帧(L=1)具有更好的辨别力。第二行和第三行相比,将输入的L=5升到L=10,有一个小幅度的提升,所以在之后的实验中都保持L=10。第五行的结果看出光流均值减法是有用的,它降低了帧与帧之间全局运动的影响。叠加技术的不同对结果影响不大,表中结果看出光流堆叠比轨迹堆叠效果更好,使用双向光流比使用单向光流效果好了一点点。同时表1也可以看到时间网络的训练结果比空间网络好,这也印证了行为识别中运动信息很重要。作者也用了RGB帧进行叠加输入网络,但是效果不如光流输入好,这说明多帧信息很重要,但是运用恰当的多帧信息也很重要。
在时间网络上的多任务学习。因为训练集很小,所以在UCF-101上训练时间网络是很有挑战性的。但是在HMDB-51上训练网络就更有挑战性了,因为分出来的训练集比UCF-101小了2.6倍。于是评估了不同的方法去扩大HMDB-51:
(i)fine-tuning一个用UCF-101预训练过的网络;(ii)从UCF-101里添加了78个类别,这78个类别是手工挑选的,所以不会和HMDB-51的类别出现重叠现象;
(iii)使用多任务的构想去学习视频的表达,在UCF-101和HMDB-51中共享。结果在表2中表达。

如预见的那样,使用所有(之前划分片段结合在一起)的UCF-101数据来训练是有好的效果的。多任务学习得到的效果最好,因为它在训练过程中利用了所有可利用的训练数据。
双流网络。结合时间和空间两个网络的一种方法是,在两个网络的full6和full7层训练一个联合叠加的全连接层。但是因为过拟合问题在本文中不使用。采用利用均值或者线性SVM方法融合softmax分数的办法。在表3中可以总结得到以下结果:
(i)时间和空间识别流是互补的,它们的融合使结果显著提高了(时间网络提高了6%,空间网络提高了14%)。
(ii)基于SVM的融合比均值融合更好。
(iii)使用双流光流发在ConvNet融合中没用。
(iv)使用多任务学习训练的时间网络无论是单看还是和空间网络结合来看都有最好的性能。

和最新研究相比较。在之前UCF-101和HMDB-51中各分出的3个数据集上进行对比。
空间网络在ILSVRC上预训练,最后一层用UCF和HMDB训练。空间网络用UCF和HMDB多任务学习的方式训练,输入用均值减法单项光流叠加计算。时空网络的softmax分数用均值或者SVM结合。
在表4中可以看到,单流的时间和空间网络效果都是比[14,16]中的架构效果好的。两个网络结合在一起的效果就更好了。

混淆矩阵和UCF-101分类的召回率。图5展示了使用双流模型对UCF-101分类的混淆矩阵。

个人学习总结
文章提出了创新的双流卷积网络结构,并且经过实验证明了这种结构比之前使用的一些模型效果更好。双流卷积网络结构是在一段视频中处理动作的分类。时间网络处理RGB信息,空间网络处理光流信息,包含光流位移的水平分量和垂直分量两个通道。时间网络图输入时一段视频随机挑选出的任意一帧,光流图是选择任意几个时间间隔相同的帧堆叠在一起输入。
在文中,通篇有一个地方引起了我的注意,就是作者认为将光流叠加输入效果好的原因是光流能够反映运动信息,查阅了资料,参考AresAnt的文章:
实际上光流图并不是以motion的信息来得到结果
这里提供了一个参考资料。其实光流对场景表示有表观不变性(打乱光流顺序,打乱帧与帧之间的时间顺序,对帧的colormap进行变化等等,都不会太影响光流的准确度,所以光流起作用之处不是时序结构)。且在运动边界以及交互物体(此处指人)的光流对于识别更重要。因此建立有效运动表示还是一个开放问题,因为光流没有解决这个问题。
下一篇会对另一个行为识别的方法C3D进行了解。