ICCV 2019 | SPM:单阶段人体姿态估计解决方案
本文为极市作者Panzer原创,欢迎加小助手微信(cv-mart) 备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群。
本文由新加坡国立大学和依图科技合作发表于ICCV2019,论文首次提出了人体姿态估计的单阶段解决方案,在取得速度优势的同时,也取得了毫不逊色于双阶段方法的检测率。

论文地址:
http://openaccess.thecvf.com/content_ICCV_2019/papers/Nie_Single-Stage_Multi-Person_Pose_Machines_ICCV_2019_paper.pdf
背景介绍
对单张图像中的多个人体进行姿态估计是一个非常有挑战性的问题,目前主流算法多采取双阶段的方案,其中一类是采用自顶而下的策略:第一阶段用目标检测器将图像中的多个人体检测出来,第二阶段对每个人体分别预测多个人体关键点;另一类是采用自下而上的策略:第一阶段将图像中的所有人体关键点都检测出来,第二阶段将这些检测到的关键点进行匹配归类到多个人体上。以上方法均存在的一个问题是耗时且无法发挥CNN网络端到端可训练的优势。
从这一问题出发,本文首次提出了单阶段的解决方案,也即只需要将图像输入网络一次就可以得到逐个人体的关键点。作者在多个数据集上进行了公开评测,实验结果表明,本文提出的单阶段解决方案在取得速度优势的同时,也取得了毫不逊色于双阶段方法的检测率。此外,由于框架简单,该方法可以直接从2D图像扩展到3D图像的人体姿态估计。下图展示了本文方法和已有主流方法的直观对比。

主要内容
结构化姿态表示(Structured Pose Representations, SPR)
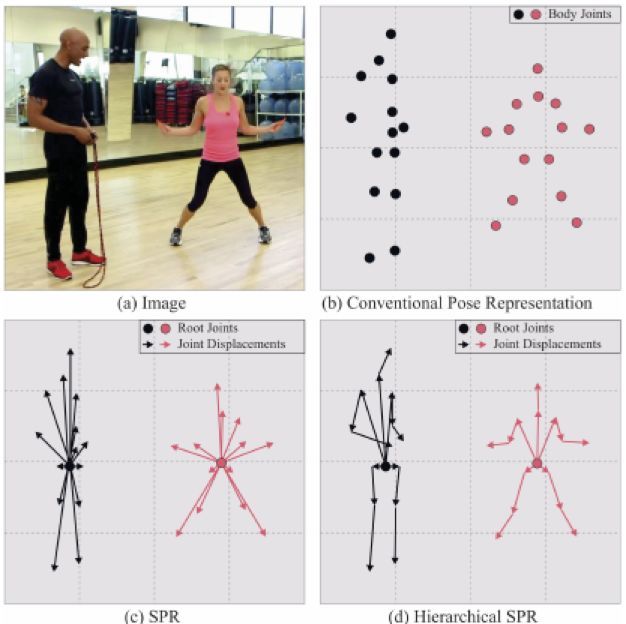
通常一个人体的姿态是由人体上几个具有代表性的关键点来表征(如下图(b))。作者的思路是首先找到每个人体的中心点,也即root joint(如下图©),然后再计算需要检测的每个关键点到root joint的偏差量,root joint可以由二维坐标表示为![]() ,而每一个偏差量也可以由一个二维数组表示为
,而每一个偏差量也可以由一个二维数组表示为![]() ,则每个关键点就可以表示为:
,则每个关键点就可以表示为:
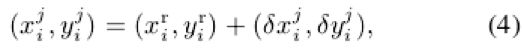
根据以上分析,每一个人体姿态就可以由root joint以及这些每个关键点到root joint的偏差量表示:
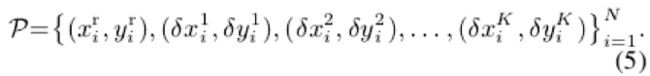
所以CNN网络的任务就是回归出root joint以及这些每个关键点到root joint的偏差量就可以完成人体姿态估计了。由于要回归距离root joint较远的关键点的偏差量较为困难,为了简化这一任务,作者提出了Hierarchical SPR的策略,其核心思想是先计算距离root joint较近的几个关键点的偏差量,再以这几个关键点为下一层的root joint,计算该root joint周围的几个关键点的偏差量,逐层向外围推进,直到计算出所有关键点的偏差量,如下图(d)所示。
实现细节:
1、回归目标:回归目标包含两个部分,如下图所示,
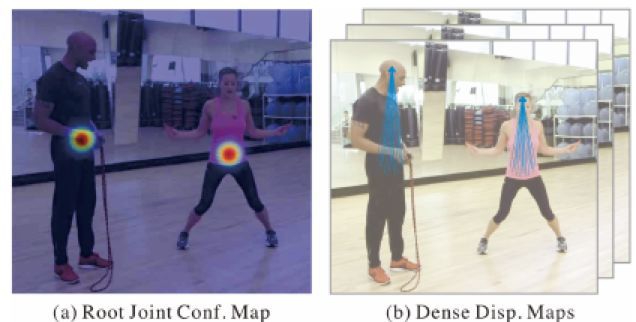
一是root joint的位置,作者采用的是置信图的方式,以每个root joint位置为中心构建一个高斯掩码:![]() ,则root joint置信图是多个人体高斯掩码的叠加。
,则root joint置信图是多个人体高斯掩码的叠加。
二是每个关键点到root joint的偏差量,同样采用置信图的方式,为每个关键点计算到root joint周围一定区域内(文中为7个像素)的距离,具体表示为:
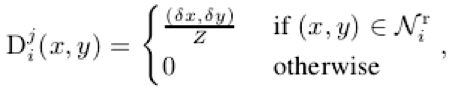
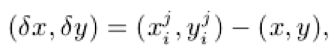
![]()
**2、网络架构和目标函数:**网络架构采用的是人体姿态估计领域中常用的Hourglass网络,该网络包含几个结构类似的组件如下图所示:
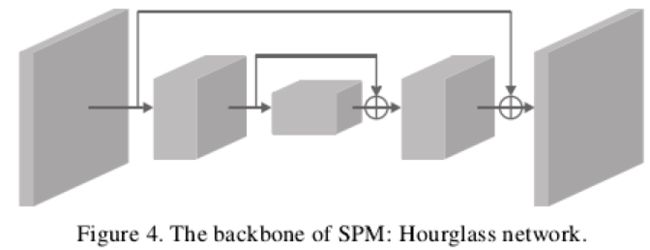
目标函数包含同样两个部分:root joint回归的损失和偏差量回归的损失,前者采用l2 loss,后者采用smooth l1 loss。由于Hourglass网络较深,为了回传的梯度不至于在浅层时消失,在Hourglass网络几个组件之间也同样添加了损失。如下式所示:
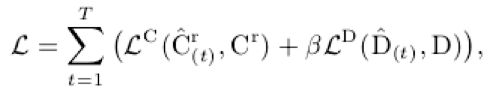
T为Hourglass网络中组件的个数
实验分析
实验细节:
实验在MPII dataset, extended PASCAL-Person-Part和MSCOCO上进行。此外,为了验证本文方法的通用性,作者还将其扩展到了3D图像上,并在CMU Panoptic dataset上进行了实验验证。评估指标采用平均准确率Average Precision (AP)。
实验结果:
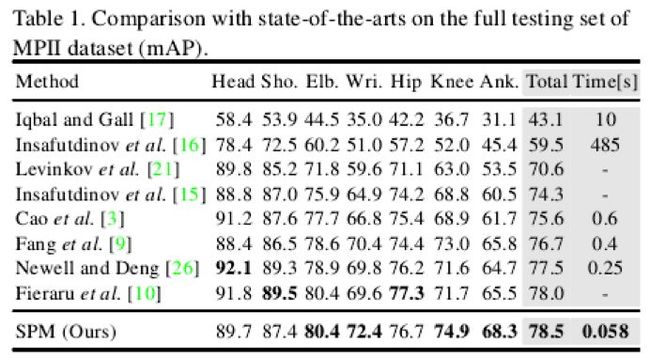
表1展示了本文方法SPM与主流方法在MPII dataset的对比实验,从表中可以发现本文方法在单张图像耗时降低了一个数量级的基础上,依然取得了最佳的平均准确率,比已有最佳方法高了0.5个百分点。
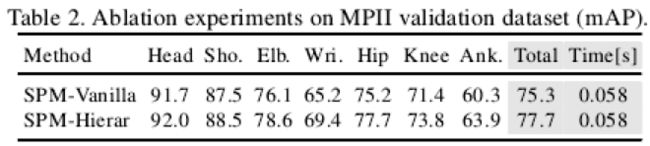
表2通过对比实验展示了层级SPM的有效性,层级SPM比原始SPM在准确率上高出了2.4个百分点,证明了逐层递进计算每个关键点到root joint的偏差量能够大大简化网络学习的难度,进而可以取得更加的检测性能,尤其是在手腕、脚踝等姿态变化较为丰富的关键点上所表现的性能提升更为出色。
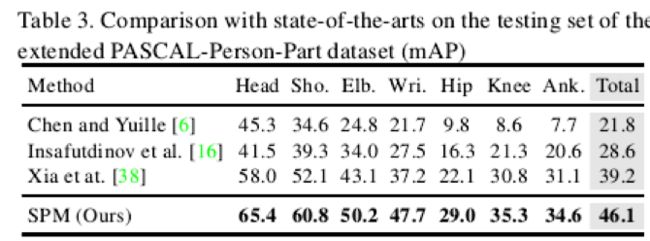
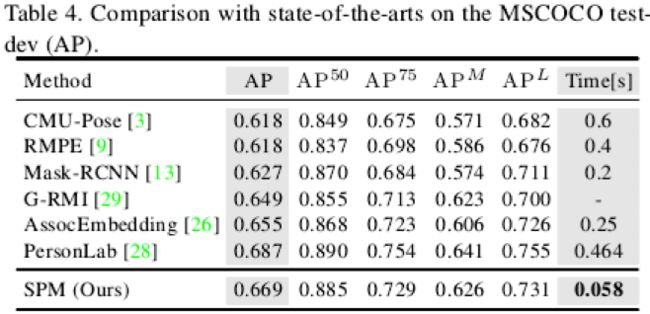
表3和表4分别展示了SPM在PASCAL-Person-Part和MSCOCO上的实验结果,同样展现了SPM在速度和准确率上的双料优势。
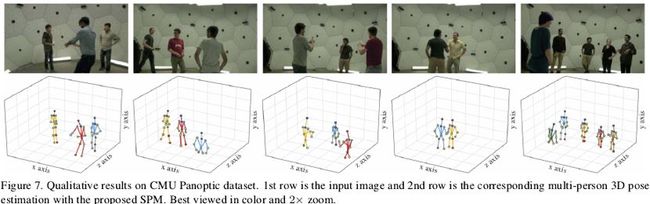
下图展示了本文方法在3D人体姿态估计数据集上的可视化示例,SPM由于框架简单,网络回归的目标均为二维表示,只需要将图像上的二维表示拓展到三维空间中的三维表示,即可扩展用于3D人体姿态估计。从图中可以发现SPM在3D人体姿态估计上也能取得不错的效果。
总结
1、人体姿态估计领域常用的基础网络为hourglass网络(本文也不例外),由于网络结构本身所带来的计算量较大导致算法耗时难尽人意。目前大部分探索集中于双阶段的解决方案,本文在人体姿态估计领域突破了传统双阶段的算法框架,首次提出了单阶段的解决方案,思路新颖独特,方法简洁且可扩展性强。在极大降低算法耗时的同时,并没有以性能损失为牺牲,为人体姿态估计领域提供一个新的baseline,期待在这一方向上出现更多的精彩突破。
2、关键点检测也是当前anchor-free目标检测领域[1]的关注热点,而本文中的关键点到root point的偏差量预测也类似于目标检测中宽和高的预测。从两个任务的共性入手,应该还有很多值得探索的问题和新的发现。
3、人体姿态估计和实例分割均属于instance-level的任务,二者在输出上有很大相似之处,最近在实例分割领域同样也掀起了一个single-stage的潮流,如yolact、yolact++ [2]和最新的solo[3]。期待更多启发性工作的出现。
参考文献
[1] 目标检测:Anchor-Free时代
[2] YOLACT++:更强的实时实例分割网络,可达33.5 FPS/34.1mAP!
[3] SOLO_ Se