类脑运算--脉冲神经网络(Spiking Neural Network)发展现状
类脑运算–脉冲神经网络(Spiking Neural Network)发展现状
前一段时间忙于博士论文的攥写和答辩, 抱歉拖更
继上一章:
类脑运算–脉冲神经网络(Spiking Neural Network)叙述
SNN是第三代人工神经网络(ANN),是一类event驱动的神经形态算法,可能具有广泛的应用领域,并适用于各种极低功耗的神经形态硬件。现阶段SNN 的应用落地和算法发展方兴未艾,工业界和学术界近几年来对其的探索和研发也从未停止。 这篇文章会从以下几个方面讨论类脑运算技术的发展概况。
- 神经形态运算平台(Neuromorphic Computing Platform)
- 神经形态传感器(Neuromorphic Sensor)
- SNN仿真软件(SNN simulators)
- 类脑运算的应用
神经形态运算平台(Neuromorphic Computing Platform)
类脑运算平台或者类脑芯片, 是受到生物学脑工作机制启发开发的专用于为SNN提供计算的硬件系统。制作类脑芯片最具有挑战性的是如何把不计其数spiking 神经元和突触放进一个小小的芯片里并同时让他们的链接结构是可调整的。
最初,类脑芯片仅由科研学术机构进行探索。 由于研究人员已经展示出这些出色的类似于大脑的计算模型的巨大潜力,因此许多大公司已开始参与类脑芯片的开发。
IBM在2014年开发了TrueNorth芯片,它是美国国防高级研究计划局SyNAPSE开发计划的一部分。 单个TruNorth芯片包含4096个计算核心,可以实现神经突触和神经元排列的动态映射。 每个内核最多可将1024个轴突电路用于输入连接,从而实现256个IF神经元,这些神经元组织为静态随机存取存储器。 IBM TrueNorth系统的一个吸引人的功能是,单个芯片由54亿个晶体管组成,仅消耗70mW的功率密度,仅占传统计算单元的1/10000。

图:TrueNorth芯片
SpiNNaker NM平台是由曼彻斯特大学的研究人员开发的,曼彻斯特大学的研究人员是由欧盟资助的“人脑计划” (Eupropean HBP)的一部分。 SpiNNaker为SNN的硬件实现提供ASIC解决方案。它利用多个ARM内核和FPGA来配置硬件和PyNN软件API,以实现平台的可扩展性。 ARM处理器使该平台能够以仅1毫秒的仿真时间步长,以生物逼真的连通性配置数十亿个脉冲神经元。此外,第二代平台SpiNNaker2仍在开发中,它可以使用1000万个处理器来模拟更大,更复杂的SNN。除SpiNNaker之外,BrainScaleS 也是HBP项目的另一个类脑计算平台。 BrainScaleS是使用晶圆级集成技术开发的混合信号神经形态芯片,该芯片允许利用4000万个突触和多达18万个神经元。正在设计下一代BarianScaleS,并将其命名为BrianScaleS-2,它能够使用更复杂的神经元模型,同时支持非线性突触和定制结构的神经元。
图: SpiNNaker中央机
SpiNNaker 平台提供SNN的云仿真和计算平台, 这就意味着如果你想试试自己的SNN在硬件上效果如何的话。你可以去SpiNNaker 云平台上 上传自己的代码,结果会由云平台返回, 前提是你的SNN需要是用PyNN构建的。
斯坦福大学在类脑领域贡献了两个类脑硬件,分别是Neurogrid和Braindrop。 Neurogrid 中的神经核由256x256制成的CMOS阵列构成,该阵列可实现SNN的混合模数实现。 Neurogrid能够以数百万个神经元和数十亿个突触的能力提供生物学上合理的计算。 像Neurogrid一样的Braindrop是一个混合信号NM处理器,但抽象程度很高。 Braindrop采用28纳米FDSOI工艺进行设计,并将4096个尖峰神经元集成在单个芯片上,该芯片的神经元容量有限,无法大规模实施SNN。

图 :斯坦福Neurogrid
英特尔Loihi 类脑芯片是英特尔最近宣布的数字神经计算平台。 Loihi最吸引人的特点是芯片在线学习的潜力。 Loihi拥有一个特殊的可编程微代码引擎,可以即时进行SNN培训。 Loihi具有3个独特的Lakemont NM核心,专门设计用于协助高级学习规则。 一个Loihi芯片中总共有128个NM内核,能够实现130K LIF神经元和130M突触。 Loihi系统的最大大小可支持多达16个芯片的4096个片上内核。

图 :英特尔Loihi 芯片
Brainchip公司开发了名为Akida神经形态计算平台,该平台可以使用一个NSoC有效地实现120万个神经元和100亿个突触。 该平台具有多个板载处理器,包括基于事件的处理,数字处理,存储器,输入/输出接口和多芯片扩展的功能。

图 :Brain Chip Akida芯
除了这些类脑芯片外,仍有许多新兴的类脑芯片在SNN计算中显示出巨大的潜力。 例如浙江大学的达尔文芯片,其目标是嵌入式低功耗应用。 苏黎世大学研究人员开发的DYNAP-SEL结合了异步数字逻辑和模拟电路,以实现模拟SNN实现。 清华大学的研究人员成功设计了混合型天机芯片 ,该混合型既可以实现常规神经网络又可以实现SNN。 如下原创表展示了各类芯片的汇总。
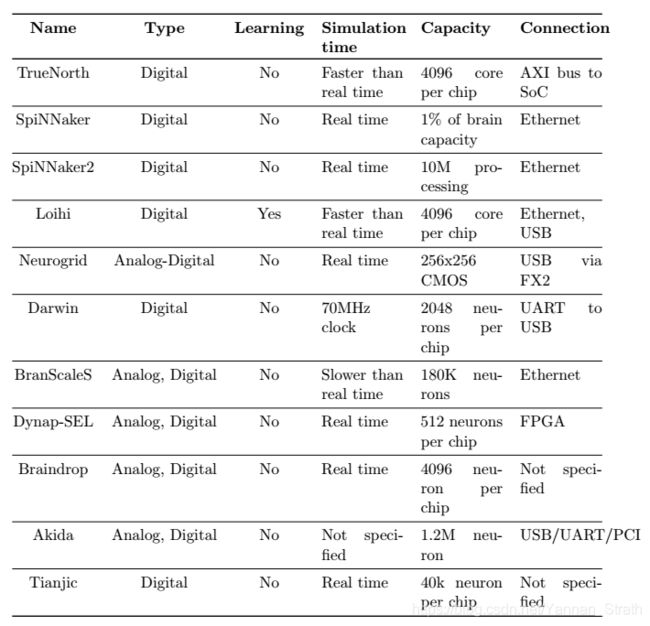
图: 类脑运算平台汇总[禁止转载]
神经形态传感器(Neuromorphic Sensor)
动态视觉传感器(Dynamic Vison Sensor)
传统的视觉传感器的经典例子是数码相机,它以预定的帧频重复刷新其整个像素值阵列。但是,使用数码相机具有动态运动识别的三个缺点。首先,数码相机通常以预定义的帧采样速率(通常范围为每秒25-50帧)运行,这限制了观察到的活动的时间分辨率。其次,连续的帧和每个帧中的冗余像素浪费了大量的存储资源和计算。第三,传统图像传感器的动态范围受到其曝光时间和集成能力的限制。大多数相机会遭受饱和线性响应,动态范围限制在60-70dB,其中自然场景的光线可以达到动态范围的约140dB。动态视觉传感器(DVS)提供了解决这些问题的方法。使用AER数据形式(Address evnet representation)的DVS是基于人类视觉系统的事件驱动技术。基于事件的传感器在动态场景识别任务中的优势在于,当场景发生很大变化时,它可以提供非常高的时间分辨率,这只能通过高速数码相机来匹配,而这通常需要大功率和大量电量,和计算资源。
图: DVS原理展示(https://gfycat.com/incredibleimpoliteblackmamba)
图: DVS视觉输出对比(https://www.ibm.com/blogs/research/2018/06/stereo-vision/)
上展示了DVS输出的示例,并与常规传感器进行了比较,其中DVS可以为快速移动的物体产生更清晰的边缘。这在对象识别和节省内存的过程中都非常重要。在DVS中,信息被编码并作为电脉冲传输,这类似于生物传感系统中的处理机制。通过将人造视网膜像素的每个活动与某个阈值进行比较,可以异步生成DVS的输出。DVS的出现证明了在超快速节能计算应用中的巨大潜力。与传统的视觉传感器相比,DVS返回非同步事件,而不是基于采样时间的帧序列。对于给定的实际输入,DVS仅记录像素强度值的变化,并输出有关极性变化的ON / OFF离散事件流。这种基于事件的获取机制具有许多优势,例如低功耗,较少的冗余信息,低延迟和高动态范围。
随着DVS的成功设计,为类脑传感器应处理的特性建立了基准,并为基于事件的视觉传感的进一步类脑运算的未来研究提供了指导。 提出了许多增强版的DVS,以改善设备的空间分辨率或动态范围。 例如Brandli等人提出了一种混合方法来解决基于帧和无帧的视觉传感问题。 DAVIS(动态和主动像素视觉传感器)在单个摄像机中集成了基于帧的主动像素感应和异步DVS感应。
动态音频传感器(Dynamic Audio Sensor)
就像DVS模仿人类视觉系统一样,动态音频传感器的工作机制也受到人类听觉系统中的感觉器官的启发。 DAS是异步事件驱动的人工耳蜗,可接收立体声音频输入。 DAS使用麦克风前置放大器和64个双耳声道,为神经形态音频感应设定了基准。 DAS集成了本地数模转换器(DAC),以允许修改每个通道中的质量因数。 通过级联的二阶模拟部分来模拟耳蜗的功能,这些模拟部分包括半波整流器,频率调制器,数模转换器,服务器放大器和缓冲器。
下图中演示了双耳DAS语音输出的示例。 图展示了DAS对语音信号的响应,其中绿色和红色分别对应于左采样通道和右采样通道,每个点都是一个采集事件。 DAS的线性调频响应如图所示,输入信号的动态频率变化范围为30Hz至10kHz。

图: DAS语音信号相应输出(https://inilabs.com/
products/dynamic-audio-sensor/)

图: DAS 线性调频信号响应(https://inilabs.com/
products/dynamic-audio-sensor/)
SNN仿真软件(SNN simulators)
尽管SNN具有许多优势,但是在模拟尖峰神经元方面的计算问题还是比较大的。 在某些情况下,像IZ神经元模型一样,需要对生物物理峰值神经元进行详细的差分表示。 另一方面,在实际应用方面,不需要现实地重建生物突波产生机理的简化神经元模型(比如IF神经元模型)。 SNN的仿真策略可以分为两个系列:同步或异步。 同步算法会在每个时间步更新所有神经元,这比异步或“事件驱动”算法会导致更高的计算资源。 异步方法仅在神经元接收或发出脉冲时更新神经元状态,就像DVS传感器的工作范式一样。
与ANN中的统一神经网络框架(例如Tensorflow 和Pytorch)不同,SNN模型和SNN的训练方法没有得到广泛一致的统一化。 模拟SNN的方法仍然是多种多样且客观的。 当前,设计SNN的过程不仅考虑了网络本身的可行性,而且还可以扩展到诸如生物学上的合理性,计算成本和学习机制之类的功能。 为了全面回顾SNN的软件实现,下表总结了noticeable的SNN框架,其中包括这些框架的特点。
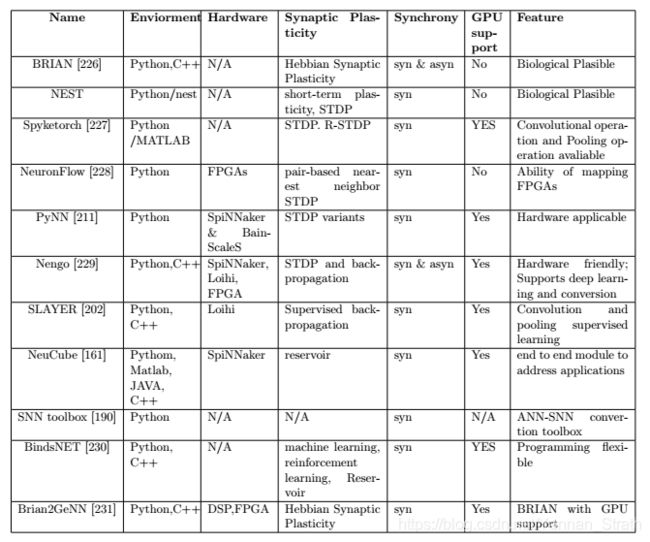
图: SNN软件框架汇总[禁止转载]
类脑运算的应用
在目前, 类脑运算虽然仍处于科研阶段, 但各界大牛的应用示例层出不穷。 SNN的优势在个人看法而言, 体现在 如果一个系统同时具有传感器,芯片,和强大的SNN算法,它的功耗和运行速度是传统ANN,DNN所不能匹敌的。 但就现有的学习算法而言, SNN在和DNN对比上对各类任务的表现(比如识别准确率)还差强人意。
Diehl 在2015年paper “Unsupervised learning of digit recognition using spike-timing-dependent plasticity” 中实现了STDP和侧面抑制结合的WTA学习方法, SNN通过非监督式的学习方法可以在MNIST手写数字识别的数据库上达到95% 的准确率。
2017年的CVPR上, TrueNorth团队在TrueNorth芯片上实现了实时的动态手势识别。虽然此方法是基于传统深度学习的模型,但整个系统的功耗大概只有200mW和105ms的延迟(1秒10帧)。
清华大学天机芯片团队,2019年Nature上发表了使用混合神经网络驱动自动驾驶自行车的例子。这里包涵了传统ANN和SNN的信号处理融合。
https://www.nature.com/articles/s41586-019-1424-8
在非监督式学习没有重大的突破的情况下, 研究人员们开始转向使用ANN-SNN转换或者直接将Backpropagation 塞进SNN里用于提高各项任务的准确率。这样的算法比如有SLAYER在语音识别TIDIGIT上取得99.09%的识别准确率。
总结一下, 现阶段SNN的应用方向应总结为两类。
1, 是以神经形态传感器为驱动的比如利用DVS,DAS在目标传感上的优势来构建应用,因为SNN对于处理他们相应的AER输出有天生的优势。
2.,是以低功耗应用落地为驱动的。因为类脑芯片和SNN最大的优势在于此, 尽管可能在具体任务上SNN的表现不如传统嵌入式系统+DNN的模式, 但SNN在一些物联网, 功率有限的设备应用上将展现巨大的优势。
国内外类脑机构/公司总结
这里概括一下作者已经发现的或者感兴趣的类脑团队供读者们进一步了解,先后顺序不代表排名。
国内:
- 清华大学类脑计算研究中心(天机芯片团队)
- 华为中央研究院
- 之江实验室
- 浙江大学达尔文芯片团队
- 鹏城实验室
- 中国科学院自动化研究所类脑智能研究中心
- 灵汐科技(天机芯片)
- 西井科技
- 时识科技Synsense(苏黎世DYNAP芯团队)
国外:
- 曼彻斯特SpiNNaker团队
- 欧盟HBP计划团队
- 苏黎世神经信息研究所(DYNAP,DVS,DAS团队)
- Inilab(DVS 团队)
- 滑铁卢大学(Nengo团队)
- Intel (Loihi芯片团队)
- IBM (TrueNorth团队)
- 斯坦福大学(Braindrop和Neurogrid团队)
- 德黑兰大学 (Spyketorch框架团队)