1.Tuning Process
对超参数的一个调试处理

一般而言,在调试超参数的过程中,我们通常将学习率learning_rate看作是最重要的一个超参数,其次是动量梯度下降因子β(一般为0.9),隐藏层单元个数,mini-batch size,再然后是layers,learning rate decacy. 当然,这并不是绝对的.
在adam算法中,β1,β2,ε通常取值为0.9,0.999,10-8
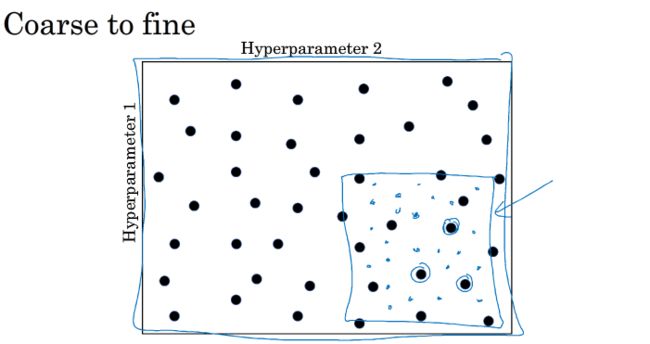
调试超参数的方法:随机取值

假设我们要调试两个超参数α和ε,每一个都有25种取值情况,在传统的机器学习算法中,会根据其数值范围,等分为5种情况,如上左图,这样构成了一个5X5的点阵,在从其中选取点来进行调试,这种方法参数较少的时候效果比较好,但是其中ε影响比较小,这样我们相当于只实验了5个α值,不能确保能取到最好的参数α.实际问题中,常采用随机取值的方法.
随机选取α与ε的组合来进行调试,在进行随机选取之后,我们可以采用Coarse to fine的方法,即对表现较好的随机选取的组合在进行一个细化,将其整个区域放大,再来选取调试,如下:
2.Using an appropriate scale to pick hyperparameters
我们可以使用一个标准的标尺来随机选取某些超参数,如下:

但是,对于某些超参数的选取,我们要进行一个log scale

如:当我们要选取学习率α从0.0001-1时,如果我们使用一个均匀的标尺,那么出现在0.1-1的概率比较大,而实际上,学习率α在这个范围的可能表现效果不太好,对此,可以进行一个log scale
即对其进行一个求对数的操作,然后在选取的随机数后进行一个对应的幂运算就能得到随机的结果,如上图所示.
对于指数加权平均中的β,也是运用相同的方法,只是β的范围一般为0.9-0.999,采用log scale 时要用1-β,在采取与上图相同的方法,至于为什么这么做,因为1/1-β,β越大时,越灵敏,假设β为0.9000变化到0.9005,那么它基本没太大变化,而从0.999-0.9995则变化非常大,所以取接近1的值应该更密集一些
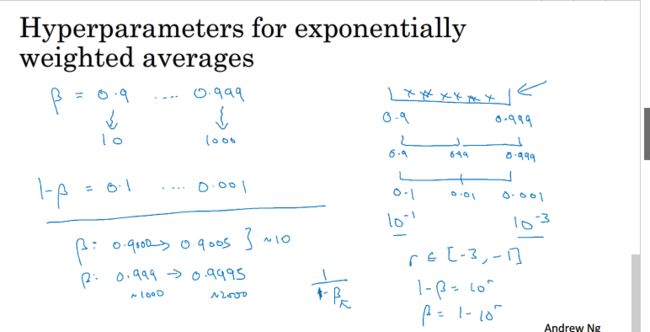
3.Hyperparameters tuning in practice:Panda vs Caviar
根据调试选择的超参数往往不是一成不变的,经过一段时间后,根据实际的情况我们往往需要重新调试
根据我们所拥有的计算能力的不同,我们可以构建一个模型或多个模型同时训练来获取最优参数组合

用一个模型时,我们会对其参数不停的调试优化
如果所拥有的计算能力大,可以选择不同的参数组合,构成不同的模型,对其进行同时训练,来找到最好的结果,对于复杂的计算能力大的,我们往往采用第一种
4.Normalizing activations in a network
之前我们已经了解了规格化输入层的输入,能够加快训练速度,那么能否规格化l-1层的a[l-1],让l层的w,b更加迅速的训练得到呢
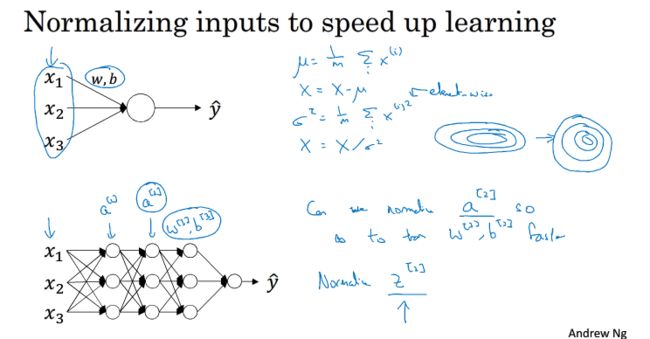
答案是肯定的,在实际中我们往往对z[l-1]进行一个规格化,而不是a[l-1]
之前对训练集输入的归一化过程如上图,得到的结果是一个均值为0,方差为1的向量,对z[l-1]的规格化,我们往往不一定希望得到均值为0,方差为1的结果,所以对其进行如下处理:

通过调整γ与β的取值,我们可以得到任意均值,方差的结果,如上右图,其中γ与β是可学习的参数
5.Fitting Batch norm into a neural network
如果把对z[l-1]的规格化用于batch中,则过程如下:
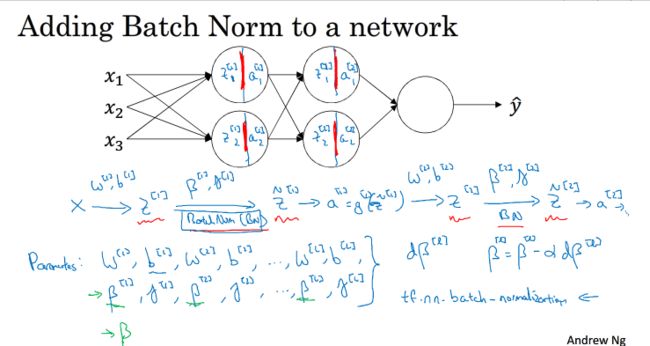
上述过程如果利用框架的话,可以一行代码就完成
值得一提的是,我们可以把b[l]省略,因为对z[l-1]进行了一个求平均,然后减去平均,这样,常数项b便对其不构成影响,而是通过规格化后调整β对其进行一个偏移
对mini-batch采用规格化与之前类似,过程如下:

在使用梯度下降算法时,分别对W [l] , β[l] 和γ [l] 进行迭代更新。除了传统的梯度下降算法之外,还可以使用我们之前介绍过的动量梯度下降、RMSprop或者Adam等优化算法。
6.why does Batch Norm work

假设我们训练了浅层网络,其中训练样本为黑色的猫,测试样本为各种颜色的猫,这种训练样本和测试样本分布不同的情况称为convirate shift.
这种情况下我们往往需要对模型进行一个重新训练
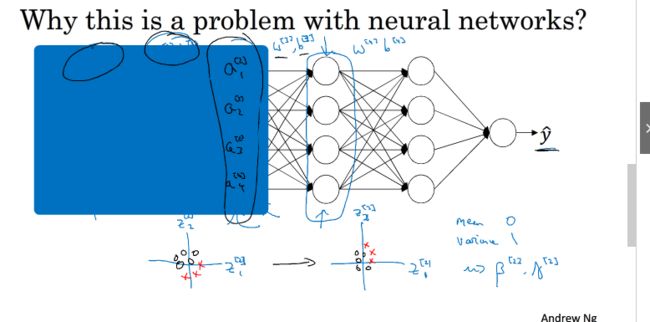
重新训练后,各个w[l],b[l]都会发生一个偏移,而batch norm可以减弱convirate shift,使模型更加的稳定,batch norm对每一层都进行了一个均值与方差化的处理,减少了之前层因的w,b变化所带来的影响,使每一层变得更加的独立
BN也有一些类似正则化的地方:

每一个mini-batch 都会进行一个均值,方差的归一化计算
这会增加一些noise对于z~[l],因为每一个mini batch的情况不同,均值和方差也会有一些小noise,有些类似dropout正则化,对于每一个隐藏层的激活函数会增加noise,dropout增加noise是因为随机删除神经元,导致计算的z[l]具有噪音,如果你想增强dropout的正则化效果,可以使用BN.
mini-batch size越大,BN的正则化效果越弱,因为size越大,均值方差的noise也会越小,计算得到的Z~[l]噪音也越小,bn起到的正则化效果也就弱了
7.Batch Norm at test time
BN的测试
训练的时候BN 所涉及到的μ和σ2都是mini-batch的,但测试的时候,μ和σ2怎么解决,测试一个样本的话,求μ和σ2是没有意义的

在实际中,我们往往采用指数加权平均来对μ和σ2进行一个估计,具体做法如上:假设我们要求第l层的μ和σ2,可以将每一个mini-batch中的μ和σ2求出来,然后应用指数加权平均对μ和σ2进行一个估计,再利用训练过程得到的γ 和β 值计算出各层的z ~ (i)
8.softmax regression
之前所学的都是二分类问题,对于两类问题的分类,如果是更多的分类情况可以使用softmax
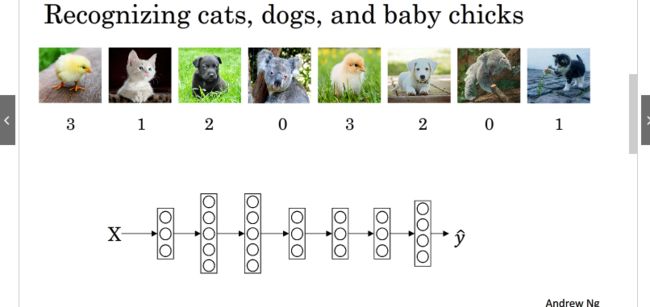
如图,要分4个类别需要使用softmax,我们定义C=4,它的激活函数为
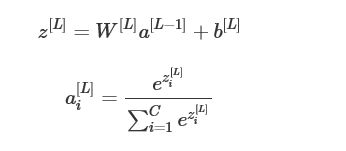
其中a_i[L]即属于该类的概率
9.Trying a softmax classifier
训练一个softmax 与二分类问题有些不同,不同之处在于正向传播的输出层的激活函数不同,计算loss function时的表达式也不同,计算softmax的loss function和cost function的表达式如下:

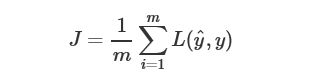
,反向传播的推导过程也不同,如下:

向量化后,dZ=A[l]-Y,其结果与二分类的结果相同
10.deep learning framwork
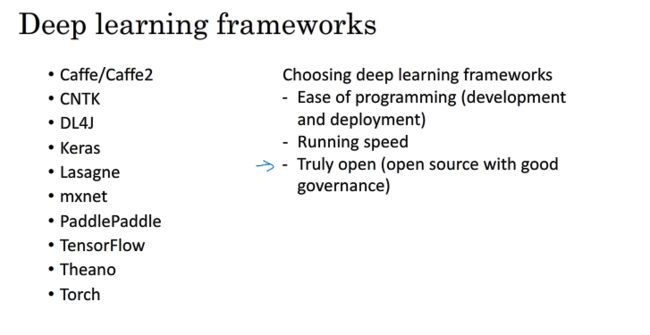
深度学习框架很多,选择原则如上:易与开发,运行速度快,在很长一段时间内会保持开源.
11.Tensorflow

具体就不做描述了..