【darknet源码解析-18】convolutional_layer.h 和 convolutional_layer 解析
本系列为darknet源码解析,本次解析为src/convolutional_layer.h 和 src/convolutional_layer.c 两个,convolutional_layer主要是构建卷积层。
- 卷积前向传播
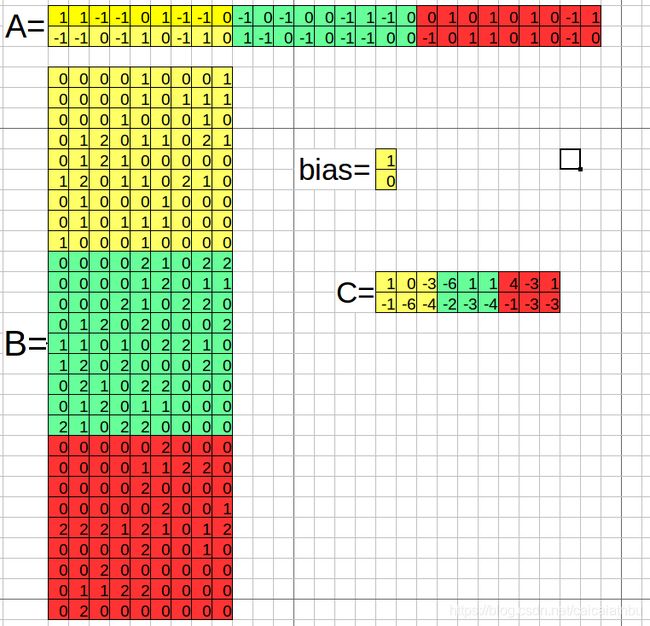
卷积操作如下图所示:在这里batch=1,输入图片h*w为5*5,通道数c为3;卷积模板数n为2,卷积核大小size为3*3,卷积步幅stride为1,补零个数pad为1;
1. 计算卷积后特征图的大小? out_h = (h + 2*pad - size)/stride + 1,out_w = (w + 2*pad - size)/stride + 1;
2. 卷积核的权重值有多少个?n个卷积模板,每个模板权重参数个数 c*size*size;
3. 卷积有多少偏置值?每个卷积模板一个偏置,则有n个偏置;
4. im2col(), gemm()在前向计算怎么使用的?im2col()将每张图片重排为B=[c*size*size, out_w*out_h],n个卷积组成A=[n, c*size*size], gemm()完成卷积元素(实际上就是矩阵乘法)卷积后输出结果C=A*B=[n, out_w*out_h];
总结起来,卷积前向传播就4个过程。详细见下面代码部分;
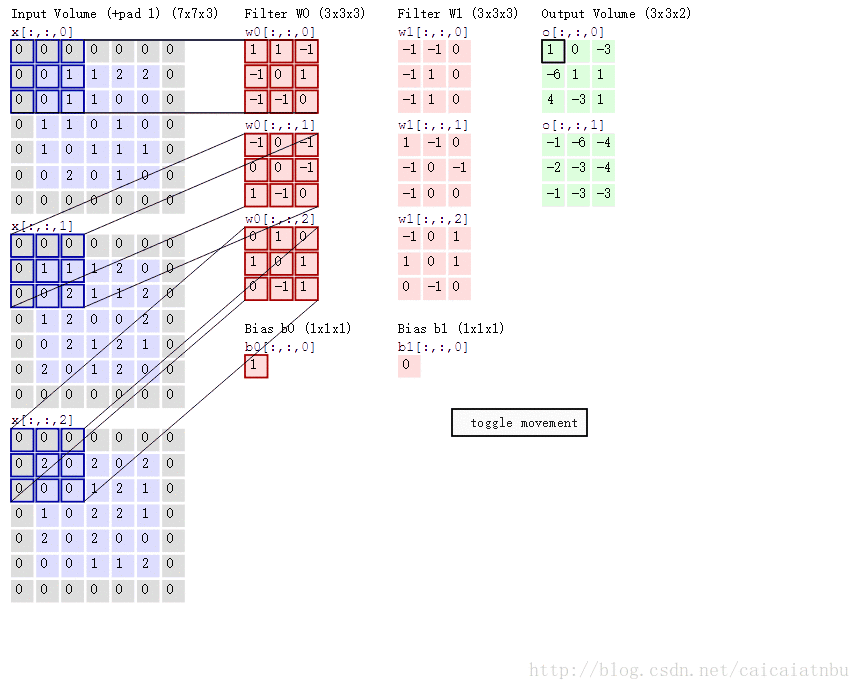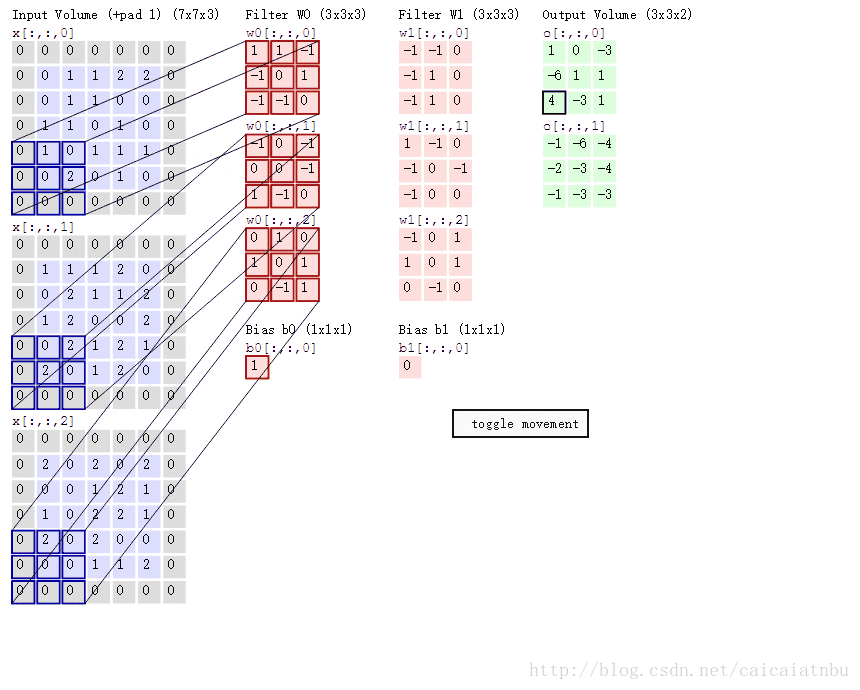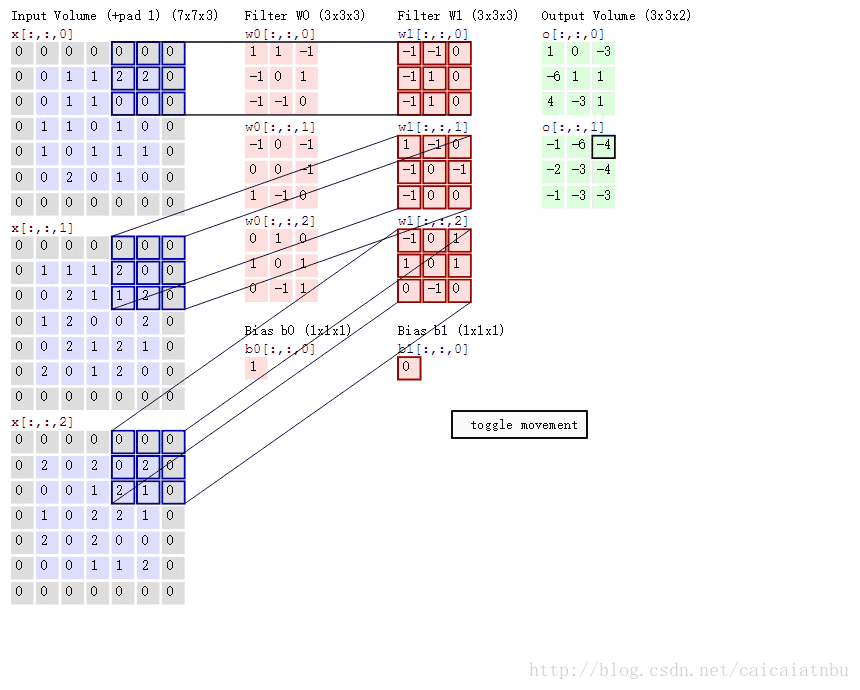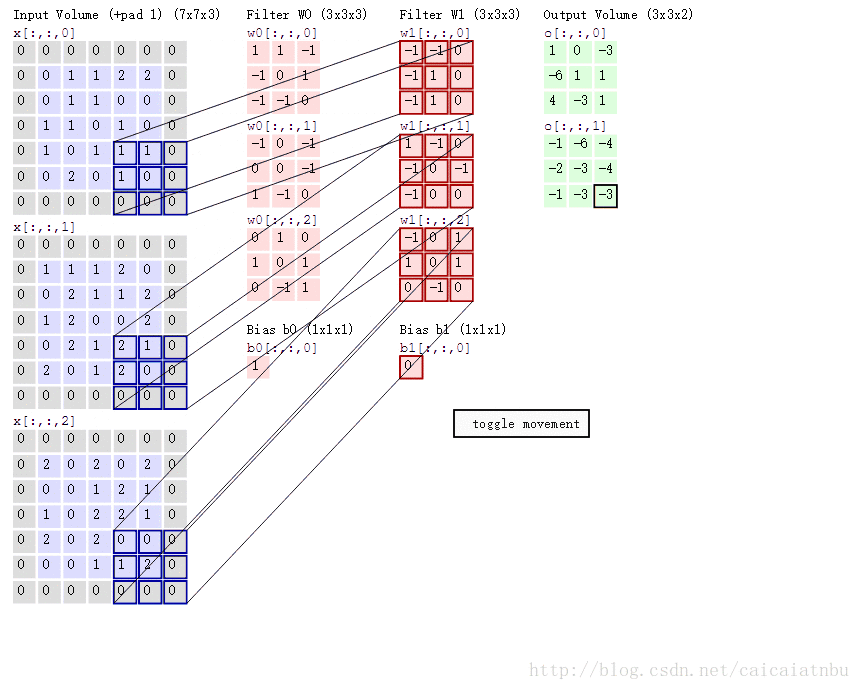
针对上面的过程,计算的过程,如下图所示:第一步C=A*B,在这里是加上偏置了,在convolutional_layer中,并没有直接加上,因为如果后边接着BN层,则直接可以忽略bias,如果没有BN层,则加上偏置;
- 卷积反向传播
反向主要求loss对偏置的梯度,以及loss对每个卷积模板权重的求导;再求二者的梯度之间,首先需要计算当前卷积层的误差项l.delta,l.delta的维度为[n, out_w*out_h],跟在全连接层中的分析一样,建议先回想一下BP算法的误差反传;
![]() , ...,
, ...,![]() , 其中的这个
, 其中的这个 就是激活函数;
就是激活函数;![]() ,
,
前向传播:im2col()将每张图片重排为B=[c*size*size, out_w*out_h],n个卷积组成A=[n, c*size*size], gemm()完成卷积元素(实际上就是矩阵乘法)卷积后输出结果C=A*B=[n, out_w*out_h];
1. 求当前卷积层的误差项?l.delta = net.delta * 激活函数加权输入的导数值,![]()
2. 对偏置的梯度?其实就是l.delta, 对应batch,对应通道进行相加,最后得到 n维 ![]()
3. 对权重的梯度?l.delta * 每张输入图片的重排矩阵的转置,[n, out_w*out_h] * [c*size*size, out_w*out_h]^T ,![]()
4. 求下一层的误差项?未更新的权重转置 * l.delta,[n, c*size*size]^T * [n, out_w*out_h] 得到[c*size*size, out_w*out_h], 然后运用col2img,将[c*size*size, out_w*out_h]转换为 [c, w*h],![]()
【注】:rot180角度来思考反传,请参看一文:https://blog.csdn.net/zy3381/article/details/44409535
convolutional_layer.h 详细解析如下:
#ifndef CONVOLUTIONAL_LAYER_H
#define CONVOLUTIONAL_LAYER_H
#include "cuda.h"
#include "image.h"
#include "activations.h"
#include "layer.h"
#include "network.h"
typedef layer convolutional_layer;
#ifdef GPU
void forward_convolutional_layer_gpu(convolutional_layer layer, network net);
void backward_convolutional_layer_gpu(convolutional_layer layer, network net);
void update_convolutional_layer_gpu(convolutional_layer layer, update_args a);
void push_convolutional_layer(convolutional_layer layer);
void pull_convolutional_layer(convolutional_layer layer);
void add_bias_gpu(float *output, float *biases, int batch, int n, int size);
void backward_bias_gpu(float *bias_updates, float *delta, int batch, int n, int size);
void adam_update_gpu(float *w, float *d, float *m, float *v, float B1, float B2, float eps, float decay, float rate, int n, int batch, int t);
#ifdef CUDNN
void cudnn_convolutional_setup(layer *l);
#endif
#endif
// 构建卷积层
convolutional_layer make_convolutional_layer(int batch, int h, int w, int c, int n, int groups, int size, int stride, int padding, ACTIVATION activation, int batch_normalize, int binary, int xnor, int adam);
void resize_convolutional_layer(convolutional_layer *layer, int w, int h);
// 卷积层的前向传播函数
void forward_convolutional_layer(const convolutional_layer layer, network net);
// 卷积层的权值更新函数
void update_convolutional_layer(convolutional_layer layer, update_args a);
image *visualize_convolutional_layer(convolutional_layer layer, char *window, image *prev_weights);
void binarize_weights(float *weights, int n, int size, float *binary);
void swap_binary(convolutional_layer *l);
void binarize_weights2(float *weights, int n, int size, char *binary, float *scales);
// 卷积层的反向传播函数
void backward_convolutional_layer(convolutional_layer layer, network net);
// 加偏置
void add_bias(float *output, float *biases, int batch, int n, int size);
// 计算每个卷积核的偏置更新值
void backward_bias(float *bias_updates, float *delta, int batch, int n, int size);
image get_convolutional_image(convolutional_layer layer);
image get_convolutional_delta(convolutional_layer layer);
image get_convolutional_weight(convolutional_layer layer, int i);
// 计算卷积后得到特征图的高度,宽度
int convolutional_out_height(convolutional_layer layer);
int convolutional_out_width(convolutional_layer layer);
#endif
convolutional_layer.c 详细解析如下:
#include "convolutional_layer.h"
#include "utils.h"
#include "batchnorm_layer.h"
#include "im2col.h"
#include "col2im.h"
#include "blas.h"
#include "gemm.h"
#include
#include
#ifdef AI2
#include "xnor_layer.h"
#endif
void swap_binary(convolutional_layer *l)
{
float *swap = l->weights;
l->weights = l->binary_weights;
l->binary_weights = swap;
#ifdef GPU
swap = l->weights_gpu;
l->weights_gpu = l->binary_weights_gpu;
l->binary_weights_gpu = swap;
#endif
}
void binarize_weights(float *weights, int n, int size, float *binary)
{
int i, f;
for(f = 0; f < n; ++f){
float mean = 0;
for(i = 0; i < size; ++i){
mean += fabs(weights[f*size + i]);
}
mean = mean / size;
for(i = 0; i < size; ++i){
binary[f*size + i] = (weights[f*size + i] > 0) ? mean : -mean;
}
}
}
void binarize_cpu(float *input, int n, float *binary)
{
int i;
for(i = 0; i < n; ++i){
binary[i] = (input[i] > 0) ? 1 : -1;
}
}
void binarize_input(float *input, int n, int size, float *binary)
{
int i, s;
for(s = 0; s < size; ++s){
float mean = 0;
for(i = 0; i < n; ++i){
mean += fabs(input[i*size + s]);
}
mean = mean / n;
for(i = 0; i < n; ++i){
binary[i*size + s] = (input[i*size + s] > 0) ? mean : -mean;
}
}
}
/**
* 计算卷积层输出的特征图高度函数
* 根据输入图像的高度(h),两边补0的个数(pad),卷积核尺寸(size)以及卷积步幅(stride)计算输出特征图的高度
* @param l 当前卷积层
* @return
*
* 说明:此函数只是在构建网络时调用一次,之后就不调用了
* 但l比较大,按值传递复制过程冗长,可改善一下。如只输入用到的4个参数,或者传入l的指针,
* 这样不用返回值,直接在函数内部为l.out_h赋值
*/
int convolutional_out_height(convolutional_layer l)
{
// pad是每边补0的个数,因此乘以2
// 当stride=1, pad=size/2 (整数除法,会往下取整)时,输出高度就等于输入高度(SAME策略);
// 当stride=1, pad=0时 (VALID策略);
// 当stride!=1时, 输出高度恒小于输入高度(尺度一定会缩小);
// 计算公式推导: 设输高度为x, 总图像高度为 h+2*pad个像素,输出高度为x,则共有x-1次卷积核移位
// 共占有(x-1)*stride+size个像素,可能还剩下res个像素,且res肯定小于stride(否则还可以移位一次),
// 因此有(x-1)*stride+size+res=h+2*pad, -> x = (h+2*pad - size)/stride + 1;
return (l.h + 2*l.pad - l.size) / l.stride + 1;
}
/**
* 计算卷积层输出的特征图的宽度函数
* 根据输入图像的高度(h),两边补0的个数(pad),卷积核尺寸(size)以及卷积步幅(stride)计算输出特征图的宽度
* 与上一个函数convolutional_out_height 类似,这里不再详细解释
* @param l 当前卷积层
* @return
*/
int convolutional_out_width(convolutional_layer l)
{
return (l.w + 2*l.pad - l.size) / l.stride + 1;
}
image get_convolutional_image(convolutional_layer l)
{
return float_to_image(l.out_w,l.out_h,l.out_c,l.output);
}
image get_convolutional_delta(convolutional_layer l)
{
return float_to_image(l.out_w,l.out_h,l.out_c,l.delta);
}
/**
* 计算workspace的大小
* @param l 当前卷积层
* @return
*/
static size_t get_workspace_size(layer l){
#ifdef CUDNN
if(gpu_index >= 0){
size_t most = 0;
size_t s = 0;
cudnnGetConvolutionForwardWorkspaceSize(cudnn_handle(),
l.srcTensorDesc,
l.weightDesc,
l.convDesc,
l.dstTensorDesc,
l.fw_algo,
&s);
if (s > most) most = s;
cudnnGetConvolutionBackwardFilterWorkspaceSize(cudnn_handle(),
l.srcTensorDesc,
l.ddstTensorDesc,
l.convDesc,
l.dweightDesc,
l.bf_algo,
&s);
if (s > most) most = s;
cudnnGetConvolutionBackwardDataWorkspaceSize(cudnn_handle(),
l.weightDesc,
l.ddstTensorDesc,
l.convDesc,
l.dsrcTensorDesc,
l.bd_algo,
&s);
if (s > most) most = s;
return most;
}
#endif
return (size_t)l.out_h*l.out_w*l.size*l.size*l.c/l.groups*sizeof(float);
}
#ifdef GPU
#ifdef CUDNN
void cudnn_convolutional_setup(layer *l)
{
cudnnSetTensor4dDescriptor(l->dsrcTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, l->batch, l->c, l->h, l->w);
cudnnSetTensor4dDescriptor(l->ddstTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, l->batch, l->out_c, l->out_h, l->out_w);
cudnnSetTensor4dDescriptor(l->srcTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, l->batch, l->c, l->h, l->w);
cudnnSetTensor4dDescriptor(l->dstTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, l->batch, l->out_c, l->out_h, l->out_w);
cudnnSetTensor4dDescriptor(l->normTensorDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, l->out_c, 1, 1);
cudnnSetFilter4dDescriptor(l->dweightDesc, CUDNN_DATA_FLOAT, CUDNN_TENSOR_NCHW, l->n, l->c/l->groups, l->size, l->size);
cudnnSetFilter4dDescriptor(l->weightDesc, CUDNN_DATA_FLOAT, CUDNN_TENSOR_NCHW, l->n, l->c/l->groups, l->size, l->size);
#if CUDNN_MAJOR >= 6
cudnnSetConvolution2dDescriptor(l->convDesc, l->pad, l->pad, l->stride, l->stride, 1, 1, CUDNN_CROSS_CORRELATION, CUDNN_DATA_FLOAT);
#else
cudnnSetConvolution2dDescriptor(l->convDesc, l->pad, l->pad, l->stride, l->stride, 1, 1, CUDNN_CROSS_CORRELATION);
#endif
#if CUDNN_MAJOR >= 7
cudnnSetConvolutionGroupCount(l->convDesc, l->groups);
#else
if(l->groups > 1){
error("CUDNN < 7 doesn't support groups, please upgrade!");
}
#endif
cudnnGetConvolutionForwardAlgorithm(cudnn_handle(),
l->srcTensorDesc,
l->weightDesc,
l->convDesc,
l->dstTensorDesc,
CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT,
4000000000,
&l->fw_algo);
cudnnGetConvolutionBackwardDataAlgorithm(cudnn_handle(),
l->weightDesc,
l->ddstTensorDesc,
l->convDesc,
l->dsrcTensorDesc,
CUDNN_CONVOLUTION_BWD_DATA_SPECIFY_WORKSPACE_LIMIT,
4000000000,
&l->bd_algo);
cudnnGetConvolutionBackwardFilterAlgorithm(cudnn_handle(),
l->srcTensorDesc,
l->ddstTensorDesc,
l->convDesc,
l->dweightDesc,
CUDNN_CONVOLUTION_BWD_FILTER_SPECIFY_WORKSPACE_LIMIT,
4000000000,
&l->bf_algo);
}
#endif
#endif
/**
* 构建卷积层
* @param batch 每个batch含有的图片数量
* @param h 图片高度
* @param w 图片宽度
* @param c 输入图像channel数量
* @param n 卷积核的个数
* @param groups 这个参数目前仅发现用在softmax_layer中,含义是将一张图片的数据分成几组,具体的值由网络配置文件指定,如未指定默认为1
* 见parse_softmax(),所以在此处就忽略groups,认为它是常量1
* @param size 卷积核的尺寸
* @param stride 卷积核的步幅
* @param padding 补0的个数
* @param activation 激活函数类型
* @param batch_normalize 是否进行BN操作
* @param binary 是否对权重进行二值化
* @param xnor 是否对权重以及输入进行二值化
* @param adam 是否使用adam
* @return
*/
convolutional_layer make_convolutional_layer(int batch, int h, int w, int c, int n, int groups, int size, int stride, int padding, ACTIVATION activation, int batch_normalize, int binary, int xnor, int adam)
{
int i;
convolutional_layer l = {0};
l.type = CONVOLUTIONAL; // 层类别
l.groups = groups; // 常数1
l.h = h; // 输入特征图的高度
l.w = w; // 输入特征图的宽度
l.c = c; // 输入特征图的通道数
l.n = n; // 卷积核个数
l.binary = binary; // 是否对权重进行二值化
l.xnor = xnor; //是否对权重以及输入进行二值化
l.batch = batch; // batch大小
l.stride = stride; // 卷积核步幅
l.size = size; // 卷积核尺寸
l.pad = padding; // 补0的个数
l.batch_normalize = batch_normalize; // 是否进行BN操作
// 该卷积层总的权重元素(卷积核数量)个数=输入图像通道数×卷积核的个数×卷积核的二维尺寸
// 因为一个卷积核的作用在输入图片的所有通道上,所有实际含有的卷积核参数个数需要乘以输入图片的通道数;
l.weights = calloc(c/groups*n*size*size, sizeof(float));
l.weight_updates = calloc(c/groups*n*size*size, sizeof(float));
// bias就是Wx+b中的b(上面weights就是W),有多少个卷积核,就有多少个b(与W的个数一一对象,每个W的元素个数为c×size×size)
l.biases = calloc(n, sizeof(float));
l.bias_updates = calloc(n, sizeof(float));
// 该卷积层总的权重元素个数(权重元素个数等于输入数据的通道数×卷积核个数×卷积核的二维尺寸)
// 注意因为每一个卷积核是同时作用在输入数据的多个通道;
// 因此实际上卷积是三维的,包括两个维度的平面尺寸,以及输入数据通道数这个维度。
// 每个通道上的卷积核参数都是独立训练的参数;
l.nweights = c/groups*n*size*size; //权重元素个数
l.nbiases = n; // 偏置数量
// float scale = 1./sqrt(size*size*c);
// 初始化权重:使用He初始化方法。缩放因子×标准正态分布随机数,缩放因子等于sqrt(2./(size*size*c))
float scale = sqrt(2./(size*size*c/l.groups));
//printf("convscale %f\n", scale);
//scale = .02;
//for(i = 0; i < c*n*size*size; ++i) l.weights[i] = scale*rand_uniform(-1, 1);
for(i = 0; i < l.nweights; ++i) l.weights[i] = scale*rand_normal();
// 根据该层输入特征图的大小,卷积核尺寸和步幅,以及补0的个数来计算输出特征图的宽度和高度
int out_w = convolutional_out_width(l);
int out_h = convolutional_out_height(l);
l.out_h = out_h; //输出特征图高度
l.out_w = out_w; //输出特征图宽度
l.out_c = n; //输出特征图通道数
l.outputs = l.out_h * l.out_w * l.out_c; // 卷积层对应一张输入图片输出元素个数
l.inputs = l.w * l.h * l.c; // 卷积层一张输入图片的元素个数
l.output = calloc(l.batch*l.outputs, sizeof(float)); // 卷积层所有输出(包含整个batch的)
l.delta = calloc(l.batch*l.outputs, sizeof(float)); // 卷积层误差项(包含整个batch的)
l.forward = forward_convolutional_layer; // 卷积层前向传播
l.backward = backward_convolutional_layer; // 卷积层反向传播
l.update = update_convolutional_layer; // 卷积层更新
if(binary){
l.binary_weights = calloc(l.nweights, sizeof(float));
l.cweights = calloc(l.nweights, sizeof(char));
l.scales = calloc(n, sizeof(float));
}
if(xnor){
l.binary_weights = calloc(l.nweights, sizeof(float));
l.binary_input = calloc(l.inputs*l.batch, sizeof(float));
}
if(batch_normalize){ // 是否进行归一化
l.scales = calloc(n, sizeof(float));
l.scale_updates = calloc(n, sizeof(float));
for(i = 0; i < n; ++i){
l.scales[i] = 1;
}
l.mean = calloc(n, sizeof(float));
l.variance = calloc(n, sizeof(float));
l.mean_delta = calloc(n, sizeof(float));
l.variance_delta = calloc(n, sizeof(float));
l.rolling_mean = calloc(n, sizeof(float));
l.rolling_variance = calloc(n, sizeof(float));
l.x = calloc(l.batch*l.outputs, sizeof(float));
l.x_norm = calloc(l.batch*l.outputs, sizeof(float));
}
if(adam){ //采用adam,仅在gpu版本使用
l.m = calloc(l.nweights, sizeof(float));
l.v = calloc(l.nweights, sizeof(float));
l.bias_m = calloc(n, sizeof(float));
l.scale_m = calloc(n, sizeof(float));
l.bias_v = calloc(n, sizeof(float));
l.scale_v = calloc(n, sizeof(float));
}
#ifdef GPU
l.forward_gpu = forward_convolutional_layer_gpu;
l.backward_gpu = backward_convolutional_layer_gpu;
l.update_gpu = update_convolutional_layer_gpu;
if(gpu_index >= 0){
if (adam) {
l.m_gpu = cuda_make_array(l.m, l.nweights);
l.v_gpu = cuda_make_array(l.v, l.nweights);
l.bias_m_gpu = cuda_make_array(l.bias_m, n);
l.bias_v_gpu = cuda_make_array(l.bias_v, n);
l.scale_m_gpu = cuda_make_array(l.scale_m, n);
l.scale_v_gpu = cuda_make_array(l.scale_v, n);
}
l.weights_gpu = cuda_make_array(l.weights, l.nweights);
l.weight_updates_gpu = cuda_make_array(l.weight_updates, l.nweights);
l.biases_gpu = cuda_make_array(l.biases, n);
l.bias_updates_gpu = cuda_make_array(l.bias_updates, n);
l.delta_gpu = cuda_make_array(l.delta, l.batch*out_h*out_w*n);
l.output_gpu = cuda_make_array(l.output, l.batch*out_h*out_w*n);
if(binary){
l.binary_weights_gpu = cuda_make_array(l.weights, l.nweights);
}
if(xnor){
l.binary_weights_gpu = cuda_make_array(l.weights, l.nweights);
l.binary_input_gpu = cuda_make_array(0, l.inputs*l.batch);
}
if(batch_normalize){
l.mean_gpu = cuda_make_array(l.mean, n);
l.variance_gpu = cuda_make_array(l.variance, n);
l.rolling_mean_gpu = cuda_make_array(l.mean, n);
l.rolling_variance_gpu = cuda_make_array(l.variance, n);
l.mean_delta_gpu = cuda_make_array(l.mean, n);
l.variance_delta_gpu = cuda_make_array(l.variance, n);
l.scales_gpu = cuda_make_array(l.scales, n);
l.scale_updates_gpu = cuda_make_array(l.scale_updates, n);
l.x_gpu = cuda_make_array(l.output, l.batch*out_h*out_w*n);
l.x_norm_gpu = cuda_make_array(l.output, l.batch*out_h*out_w*n);
}
#ifdef CUDNN
cudnnCreateTensorDescriptor(&l.normTensorDesc);
cudnnCreateTensorDescriptor(&l.srcTensorDesc);
cudnnCreateTensorDescriptor(&l.dstTensorDesc);
cudnnCreateFilterDescriptor(&l.weightDesc);
cudnnCreateTensorDescriptor(&l.dsrcTensorDesc);
cudnnCreateTensorDescriptor(&l.ddstTensorDesc);
cudnnCreateFilterDescriptor(&l.dweightDesc);
cudnnCreateConvolutionDescriptor(&l.convDesc);
cudnn_convolutional_setup(&l);
#endif
}
#endif
l.workspace_size = get_workspace_size(l); // 计算workspace大小
l.activation = activation; // 激活函数类型
fprintf(stderr, "conv %5d %2d x%2d /%2d %4d x%4d x%4d -> %4d x%4d x%4d %5.3f BFLOPs\n", n, size, size, stride, w, h, c, l.out_w, l.out_h, l.out_c, (2.0 * l.n * l.size*l.size*l.c/l.groups * l.out_h*l.out_w)/1000000000.);
return l;
}
void denormalize_convolutional_layer(convolutional_layer l)
{
int i, j;
for(i = 0; i < l.n; ++i){
float scale = l.scales[i]/sqrt(l.rolling_variance[i] + .00001);
for(j = 0; j < l.c/l.groups*l.size*l.size; ++j){
l.weights[i*l.c/l.groups*l.size*l.size + j] *= scale;
}
l.biases[i] -= l.rolling_mean[i] * scale;
l.scales[i] = 1;
l.rolling_mean[i] = 0;
l.rolling_variance[i] = 1;
}
}
/*
void test_convolutional_layer()
{
convolutional_layer l = make_convolutional_layer(1, 5, 5, 3, 2, 5, 2, 1, LEAKY, 1, 0, 0, 0);
l.batch_normalize = 1;
float data[] = {1,1,1,1,1,
1,1,1,1,1,
1,1,1,1,1,
1,1,1,1,1,
1,1,1,1,1,
2,2,2,2,2,
2,2,2,2,2,
2,2,2,2,2,
2,2,2,2,2,
2,2,2,2,2,
3,3,3,3,3,
3,3,3,3,3,
3,3,3,3,3,
3,3,3,3,3,
3,3,3,3,3};
//net.input = data;
//forward_convolutional_layer(l);
}
*/
void resize_convolutional_layer(convolutional_layer *l, int w, int h)
{
l->w = w;
l->h = h;
int out_w = convolutional_out_width(*l);
int out_h = convolutional_out_height(*l);
l->out_w = out_w;
l->out_h = out_h;
l->outputs = l->out_h * l->out_w * l->out_c;
l->inputs = l->w * l->h * l->c;
l->output = realloc(l->output, l->batch*l->outputs*sizeof(float));
l->delta = realloc(l->delta, l->batch*l->outputs*sizeof(float));
if(l->batch_normalize){
l->x = realloc(l->x, l->batch*l->outputs*sizeof(float));
l->x_norm = realloc(l->x_norm, l->batch*l->outputs*sizeof(float));
}
#ifdef GPU
cuda_free(l->delta_gpu);
cuda_free(l->output_gpu);
l->delta_gpu = cuda_make_array(l->delta, l->batch*l->outputs);
l->output_gpu = cuda_make_array(l->output, l->batch*l->outputs);
if(l->batch_normalize){
cuda_free(l->x_gpu);
cuda_free(l->x_norm_gpu);
l->x_gpu = cuda_make_array(l->output, l->batch*l->outputs);
l->x_norm_gpu = cuda_make_array(l->output, l->batch*l->outputs);
}
#ifdef CUDNN
cudnn_convolutional_setup(l);
#endif
#endif
l->workspace_size = get_workspace_size(*l);
}
void add_bias(float *output, float *biases, int batch, int n, int size)
{
int i,j,b;
for(b = 0; b < batch; ++b){
for(i = 0; i < n; ++i){
for(j = 0; j < size; ++j){
output[(b*n + i)*size + j] += biases[i];
}
}
}
}
void scale_bias(float *output, float *scales, int batch, int n, int size)
{
int i,j,b;
for(b = 0; b < batch; ++b){
for(i = 0; i < n; ++i){
for(j = 0; j < size; ++j){
output[(b*n + i)*size + j] *= scales[i];
}
}
}
}
// backward_bias(l.bias_updates, l.delta, l.batch, l.n, k);
/**
* 计算每个卷积核的偏置更新值,所谓偏置,就是bias= bias - alpha * bias_update中的bias_update
* @param bias_updates 当前层所有偏置的更新值,共l.n个
* @param delta 当前层的误差项(即l.delta)
* @param batch 一个batch含有图片的张数
* @param n 当前卷积核的个数
* @param size 当前层输出特征图尺寸 l.out_w * l.out_h
*
* 原理:当前层的误差项l.delta是误差函数对加权输入的导数,也就是偏置更新值,只是其中每 l.out_w * l.out_h
* 个元素都对应同一个偏置,因此需要将其加起来,得到的和就是误差函数对当前各偏置的导数(l.delta 的维度理解为
* l.batch*l.n*l.out_h*l.out_w, 可理解成共有l.batch行,每行有l.n * l.out_h * l.out_w列,而这一大行
* 可以理解成有l.n, l.out_h * l.out_w列,这每一行就对应同一卷积也即同一偏置)
*/
void backward_bias(float *bias_updates, float *delta, int batch, int n, int size)
{
int i,b;
// 遍历batch中每张输入图片
// 注意,最后的偏置更新值是所有输入图片的总和(多张图片无非就是重复一张图片的操作,求和即可)。
// 总之:一个卷积核对应一个偏置更新值,该偏置更新值等于batch所有图片累积的偏置更新值
// 而每张图片也需要进行偏置更新值求和(因为每个卷积核在每张图片多个位置做卷积运算,这都对偏置更新值有贡献)
// 以得到每张图片的总偏置更新值。
for(b = 0; b < batch; ++b){
// 求和得到一张输入图片的总偏置更新值
for(i = 0; i < n; ++i){
//l.n = n; 卷积核的个数
bias_updates[i] += sum_array(delta+size*(i+b*n), size);
}
}
}
/**
* 卷积前向传播函数
* @param l 当前卷积层
* @param net 整个网络
*/
void forward_convolutional_layer(convolutional_layer l, network net)
{
int i, j;
// l.output 数组初始化为0
fill_cpu(l.outputs*l.batch, 0, l.output, 1);
if(l.xnor){ // 是否进行二值化操作
binarize_weights(l.weights, l.n, l.c/l.groups*l.size*l.size, l.binary_weights);
swap_binary(&l);
binarize_cpu(net.input, l.c*l.h*l.w*l.batch, l.binary_input);
net.input = l.binary_input;
}
int m = l.n/l.groups; // 卷积模板的个数
int k = l.size*l.size*l.c/l.groups; // 该层每个卷积的参数元素个数
int n = l.out_w*l.out_h; // 该层每个输出特征图的尺寸(元素个数)
// 该循环即为卷积计算核心代码:所有卷积核对batch中每张图片进行卷积运算
// 每次循环处理一张输入图片(所有卷积核对batch中一张图片做卷积运算)
for(i = 0; i < l.batch; ++i){
// 将多通道二维图像net.input变成按一定存储规则排列的数组b,以方便、高效地进行矩阵(卷积)计算,详细查看该函数注释
// 注意net.input包含batch中所有图片的数据,但是每次循环只处理一张(本循环最后一句是对net.input进行移位),因此在
// im2col_cpu 仅会对其中一张图片进行重排,l.c为每张图片的通道数,l.h为每张图片的高度,l.w为每张图片的宽度,
// l.stride 为步幅,得到的b为一张图片的重排后的结果,也是按行存储的一维数组(共有l.c*l.size*l.size行,l.out_w * l.out_h列)
for(j = 0; j < l.groups; ++j){
float *a = l.weights + j*l.nweights/l.groups; // 计算卷积权重元素的起始位置
float *b = net.workspace; // 存储输入图片重排后结果的位置
float *c = l.output + (i*l.groups + j)*n*m; // 计算卷积输出特征图的存储位置
float *im = net.input + (i*l.groups + j)*l.c/l.groups*l.h*l.w; // 计算输入图片的起始存储位置
if (l.size == 1) { // 如果卷积核尺寸为1*1,是不需要进行重排的
b = im;
} else {
im2col_cpu(im, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, b); // 重排后结果保存在b中
}
// 此处在im2col_cpu的操作基础上,利用矩阵乘法c=alpha*a*b + beta*c
// 0,0表示不对输入a,b进行转置 a: [m, k], b: [k, n], c: [m, n]
// m是输入a,c的行数,具体含义为卷积模板个数l.n
// n是输入b,c的列数,具体含义为每个输出特征图的元素个数(out_h*out_w)
// k是输入a的列数也是b的行数,具体含义为卷积核元素个数乘以输入图像的通道数(l.size*l.size*l.c)
// a, b, c即为三个参与运算的矩阵(用一位数组存储),alpha=beta=1为常系数;
// a为所有卷积核集合,元素个数为l.n*l.c*l.size*l.size, 按行存储,共有l*n行, l.c*l.size*l.size列,
// 即a中每行代表一个可以作用在l.c通道上的卷积核,
// b为一张输入图像经过im2col_cpu重排后的图像数据(共有l.c*l.size*l.size行, l.out_w*l.out_h列)
// c为gemm()计算得到的值,包含一张输入图片得到的所有输出特征图(每个卷积核得到一张特征图),c中一行代表一张特征图
// 各特征图铺开成一行后,再将所有特征图拼成一大行,存储在c中,因此c可视为l.n行,l.out*l.out列。
gemm(0,0,m,n,k,1,a,k,b,n,1,c,n);
}
}
// 如需要BN
if(l.batch_normalize){
forward_batchnorm_layer(l, net);
} else { // 如果有BN,就不需要偏置,功能重复
add_bias(l.output, l.biases, l.batch, l.n, l.out_h*l.out_w);
}
// 激活
activate_array(l.output, l.outputs*l.batch, l.activation);
if(l.binary || l.xnor) swap_binary(&l); // 这里不作考虑
}
/**
* 卷积反向传播函数
* 主要流程:1)调用gradient_array()计算当前层l所有输出元素关于加权输入的导数值(也即激活函数关于输入的导数值),
* 并乘上上一次调用backward_convolutional_layer()还没计算完的l.delta,得到当前层最终的误差项;
* 2)如果网络进行批归一化操作,则进入BN的反向过程,在之前系列中已经详细解释了;
* 3) 如果网络没有进行批归一化操作,则直接调用 backward_bias() 计算当前层所有卷积核的偏置更新值;
* 4)依次调用im2col_cpu(), gemm_nt()函数计算当前层权重系数更新值;
* 5)如果上一层的delta已经动态分配了内存,则依次调用gemm_tn(), col2im_cpu()计算上一层的误差项(并未完成所有计算,还差一个步骤);
* 强调:每次调用本函数会计算完成当前层的误差项计算,同时计算当前层的偏置、权重更新值,除此之外,还会计算上一层的误差项,但是需要注意的是,
* 并没有完全计算完,还差一步:乘上激活函数对加权输入的导数值。这一步在下一次调用本函数时完成。
* @param l 当前卷积层
* @param net 整个网络
*/
void backward_convolutional_layer(convolutional_layer l, network net)
{
int i, j;
int m = l.n/l.groups; //卷积核个数
// 每一个卷积核训练权重个数(包括l.c (l.c为该层网络的输入图片的通道数),比如卷积核尺寸为3*3,
// 输入图片有3个通道,因为要同时作用于输入的3个通道上,所以实际上这个卷积核是立体的,共有3*3*3=27个元素,这些元素都是要训练的参数)
int n = l.size*l.size*l.c/l.groups;
int k = l.out_w*l.out_h; // 每张输出特征图的元素个数: out_w, out_h是输出特征图的宽高。
/*
void gradient_array(const float *x, const int n, const ACTIVATION a, float *delta)
{
int i;
for(i = 0; i < n; ++i){
delta[i] *= gradient(x[i], a);
}
}
*/
// 计算当前层激活函数对加权输入的导数并乘以l.delta相应的元素,从而完成当前层的误差项l.deta。
// l.output存储了该层网络的所有输出:该层网络接收一个batch的输入图片,其中每张图片经卷积处理后得到的特征图尺寸为:l.out_w, l.out_h
// 该层卷积网络共有l.n个卷积核,因此一张输入图片共输出l.n张宽高为l.out_w, l.out_h的特征图(l.outputs为一张图片所有输出特征图的总元素个数)
// 所以所有输入图片也即 l.output中的总元素个数为:l.n * l.out_w * l.out_h * l.batch;
// l.delta是一个一维数组,长度为l.batch * l.outputs (其中l.outputs = l.out_h * l.out_w * l.out_c),在make_convolutional_layer()动态分配内存;
// 再次强调:gradient_array()不单单是完成激活函数对输入的求导运算,还完成计算当前层误差项的最后一步:l.delta中每个元素乘以激活函数对输入的导数。
// 每次调用backward_convolution_layer时,都会完成当前层误差层的计算,同时会计算上一层的误差项,单对于上一层,其误差项并没有完全计算完成,还差一步,
// 需要等到下一次调用backward_convolution_layer时来完成。
// l.batch*l.outputs
gradient_array(l.output, l.outputs*l.batch, l.activation, l.delta);
if(l.batch_normalize){ // 使用BN的话,反向传播到BN
backward_batchnorm_layer(l, net);
} else {
// 计算偏置的更新值
// 每个卷积核都有一个偏置,偏置的更新值也即误差函数对偏置的导数,这个导数的计算很简单,实际所有的导数已经求完了,都存储在l.delta中,
// 接下来只需要把l.delta中对用同一个卷积核的项加起来就可以了(卷积核在图像上逐行逐列移动做卷积,每个位置都有一个输出,共有l.out_w*l_out_h个)
// 这些输出都与同一个偏置关联,因此将l.delta中对应同一个卷积核的项加起来即得到误差函数对这个偏置的导数
backward_bias(l.bias_updates, l.delta, l.batch, l.n, k);
}
// 遍历batch中每张图片,对于l.delta来说,每张图片是分开存的,因此其维度会达到: l.batch * l.n * l.out_h * l.out_w
// 对于l.weights, l.weight_updates以及上面提到的l.bias, l.bias_updates, 是将所有图片对应元素叠加起来
// (循环的过程就是叠加的过程,注意gemm()这系列函数含有叠加效果,不是覆盖输入C的值, 而是叠加到C之上)
// 因此, l.weight与l.weight_updates维度为 l.n * l.size * l.size, l.bias 与 l.bias_updates的维度为l.n 都与l.batch无关
for(i = 0; i < l.batch; ++i){
for(j = 0; j < l.groups; ++j){
float *a = l.delta + (i*l.groups + j)*m*k;
// net.workspace的元素个数为所有层中最大的l.workspace_size(在make_convolutional_layer() 计算得到workspace_size大小,
// 在parse_network_cfg()中动态分配内存,此值对应未使用GPU时的情况),
// net.workspace充当一个临时工作空间的作用,存储临时所需要的计算参数,比如每层单张图片重排后的结果(这些参数马上会参与卷积运算),
// 一旦用完,就会被马上更新(因此该遍历的情况更新频率比较大)
float *b = net.workspace;
float *c = l.weight_updates + j*l.nweights/l.groups;
// 在进入本函数之前,在backward_network()函数中,已经将net.input赋值为prev.output,也即若当前层为第l层,
// net.input此时已经是第l-1层的输出
// 下面两步: im2col_cpu()与gemm()是为了计算当前层的权重更新值(其实也就是误差函数对当前层权重的导数)
// 将多通道二维图像net.input变成按一定存储规则排列的数据b,以方便,高效的进行矩阵计算,详细可查看gemm的源码解析
// im2col_cpu 每次仅处理net.input (包含整个batch)中的一张输入图片(对于第一层,则就是读入的图片,对于之后的层,这些图片都是上一层的输出,
// 通道数等于上一层卷积核的个数).
// 最终重排的b为 l.c * l.size * l.size行, l.out_h * l.out_w列
// 你会发现在前向forward_convolutional_layer() 函数中,也为每层的输入进行了重排,但是遗憾的是,并没有一个l.workspace把
// 每一层的重排结果保存下来,而是统一存储到net.workspace中, 并不断被擦除更新,拿为什么不保存呢?保存下来不是省掉一大笔额外重复
// 计算开销?
// 原因:1. net.workspace中只存储了一张输入图片的重排结果,所以重排下张图片时,马上就会被擦除, 当然你可能会去想,那为什么不用一个l.workspaces
// 将每层所有输入图片的结果保存呢?这引出第二个原因:
// 2. 计算成本降低了,但存储空间需要急剧增加,想想每一层都有l.batch张图, 且每张都是多通道的,重排后其元素个数还会增多,这个存储量太大.
// 如果一个batch有128张图,输入图片的尺寸为400*400, 3通道,网络有16层(假设每层输入输出尺寸以及通道数都一样), 那么单单为了存储这些重排结果.
// 就需要128*400*400*3*16*4/1024/1024 = 3.66G, 所以为了权衡.只能重复计算;
float *im = net.input + (i*l.groups + j)*l.c/l.groups*l.h*l.w;
float *imd = net.delta + (i*l.groups + j)*l.c/l.groups*l.h*l.w; //保存反传回来的梯度
if(l.size == 1){
b = im;
} else {
im2col_cpu(im, l.c/l.groups, l.h, l.w,
l.size, l.stride, l.pad, b);
}
// 计算卷积层的权重更新值
// 所谓权重更新就是 weight = weight - alpha * weight_update中的weight_update
// 权重更新值等于当前层误差项中每个元素乘以相应的像素值,因为一个权重跟当前层多个输出关联(权值共享,即卷积核在图像中跨步移动做卷积,每个位置卷积得到的值
// 都与该权值相关), 所以对每一权重更新值来说,需要在l.delta中找出所有与之相关的误差项,乘以相应的像素值,再求和,具体的实现的方式im2col_cpu()与gemm_nt()完成
// 当前全连接的误差项乘以当前层的输入即可得到当前卷积层的权重更新值
// 此处在im2col_cpu操作基础上,利用矩阵乘法 c = alpha*a*b + beta*c完成对图像卷积的操作;
// 0表示不对输入a进行转置, 1表示对输入b进行转置;
// m是输入a,c的行数,具体含义为卷积核的个数(l.n);
// n是输入b和c的列数,具体含义为每个卷积核元素个数乘以输入图像的通道数(l.size*l.size*l.c)
// k是输入a的列数也是b的行数, 具体含义为每个输出特征图的元素个数 (l.out_h * l.out_w)
// a,b,c即为三个参与运算的矩阵(用一维数据存储), alpha=beta=1为常系数
// a为l.delta的一大行, l.delta为本层所有输出(包含整个batch中每张图片的所有特征图)关于加权输入的导数(即激活函数的导数值)集合;
// 元素的个数为 l.batch * l.out_h * l.out_w * l.out_c (l.out_c = l.n), 按行存储, 共有l.batch行, l.out_h * l.out_w * l.out_c列
// 即l.delta中每行包含一张图的所有输出图,故这么一大行,又可以视作有 l.out_c(l.out_c = l.n)个小行, l.out_h * l.out_w小列,而一次循环就是处理
// l.delta的一大行, 故可以视a作为l.out_c行, l.out_h*l.out_w列的矩阵;
// b 为单张输入图像经过im2col_cpu重排后的图像;
// c 为输出,按存储,可视作有l.n行, l.c*size*size列(l.c是输入图像的通道数,l.n是卷积核个数)
// 即c就是所谓的误差项(输出关于加权输入的导数)或者误差项 (一个卷积核有l.c*l.size*l.size个权重,共有l.n个核)
// 由上可知:
// a: (l.out_c) * (l.out_h * l.out_w)
// b: (l.c * l.size * l.size) * (l.out_h * l.out_w)
// c: (l.n) * (l.c * l.size * l.size) (注意:l.n = l.out_c)
// 故要进行a * b + c计算,必须对b进行转置(否则行列不匹配), 因此调用gemm_nt()函数;
gemm(0,1,m,n,k,1,a,k,b,k,1,c,n);
// 由当前卷积层计算上一层的误差项
// 接下来,用当前层的误差项目 l.delta 以及权重 l.weights (还未更新)来获取上一层网络的误差项,
// BP算法的主要流程就是依靠这种层与层之间的误差项反向传播关系来实现.
// 在network.c的backward_network()中,会从最后一层网络往前遍历循环到第一层,而每次开始遍历某一层网络之前,
// 都会更新net.input为这一层网络的输出,即prev.output. 同时更新net.delta为prev.delta, 因此, 这里的net.delta是当前层前一层的误差项.
// 再强调一次: 下面得到的上一层的误差项并不完整,完整的误差项是损失函数对上一层的加权输入的导数.
// 而这里得到的误差项是损失函数对以上层输出值(激活函数的输出值)的导数,还差乘以一个输出值也即激活函数对加权输入的导数[一般反向的传播的开始计算]
if (net.delta) {
// 当前层还未更新权重
a = l.weights + j*l.nweights/l.groups;
// 每次循环仅处理一张输入图,注意移位(l.delta的维度 l.batch * l.out_c * l.out_h * l.out_w) [l.out_c = l.n]
b = l.delta + (i*l.groups + j)*m*k;
// net.workspace和上面一行,还是一张输入图片的重排.不同的是, 此处我们只需要这个容器,而里面存储的值我们并不需要,
// 在后面的处理过程中, 会被其中存储的值一一覆盖掉(尺寸维持不变,还是 (l.c *l.size *l.size) *(l.out_h * l.out_w))
c = net.workspace;
if (l.size == 1) {
c = imd; // float *imd = net.delta + (i*l.groups + j)*l.c/l.groups*l.h*l.w;
}
// 相比上一个gemm, 此处的a对应上一个c,b对应上一个的b, 即此处a,b,c的行列分别为:
// a: (l.n) * (l.c * l.size * l.size), 表示当前层所有权重系数
// b: (l.out_c) * (l.out_h * l.out_w) [注意: l.out_c = l.n] 表示当前层的误差项
// c: (l.c * l.size * l.size) * (l.out_h * l.out_w), 表示上一层的误差项(其元素个数等于上一层网络单张输入图片的所有输出元素个数)
// 此时要完成 a*b + c计算,必须对a进行转置(否则行列不匹配), 因此调用gemm_tn()函数.
// 此操作含义: 用当前层还未更新的权重值对误差项做卷积,得到包含上一层所有误差项信息的矩阵,但这不是上一层最终的误差项,
// 因为此时的c, 也即net.workspace的尺寸为(l.c * l.size * l.size) * (l.out_h * l.out_w), 明显不是上一层的输出尺寸(l.c * l.w * l.h)
// 接下来还需要使用调用col2im_cpu()函数将其恢复至l.c*l.w*l.h(可视为l.c行,l.w*l.h列), 这才是上一层的误差项(实际上还差一个环节,这个环节需要
// 等到下一次调用backward_convolutional_layer()才完成: 将net.delta中每个元素乘以家伙函数对加权输入的导数值).
// 完成gmm这一步, 如col2im_cpu()中注释,是考虑了多个卷积核导致的一对多关系(上一层的一个输出元素会流入到下一层多个输出元素中),
// 接下来调用col2im_cpu()则是考虑卷积核重叠(步长较小) 导致一对多的关系.
gemm(1,0,n,k,m,1,a,n,b,k,0,c,k);
if (l.size != 1) { // 卷积尺寸不为1
col2im_cpu(net.workspace, l.c/l.groups, l.h, l.w, l.size, l.stride, l.pad, imd);
}
}
}
}
}
typedef struct{
int batch;
float learning_rate;
float momentum;
float decay;
int adam;
float B1;
float B2;
float eps;
int t;
} update_args;
/**
* 卷积层权重更新函数
* @param l 当前卷积层
* @param a 训练超参数结构体
*/
void update_convolutional_layer(convolutional_layer l, update_args a)
{
float learning_rate = a.learning_rate*l.learning_rate_scale;
float momentum = a.momentum;
float decay = a.decay;
int batch = a.batch;
//l.biases += learning_rate/batch * l.bias_updates 更新偏置,这里学习率要除以batch,整个batch的梯度平均值
axpy_cpu(l.n, learning_rate/batch, l.bias_updates, 1, l.biases, 1);
// l.bias_updates *= momentum; 计算下次梯度需要偏置的动量
scal_cpu(l.n, momentum, l.bias_updates, 1);
//
if(l.scales){
// l.scales += learning_rate/batch * l.scale_updates
axpy_cpu(l.n, learning_rate/batch, l.scale_updates, 1, l.scales, 1);
// l.scales_updates *= momentum;
scal_cpu(l.n, momentum, l.scale_updates, 1);
}
// l.weight_updates += -decay*batch * l.weights 计算权重衰减
axpy_cpu(l.nweights, -decay*batch, l.weights, 1, l.weight_updates, 1);
// l.weights += learning_rate/batch * l.weight_updates 更新权重
axpy_cpu(l.nweights, learning_rate/batch, l.weight_updates, 1, l.weights, 1);
// l.weight_updates *= momentum 计算下次梯度需要的权重的动量
scal_cpu(l.nweights, momentum, l.weight_updates, 1);
}
image get_convolutional_weight(convolutional_layer l, int i)
{
int h = l.size;
int w = l.size;
int c = l.c/l.groups;
return float_to_image(w,h,c,l.weights+i*h*w*c);
}
void rgbgr_weights(convolutional_layer l)
{
int i;
for(i = 0; i < l.n; ++i){
image im = get_convolutional_weight(l, i);
if (im.c == 3) {
rgbgr_image(im);
}
}
}
void rescale_weights(convolutional_layer l, float scale, float trans)
{
int i;
for(i = 0; i < l.n; ++i){
image im = get_convolutional_weight(l, i);
if (im.c == 3) {
scale_image(im, scale);
float sum = sum_array(im.data, im.w*im.h*im.c);
l.biases[i] += sum*trans;
}
}
}
image *get_weights(convolutional_layer l)
{
image *weights = calloc(l.n, sizeof(image));
int i;
for(i = 0; i < l.n; ++i){
weights[i] = copy_image(get_convolutional_weight(l, i));
normalize_image(weights[i]);
/*
char buff[256];
sprintf(buff, "filter%d", i);
save_image(weights[i], buff);
*/
}
//error("hey");
return weights;
}
image *visualize_convolutional_layer(convolutional_layer l, char *window, image *prev_weights)
{
image *single_weights = get_weights(l);
show_images(single_weights, l.n, window);
image delta = get_convolutional_image(l);
image dc = collapse_image_layers(delta, 1);
char buff[256];
sprintf(buff, "%s: Output", window);
//show_image(dc, buff);
//save_image(dc, buff);
free_image(dc);
return single_weights;
}
完,