如何为物联网的时间序列异常检测建模
异常检测涵盖了大量数据分析用例。 但是,这里的异常检测专门指的是意外事件的检测,例如心脏发作,机械故障,黑客攻击或欺诈交易。
事件的意外特征意味着数据集中没有此类示例。 分类解决方案通常需要所有涉及的类的一组示例。 那么,在没有可用示例的情况下,我们该如何进行? 这需要在视角上稍作更改。
在这种情况下,我们只能针对非故障数据训练机器学习模型; 也就是说,根据描述系统在正常条件下运行的数据。 输入数据是异常还是仅常规操作的评估只能在进行预测后的部署中执行。 这个想法是,根据正常数据训练的模型只能预测下一个正常样本数据。 但是,如果系统不再在正常条件下工作,则输入数据将无法描述正确的工作系统,并且模型预测将偏离实际情况。 真实样本和预测样本之间的误差可以告诉我们一些有关底层系统状况的信息。
在物联网(IoT)数据中,信号时间序列由战略性地位于机械设备或组件上或周围的传感器产生。 时间序列是变量随时间变化的值序列。 在这种情况下,变量描述了设备的机械性能,并通过一个或多个传感器进行测量。 通常,机械设备运行正常。 结果,我们有大量的样品在正常条件下工作,而设备故障的实例几乎为零。 特别是如果该设备在机械链中起着至关重要的作用,则通常在任何故障发生并损害整个机械之前就将其淘汰。
因此,我们只能在描述系统按预期工作的多个时间序列上训练机器学习模型。 当系统正常工作时,该模型将能够预测时间序列中的下一个样本,因为这是如何训练的。 然后,我们计算预测的样本与实际样本之间的距离,然后从中得出关于一切是否按预期工作或是否有任何令人担忧的原因的结论。
我们将使用GUI驱动的开源Knime Analytics Platform构建,训练和部署模型。 Knime允许您通过以图形方式从处理元素(称为节点)组装处理管道(称为工作流)来构建模型。
 尼米
尼米
图1.时间序列是工作系统产生的信号。 通常,系统在正常条件下运行,并且我们的信号正常。 有时,会发生一些新情况,并且我们的信号异常。 如果根本发生异常,则很少见。 因此,机器学习模型只能在正常样本上训练。 计算出的实际信号与预测信号之间的距离将用于触发异常警报。
数据集:来自28个传感器的28个时间序列
在从2007年1月1日到2009年4月20日的时间范围内,我们使用了28个传感器的矩阵,重点关注机械转子的八个部分(请参见下表)。总共有28个时间序列,从28个传感器连接到机械转子的八个不同部分。
在应用快速傅立叶变换(FFT)之后,信号到达我们,并分布在28个文件中,格式为:
[日期,时间,FFT频率,FFT幅度]
| A1 | 输入轴垂直 |
| A2 | 第三轴水平上轴承 |
| A3 | 第三轴水平下部轴承 |
| A4 | 内齿轮275度 |
| A5 | 内齿轮190,5度 |
| A6 | 输入轴轴承150 |
| A7 | 输入轴轴承151 |
| M1 | 扭矩KnM |
频谱幅度已跨频段,时间和传感器通道汇总。 这产生了313个时间序列,描述了在不同位置和频段的系统演进。
整个数据集仅显示了2008年7月21日发生的一次故障。该故障仅在某些传感器中可见,并且主要在某些频带中可见。 故障后,更换了转子,此后记录了更清晰的信号。
 尼米
尼米
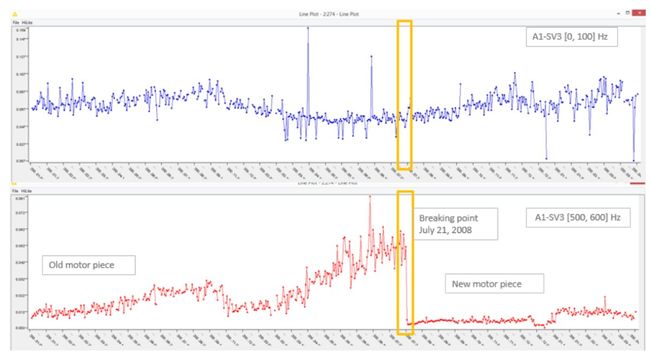
图3.时间序列A1-SV3 [0,100]和A1-SV3 [500,600]随时间的演变。 在较高的频带[500,600] Hz而不是较低的频带[0,100]中,2008年7月21日的转子故障事件很容易看到。 数据集中有313个这样的时间序列,涉及原始28个时间序列的不同频段。
训练机器学习模型
在2007年1月至2007年8月这部分时间序列中,当转子仍能正常运行时,对机器学习模型进行了训练。
在每个时间序列的10个过去样本上训练一个自回归(AR)模型,从而得到313个AR模型; 也就是说,每个时间序列中的每个模型都有一个模型。
为了为每个时间序列建立一个模型,我们需要循环时间序列; 也就是说,在数据集的列上。 因此,训练AR模型的工作流程以循环周期为中心。 在循环中,在每个列上,对于每个值,我们建立一个过去的十个样本的过去,估算缺失值,对过去的值训练线性回归模型以预测当前值,最后计算误差统计值(均值和标准偏差)。 然后保存模型和错误统计信息,并将其用于部署中。
 尼米
尼米
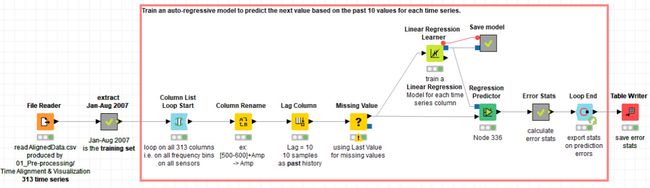
图4.培训工作流02_Time_Series_AR_Training。 此工作流在10个过去的样本上训练自回归模型,以预测每个输入时间序列的当前样本。 请注意,训练集仅包含系统正常工作的时间序列。 然后,该模型将仅预测正确运行的系统的时间序列的未来样本。
模型部署工作流程
与经典的预测模型应用程序相比,此处部署工作流的目标更具创造力。 同样,我们将使用Knime的图形工作流程设计器创建此工作流程。
报警等级1
对于每个时间序列,我们基于过去的10个值预测下一个值,然后测量预测值与当前实际值之间的距离,最后将此距离与训练过程中生成的误差统计数据进行比较。 如果误差距离大于(或小于)误差平均值+(-)2 *标准偏差,则会生成与距离值一样大的警报尖峰; 否则将警报信号设置为0。此警报信号为“警报级别1”。
整个预测,误差距离计算,与训练误差的均值和标准偏差的比较以及最终警报级别1的计算在部署工作流的列循环内执行。 总共计算出313个警报级别1时间序列,即每个时间序列一个。 这发生在工作流图的“ Alarm Level 1节点中(请参见图5)。
警报等级2
警报级别1时间序列是一系列或多或少的高尖峰。 单个峰值本身并没有多大意义。 这可能是由于电力波动,温度快速变化或某些此类临时原因引起的。 另一方面,一系列峰值可能意味着基础系统发生了更为严重和永久的变化。 因此,在所有313列上,将创建警报级别2系列作为警报级别1系列的前21个样本的移动平均值。 这些构成了“警报级别2”时间序列,并在“ Alarm Level 2元节点中进行了计算(图5)。 (Knime中的元节点是包含子工作流的节点。)
因为我们需要该移动平均值的21个每日值,所以在部署工作流开始时,我们选择要调查的日期,然后在所有时间序列中至少获取21个过去的值。 由于缺少许多值,为确保我们有足够的样本作为移动平均线,我们夸大了过去两个月的窗口。
此时,所有警报级别2的值将在同一日期的各列中求和。 如果此合计值超过给定的阈值(0.01),则会认真对待警报, Trigger Checkup if level 2 alarm = 1 ,则在元节点Trigger Checkup if level 2 alarm = 1触发一个检查过程(图5)。
 尼米
尼米
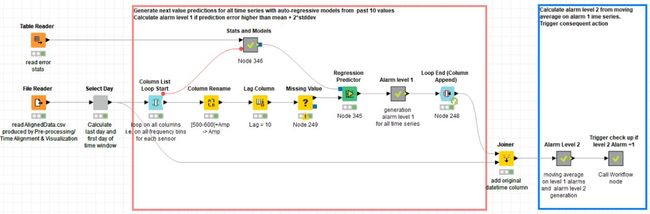
图5.部署工作流03a_Time_Series_AR_Deployment。 在这里,我们阅读了在训练工作流程中训练并保存的模型; 我们将它们应用于新的时间窗口(至少两个月之久)中的数据; 我们计算预测样本与原始样本之间的距离; 我们会生成两个级别的警报。 如果警报级别2处于活动状态,则触发检查过程。
警报触发
该元节点中的触发代理是CASE Switch Data (Start)节点(请参见图6)。 仅当“警报级别2”处于活动状态并通过节点“ Call Workflow (Table Based)启动外部工作流时,才启用第二个端口。 该节点在其配置窗口中设置为启动外部Knime工作流程Send_Email_to start_checkup。
 尼米
尼米
图6.元节点的内容Trigger checkup if level 2 Alarm =1 。 触发节点“ Call Workflow (Table Based) ”调用并执行一个名为Send_Email_to_start_checkup的外部工作流,它的作用正是如此:它发送电子邮件以触发检查过程。
工作流“ Send_Email_to start_checkup”只有一个中央节点,即“ Send Email节点。 顾名思义,“ Send Email节点使用SMTP主机上的指定帐户及其凭据发送电子邮件。
工作流中的另一个节点是“ Container Input (Variable)节点。 尽管此节点在功能上并不重要,但需要将数据从调用传递到被调用工作流。 实际上,“呼叫工作流(基于表)”节点将在其输入端口处可用的所有流变量传递给被叫工作流的“容器输入(变量)”节点(如果有)。 总之,容器输入(变量)工作流是将调用者节点上可用的流变量传输到被调用工作流中的桥梁。
 尼米
尼米
图7.工作流Send_Email_to_start_checkup发送一封电子邮件以触发检查过程。 注意,“ Container Input (Variable)节点将流变量从调用者工作流传递到被调用工作流。
测试结果
只需修改部署工作流程,我们就有机会在多个数据点上测试此策略,并观察Alarm Level 2时间序列随时间的变化。
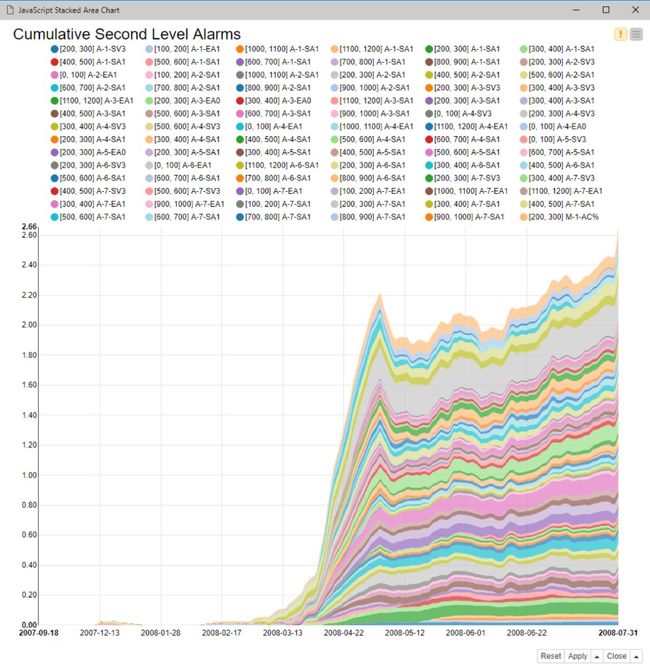
在修改后的版本中,我们从训练集部分(即从2007年9月到2008年7月)之后读取所有数据。在堆叠区域图中,每个传感器的每个频段的警报级别2时间序列都可视化。 正如您在下面的图8中看到的那样,警报级别2的值会在2008年3月开始的所有频段和所有传感器上立即上升。 但是,系统的变化在2008年5月开始变得明显,尤其是在某些传感器的某些频带中(请参阅[200-300] A7-SA1时间序列)。
考虑到转子在2008年7月22日发生故障,该数据将提供数周的预警。
更多详细信息,请参见Knime白皮书“ 预测性维护中的异常检测 ”。
 尼米
尼米
图8.对部署工作流进行了略微修改,以在剩余时间窗口中运行测试,直到分手为止(工作流03b_Time_Series_AR_Testing)。 结果是一个堆积的面积图,堆积了2007年1月到2008年7月的所有“警报2级”信号。您可以看到该警报信号在2008年3月上升,在2008年5月明显可见。
罗萨丽娅Silipo是在主要数据科学家Knime 。 她是50多个技术出版物的作者,包括她的最新著作“实践数据科学:案例研究的集合” 。 她拥有生物工程博士学位,并且在为物联网,客户智能,金融行业和网络安全等广泛领域的公司从事数据科学项目上花费了25年。 在Twitter , LinkedIn和Knime博客上关注Rosaria。
From: https://www.infoworld.com/article/3386398/how-to-model-time-series-anomaly-detection-for-iot.html