闲谈IPv6-v4/v6协议转换报文的checksum无关性
在IPv6时代,是不是可以用本地链路质量信息编码源地址的主机标识符从而指导服务器端拥塞控制策略呢,是不是也可以把自己是谁编码进去呢?比如自己是Android,自己是一台PC,或者说自己是一双智能皮鞋?以此来指导数据发送端的定制化动作呢?
IPv6的地址空间足够大,且留下了可达64位的主机标识符可供任意发挥,如此长度的主机标识符可以藏匿很多信息啊!
可以先看一下我很久之前在2012年写的一篇文章:
IPv6的NAT原理以及MAP66: https://blog.csdn.net/dog250/article/details/7799398
很有意思。
这种 利用IPv6地址空间远大于IPv4地址空间的特性,在IPv4报文转换为IPv6报文实现IPv4和IPv6之间互访的时候,通过解一个一元一次方程来保证协议checksum无需重新计算 的技术,其实还有很多玩法。
关键不在于什么解一元一次方程,而是在于IPv6的地址空间比IPv4地址空间足够大,在IPv4地址嵌入到IPv6地址中后,剩余的空间仍然可以存储校验码矫正值。
之前说过,IPv4和IPv6之间存在联通的必要,因为要平滑过渡就必然需要某种兼容,那么这种联通就可以分为两类:
- 横向联通: IPv4海洋中,IPv6孤岛之间的互访,此时需要IPv4隧道,参见6to4以及ISATAP等。
- 纵向联通: IPv4直接访问IPv6资源或者反过来。此时就需要协议转换,协议转换必然涉及到checksum的重新计算问题。
以上纵向联通方面,有一个超猛支撑技术,那就是DNS64,但是这种DNS技术更加侧重于管理平面和配置技巧,不是我的菜,所以我也不想多聊,分享一篇文章:
支持IPv6 DNS64/NAT64 网络<- 网络概述: https://www.jianshu.com/p/37b8c006cd2d
为了防止链接失效,盗图一张,解释DNS64:
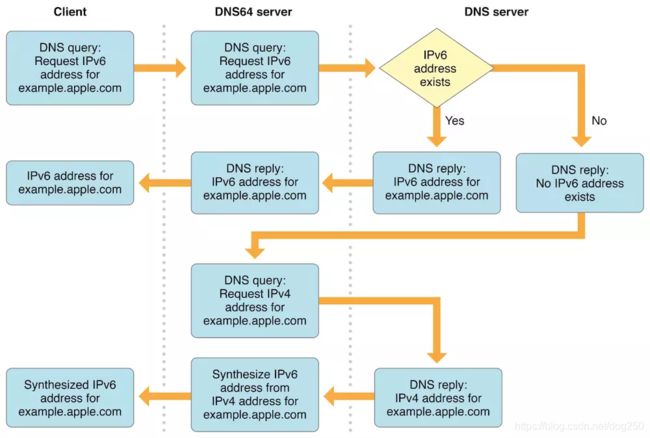
逻辑是比较简单的,但细节却足够繁琐,超级烦人。
本文不想谈DNS64,本文谈谈当IPv4报文转换为IPv6报文以及IPv6报文转换为IPv4报文时,上层协议checksum的计算问题。
上层协议在计算checksum时早就不需要IP层字段作为伪头参与了,但是不管TCP,UDP还是ICMP都是古老的协议,它们设计时就如此,没有办法,即便是IPv6还是要支持!
如果在协议转换的集中化节点去重新计算上层协议的checksum,那么资源的消耗将会是集中式的,为此,我们希望这些相关的计算尽量在边缘进行。此外,由于IPv6没有NAT或者至少说不提倡NAT,且地址足够长,没有哪台设备有足够的内存可以承受海量的连接状态跟踪的维护,所以需要某种stateless机制去维护conntrack!
就像TCP的Syncookie一样,我们 可以把conntrack信息存放在IPv6报文本身,因为它的地址空间足够大!
先看IPv4报文转换为IPv6报文时,如何保持上层checksum的不变性。
按照RFC6052的规范:
IPv6 Addressing of IPv4/IPv6 Translators: https://tools.ietf.org/html/rfc6052
IPv4地址会嵌入到IPv6地址空间的低位,具体就是下面这个规则了(参见2.2节):

注意后面的suffix,这些后缀空间是可以供我们自由发挥的。
除却96位的prefix实在是没有空间,其它的情况,至少可以在suffix低位取2个字节来存放checksum矫正值,计算这个checksum矫正值的问题可以描述为:
求解一个16bit的数字,请问它是多少时,当IPv4头按照RFC6052规范换成IPv6头时,TCP的checksum可以保持不变?
这不就是一个一元一次方程嘛…
给出一段代码:
#include 编译执行之:
[root@localhost DESTHDR]# ./a.out
IPv4报文数据检验码(可模拟包含伪头的TCP校验码):883E
begin IPv4 packet:
C0 A8 01 01 AC 10 02 02 31 32 33 34 35 36 37 38 39 30 61 62 63 64 3E 88
end IPv4 packet
校验码矫正值为:EEB0
当前IPv6报文的校验码(模拟在IPv4头转换为IPv6头之后,TCP协议的校验码不需要改变):883E
begin IPv6 packet:
20 01 00 01 02 03 04 05 C0 A8 01 01 00 00 B0 EE 20 01 05 04 03 02 01 00 AC 10 02 02 00 00 00 00 31 32 33 34 35 36 37 38 39 30 61 62 63 64 3E 88
end IPv6 packet
是不是很好玩?解一元一次方程也能解出实际用途来。
这可不是我自己说的,这可是RFC上说的,我只是照着试试做一下而已:
https://tools.ietf.org/html/rfc6052#section-4.1
现在反过来,IPv6报文如果转换为IPv4报文呢?
我们知道IPv4报文本身就有一个针对于IPv4协议头的校验码字段,如果数据始发于IPv6栈,那么当它需要转换为IPv4报文时,看样子这个IPv4的校验码计算是躲不过。
确实躲不过,但问题是在哪里进行这个计算。是在边缘节点还是在协议转换的节点来做呢?
我认为可以在边缘节点来做这个计算,然后把值藏匿于IPv6地址的 可以自由发挥的主机标识符里 就是了。
假设从IPv6栈发起一个去往IPv4地址10.18.19.2的数据报文,按照RFC6052的规范,这个IPv4地址肯定被编码进了IPv6栈的源地址的主机标识符里,那么是不是可以在数据始发的时候,就直接按照IPv4地址来计算TCP/UDP/ICMP的校验码呢,然后继续计算IPv4头的校验码,将IPv4头的校验码藏匿于源IPv6地址的suffix即可。
下面是一个例子:
- IPv6始发:2001: 1234: 1234: 1234:192.168.12.2::0/64到2001:4321:4321:4321:172.16.12.2::/64。
- 始发站直接按照192.168.12.2和172.16.12.2作为源和目标计算4层协议checksum保存在报文checksum字段。
- 始发站自行组装源和目标分别为192.168.12.2和172.16.12.2的IPv4报头,计算IPv4的checksum,保存于源IPv6地址2001: 1234: 1234: 1234:192.168.12.2::0/6的最后2个字节。
- 协议转换网关收到报文,按照嵌入的IPv4地址组装IPv4头,取出IPv6源地址的低2字节作为checksum装入IPv4头的checksum字段。
- IPv4报文发出到IPv4网络。
这便解放了协议转换网关的算力资源。
遗留的问题是,IPv6始发站如何识别一个报文是不是发往IPv4网络的,如何触发它去按照内嵌IPv4地址去生成伪头以及去计算一个IPv4头的校验码,这除了RFC6052之外,就看应用层的配置了,一个sockopt规则灌下去,非常容易做到!
既然IPv4和IPv6要互联互通,肯定是需要协议转换设备了,我本来就是一个设备迷而不是很care什么软件,所以,本文也是看了下面的新闻才有感而发的:
国内首个IPv6翻译设备认证出炉 北京英迪瑞讯IVI通过IPv6 认证: http://www.qianjia.com/zhike/201904/031822517170.html
我可能思想过于老套了,但我依然觉得设备才是重要的,软件灌入设备卖出去才有效。最关键的,我不喜欢互联网软件的原因是,互联网软件的代码一般都很low,毕竟服务器都在这些互联网公司自己的机房,出了问题远程登录即可排错,而设备是卖出去到客户那里的,排错成本高昂,所以必须精雕细琢不断测试。
清明时节,没有雨纷纷,所以皮鞋就不会湿,所以也就更加不会胖。