【数据结构】哈夫曼树编码/译码器
前言
参考博客:https://www.cnblogs.com/kangjianwei101/p/5242934.html
原博客是用C语言实现的,笔者改用java实现,原因主要有以下几点:
- 避免使用复杂的指针,减小错误发生的可能性
- 对字符串和数组的处理都自带了很多方法,不用在自己实现
- java的char类型用来存储Unicode类型的,字节长为2,而Unicode编码是包含中文的,所以可以直接用char类型存储单个汉字,而不用char[] 或者 String
运行截图
英文测试:
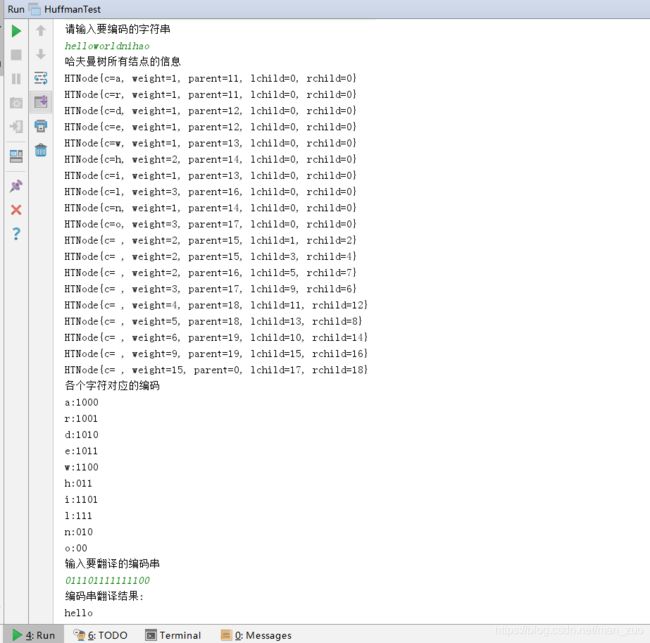
中文测试:
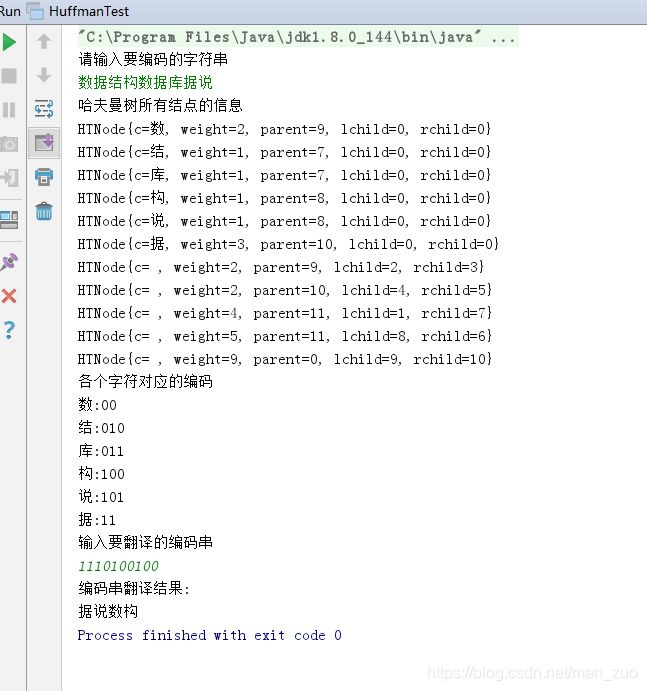
代码实现:
import java.util.*;
public class HuffmanTest {
public static void main(String[] args) {
Code code = new Code();
code.CreateNode();
code.CreateHuffmanTree();
code.HuffmanCoding();
code.show();
code.translate();
}
}
class HTNode{ //结点类
char c;
int weight;//权值
int parent,lchild,rchild;//父节点,左孩子,右孩子
@Override
public String toString() {
return "HTNode{" +
"c=" + c +
", weight=" + weight +
", parent=" + parent +
", lchild=" + lchild +
", rchild=" + rchild +
'}';
}
}
class HCNode{ //编码类
char c;//字符
char[] HCcode;//编码
}
class Code{
static HTNode[] nodes;//存放哈夫曼树的叶子结点
static HTNode[] huffmanTree;//存放哈夫曼树的所有结点
static HCNode[] huffmanCodes;//存放哈弗曼树每个叶子结点对应字符和编码信息
static int order_1,order_2;//在huffmanTree所有结点中依次选出权值最小的且没有编入树的两个结点的序号
public void CreateNode(){ //根据每个字母出现的次数确定该字母的权值
// java的char类型是用来储存Unicode编码字符的,Unicode字符集包含了汉字,所以char类型可以储存汉字,但在一些生僻字是不可以储存的
Scanner in = new Scanner(System.in);
System.out.println("请输入要编码的字符串");
String strings = in.nextLine();
Map<String, Integer> map = new HashMap<>();
for (int i = 0; i < strings.length(); i++) { //先用map计算每个字母出现次数
String s = strings.substring(i, i + 1);
if (map.containsKey(s)) {
Integer num = map.get(s);
map.put(s, num + 1);
} else {
map.put(s, 1);
}
}
nodes = new HTNode[map.size()+1];//把map的内容存到 nodes 数组,nodes[0]不用
int i=1;
Set<String> keys = map.keySet();
for (String key:keys){
HTNode node = new HTNode();
node.c = key.charAt(0);//提取 char 字符
node.weight = (int) map.get(key); //对应的权值
node.parent = node.lchild = node.rchild = 0;
nodes[i++]=node;
}
}
public void CreateHuffmanTree(){ //创建哈夫曼树
int n = nodes.length-1;//叶子结点数量
int m = 2*n-1;//哈夫曼树有效结点的数量
huffmanTree = new HTNode[m+1];
for (int i = 1;i<=m;i++){
if (i<=n){ //[1...n] 叶子结点
huffmanTree[i]=nodes[i];
}
else{ //[n+1...m] 双亲结点
HTNode node = new HTNode();
node.weight=0;
node.parent=0;
node.lchild=0;
node.rchild=0;
huffmanTree[i]=node;
}
}
for (int i=n+1;i<=m;i++){//建立哈夫曼树
Select_HT(i-1);//在huffmanTree所有结点中依次选出权值最小的且没有编入树的两个结点的序号
huffmanTree[order_1].parent=huffmanTree[order_2].parent =i;//把当前结点i作为选出的两个结点的双亲结点
huffmanTree[i].lchild=order_1;//order_1作为左孩子
huffmanTree[i].rchild = order_2;//order_2作为右孩子
huffmanTree[i].weight = huffmanTree[order_1].weight+huffmanTree[order_2].weight;//权值相加
}
}
public void Select_HT(int end){//在huffmanTree所有结点中依次选出权值最小的且没有编入树的两个结点的序号
int i,count;
int m=1,n=1;
for (i=1,count=1;i<=end;i++){//遍历找出前两个未编入树的结点
if (huffmanTree[i].parent==0){
if (count==1)
m=i;
if (count==2)
n=i;
count++;
}
if (count>2) break;
}
if (huffmanTree[m].weight>huffmanTree[n].weight){
//如果m结点的权重大于n结点的结点,交换m和n的值
// 使得m结点的权重小于等于n结点的权重
int tmp = n;
n = m;
m = tmp;
}
i =(m>n?m:n) +1;
while (i<end){ //继续遍历,寻找可能更小更靠前的结点
if (huffmanTree[i].parent==0){
if (huffmanTree[i].weight<huffmanTree[m].weight){ //如果比M结点的权重还要小
n=m;
m=i;
}else{
if (huffmanTree[i].weight>=huffmanTree[m].weight&huffmanTree[i].weight<huffmanTree[n].weight)
//如果i结点的权重大于m结点的权重并且小于n结点的权值
n=i;
}
}
i++;
}
order_1 = huffmanTree[m].weight<=huffmanTree[n].weight?m:n;
order_2 = huffmanTree[m].weight>huffmanTree[n].weight?m:n;
};
public void HuffmanCoding(){
//将哈夫曼树编码,左孩子为0 ,右孩子为1
int n = nodes.length-1; //哈夫曼树叶子结点个
int m = 2*n-1;//哈夫曼树结点个数
char[] code = new char[n+1];//存放单个结点哈夫曼编码
huffmanCodes = new HCNode[n+1];//存放哈夫曼树每个叶子结点的编码
int cdlen=0;//编码长度
int i,p=m;
Arrays.fill(code,'\0');
int mark[] = new int[m+1];//访问标记,0,1,2,分别表示访问过0,1,2次
Arrays.fill(mark,0);
while(p!=0){
if (mark[p]==0){//第一次访问这个结点
mark[p] =1;
if (huffmanTree[p].lchild!=0){//有左孩子,向左访问
p = huffmanTree[p].lchild;//向左走一步
code[cdlen] = '0';
cdlen++;
}
else{
if (huffmanTree[p].rchild==0){//如果没有右孩子,说明是叶子结点
HCNode hcNode = new HCNode();
hcNode.c = huffmanTree[p].c;
hcNode.HCcode = new char[cdlen+1];
hcNode.HCcode = Arrays.copyOf(code,cdlen+1);
huffmanCodes[p]=hcNode;
}
}
}
else {
if (mark[p]==1){//第二次访问次结点
mark[p]=2;
if (huffmanTree[p].rchild!=0){
p = huffmanTree[p].rchild;//访问下一个右孩子
code[cdlen]='1';
cdlen++;
}
}
else{ //mark[p]==2 第三次访问
p=huffmanTree[p].parent;//返回到父节点
cdlen--;//编码方式减一
if (cdlen>=0) code[cdlen]='\0';
}
}
}
}
public void translate(){ //将编码翻译成字符串
String s;
System.out.println("输入要翻译的编码串");
Scanner in = new Scanner(System.in);
s = in.next();
int n = nodes.length-1;
int p = 2*n-1;
System.out.println("编码串翻译结果:");
for (int i=0;i<s.length();i++){//0向左走,1 向右走
if (s.charAt(i)=='0'){
p=huffmanTree[p].lchild;
}
else if(s.charAt(i)=='1'){
p =huffmanTree[p].rchild;
}
if (huffmanTree[p].lchild==0&&huffmanTree[p].rchild==0){
//找到对应的叶子结点
System.out.print(huffmanTree[p].c);
p = 2*n-1;//p退回根节点
}
}
}
public void show(){ //打印哈夫曼树所有结点的信息和各个叶子结点的编码信息
System.out.println("哈夫曼树所有结点的信息");
for (int i=1;i<huffmanTree.length;i++){
System.out.println(huffmanTree[i]);
}
System.out.println("各个字符对应的编码");
for (int i=1;i<huffmanCodes.length;i++){
System.out.print(huffmanCodes[i].c+":");
for (char c:huffmanCodes[i].HCcode) {
System.out.print(c);
}
System.out.println();
}
}
}