Parquet文件格式介绍和读写流程
1.Parquet文件格式介绍
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,那么这里就总结下Parquet数据结构到底是什么样的
一个Parquet文件是由一个header以及一个或多个block块组成,以一个footer结尾。header中只包含一个4个字节的数字PAR1用来识别整个Parquet文件格式。文件中所有的metadata都存在于footer中。footer中的metadata包含了格式的版本信息,schema信息、key-value paris以及所有block中的metadata信息。footer中最后两个字段为一个以4个字节长度的footer的metadata,以及同header中包含的一样的PAR1。
读取一个Parquet文件时,需要完全读取Footer的meatadata,Parquet格式文件不需要读取sync markers这样的标记分割查找,因为所有block的边界都存储于footer的metadata中(因为metadata的写入是在所有blocks块写入完成之后的,所以吸入操作包含的所有block的位置信息都是存在于内存直到文件close)
这里注意,不像sequence files以及Avro数据格式文件的header以及sync markers是用来分割blocks。Parquet格式文件不需要sync markers,因此block的边界存储与footer的meatada中。
parquet文件格式如图1:
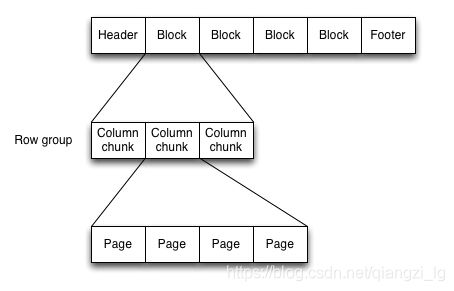
图1:parquet文件的格式结构
Parquet文件在磁盘上的分布情况如图2所示。所有的数据被水平切分成Row
group,一个Row group包含这个Row
group对应的区间内的所有列的column chunk。一个column
chunk负责存储某一列的数据,这些数据是这一列的Repetition levels, Definition levels和values(详见后文)。一个column
chunk是由Page组成的,Page是压缩和编码的单元,对数据模型来说是透明的。一个Parquet文件最后是Footer,存储了文件的元数据信息和统计信息。Row group是数据读写时候的缓存单元,所以推荐设置较大的Row
group从而带来较大的并行度,当然也需要较大的内存空间作为代价。一般情况下推荐配置一个Row group大小1G,一个HDFS块大小1G,一个HDFS文件只含有一个块
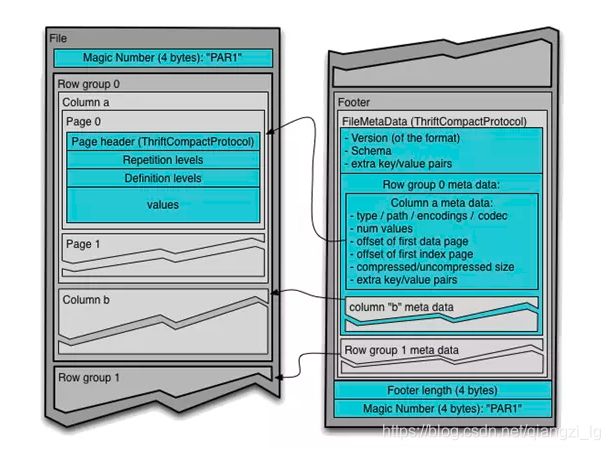
图2:文件在磁盘上的分布
2.Parquet的读写
parquet写的时候需要指定schema,读的时候会自动识别schema
每一个字段有三个属性:重复数、数据类型和字段名,重复数可以是以下三种:
required(出现1次)
repeated(出现0次或多次)
optional(出现0次或1次)
数据类型有:
INT64, INT32, BOOLEAN, BINARY(字符串), FLOAT, DOUBLE, INT96, FIXED_LEN_BYTE_ARRAY
例如:
private static String schemaStr = "message schema {" + "repeated int64 rowkey;"
+"repeated int64 family;"+ "repeated int64 colume;"+"repeated int64 value;}";
static MessageType schema = MessageTypeParser.parseMessageType(schemaStr);具体代码详见另一篇:https://blog.csdn.net/qiangzi_lg/article/details/86676538
文章摘自:https://www.jianshu.com/p/b823c727fe46和https://www.cnblogs.com/yangsy0915/p/5565309.html