机器学习复习6-优化器等
预备知识
一、正定和半正定矩阵


![]()
半正定矩阵包括了正定矩阵。

不定矩阵:特征值有正有负
二、牛顿法和拟牛顿法(二阶优化方法)
由于我主要是做NLP,机器学习方面基本功扎实后,更加偏机器学习的方法浅尝辄止即可,面试的时候知道有这些东西即可。这里只提一提。
牛顿法(Newton method)和拟牛顿法(quasi Newton method)是求解无约束最优化问题的常用方法,有收敛速度快的优点。牛顿法是迭代算法,每一步都需求解目标函数的海塞矩阵(Hessian Matrix),计算比较复杂。拟牛顿法通过正定矩阵近似海塞矩阵的逆矩阵或海塞矩阵,简化了这一计算过程。
1 牛顿法:

牛顿法的收敛条件为当梯度小于一定的大小时(接近0),便停止更新。 - 容易遇到鞍点问题
和梯度下降算法相比,相当于梯度下降算法的学习率被替换为了海塞矩阵的逆矩阵。->可以这样理解。
2 拟牛顿法:

拟牛顿法主要常见有DFP法(逼近Hession的逆)、BFGS(直接逼近Hession矩阵)、 L-BFGS(可以减少BFGS所需的存储空间)。均是用不同的构造方法来近似海塞矩阵或其逆。(知道其本质思想即可,方法名不用背)
3 牛顿法和梯度下降法:

根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
4 牛顿法和深度学习:
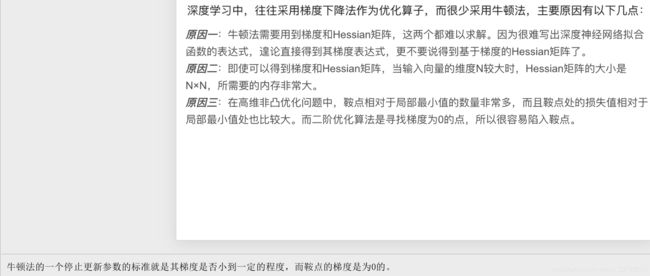
三、海塞矩阵


四、鞍点问题
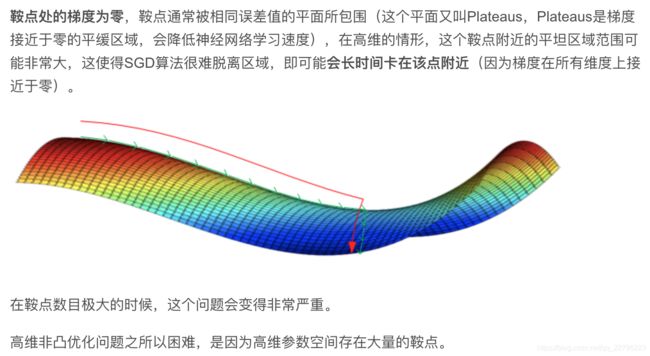
高维非凸优化问题之所以困难,是因为存在大量的鞍点而不是局部极值。
神经网络优化问题中的鞍点即一个维度向上倾斜且另一维度向下倾斜的点。
鞍点和局部极值的区别:
鞍点和局部极小值,
相同的是,在该点处的梯度都等于零,
不同在于在鞍点附近Hessian矩阵是不定的(特征值有正有负则属于不定矩阵,Hessian矩阵的不定矩阵说明该点不是极值点),而在局部极值附近的Hessian矩阵是正定的(Hessian矩阵的正定矩阵说明该点是极小值)。
在鞍点附近,基于梯度的优化算法(几乎目前所有的实际使用的优化算法都是基于梯度的)会遇到较为严重的问题。
五、最优化问题-如何逃离鞍点
深度学习中鞍点的大量存在,传统的牛顿法不适合,来寻优,因为牛顿法是通过直接寻找梯度为0的点,来寻优的,那么极有可能陷入鞍点。
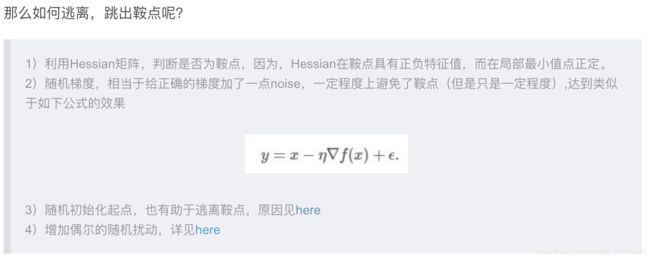
1)是判断是否为鞍点
2、3、4其实都是使用类似动量或者随机初始化的方法,来试图逃离鞍点。
各算法逃离鞍点的效果图:
https://img-blog.csdn.net/20170921144326084?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvQlZMMTAxMDExMTE=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast
正文

1. SGD系列
1.1 SGD(Stochastic gradient descent)

1.2 SGDM Momentum 动量
引入动量(Momentum)方法一方面是为了解决“峡谷”(局部最优解)和鞍点问题;一方面也可以用于SGD 加速,特别是针对高曲率、小幅但是方向一致的梯度。
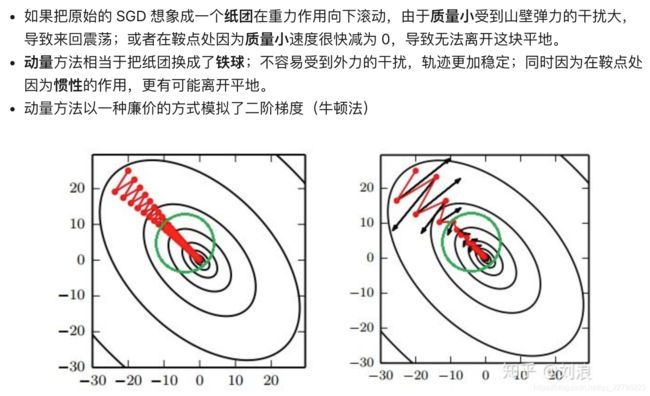

1.3 NAG 算法 Nesterov 动量(扩展)

带Nesterov的SGD,nesterov项在梯度更新时做一个校正,避免前进太快,参数操作多了所以同时提高灵敏度。
1.4 对比
批量梯度下降每次iteration使用全部的样本,模型能够对全部的样本进行学习,学习效果会更好;但其速度慢,不支持在线学习。
随机梯度下降算法,每次训练迭代利用单个样本,速度很快;但收敛性能不太好,在解空间的搜索比较盲目,并容易陷入鞍点;支持在线学习及其他,在实际中很常用。
Mini-batch梯度下降设置一个batch_size,每次iteration使用batch_size个样本进行学习。
2. 自适应系列
2.1 AdaGrad


每个参数的学习率会缩放各参数反比于其历史梯度平方值总和的平方根。全局学习率 ϵ 并没有更新,而是每次应用时被缩放。

2.2 RMSprop(Root Mean Squared prop)(2.3中也用到这个)
使用指数加权平均在一定窗口大小进行梯度累计
指数加权平均的本质见此链接:
https://zhuanlan.zhihu.com/p/29895933


2.3 Adadelta


![]()
上面的计算窗口内的累计梯度方法还是依赖全局学习率的。我们在上面学过了牛顿法和逆牛顿法,我们知道牛顿法是不需要学习率的,其需要海塞矩阵作为“学习率”,所以这里我们使用对角线近似海塞矩阵来充当“学习率”。
2.4 Adam


模型的梯度是一个随机变量,一阶矩表示梯度均值,二阶矩表示其方差,
一阶矩本质上是指数加权后的梯度来控制模型更新的方向,
二阶矩控制步长(学习率)。
用moveing average来对一阶矩和二阶矩进行估计
特点:
- 该算法结合了Momentum(First-order moment)和RMSProp(Second-order moment)两者的优点。
- Adam 算法通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。
- Adam算法是需要修正偏差的,偏差是由于初始化问题导致的,即下图描述:

- 计算效率很高,使用的内存相对较小。
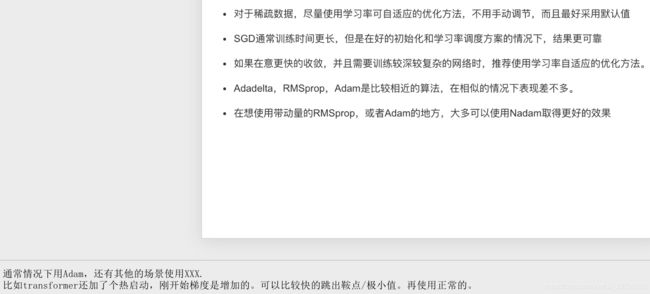
用了Adam还需要进行学习率衰减吗
可以使用,我一般是在模型分数不太变化的时候,再进行学习率衰减进一步调参。
各个方法手推总结


补充