SAT:State-Aware Tracker for Real-Time Video Object Segmentation 阅读
State-Aware Tracker for Real-Time Video Object Segmentation
https://arxiv.org/abs/2003.00482
针对video object segmentation (VOS)任务的跟踪器State-Aware Tracker (SAT)

简图示意:

粉色的联合分割网络得到目标mask,蓝色的状态评估器根据分割结果评估状态得分,然后产生两个反馈:剪切策略切换和全局特征的动态更新。

SAT分为三部分:联合分割网络,状态评估器和反馈。联合分割这块把显著性编码器(橙色),相似度编码器(黄色)和全局特征(绿色)融合在一起,然后对融合后的特征进行解码,预测mask。
>这部分是利用孪生的互相关网络产生目标的位置响应,再利用该位置响应指导一次编解码过程,得到目标的mask;将互相关结果的位置响应映射到跟踪图像上。个人觉得由于互相关运算之后得到的是相似度响应图,关于图像的位置信息已经损失了,直接在响应图的基础上重建出mask或者分割信息会导致较大的误差,SiamMask就是直接在分割和回归任务后增加mask的分割任务。所以作者增加了另外的分支,称为显著性编码分支,融合响应图之后再做解码;或者可以解释为将关于目标的位置信息调制到编解码器上,这里采用了显式的调制过程。
状态评估器根据预测结果计算状态分数来当前状态。根据状态估计的结果形成反馈,一是切换裁剪策略,二是构造一个全局特征表示,起到特征增强的作用。
Segmentation
相似度编码部分结构的实现参照以Alexnet为backbone的SiamFC++,显著性编码部分使用修改的ResNet-50。
显著性编码这一部分利用编码特征、相似度响应、全局特征进行元素加法之后再进行解码,可能是想让特征更为鲁邦吧。在特征融合之后,通过双线性插值对高层特征进行上采样,和显著性编码器对应的低层特征连接起来补足图像的位置信息(FPN)。
Estimation
作者在这部分说明了一下状态评估的作用,首先是目标的状态可以划分为正常和非正常状态,正常就不用说了,目标被截断会导致mask分散,即聚集度低。而遮挡和消失会导致置信度低;这些都属于非正常状态。所以作者设计了两个分数项 s c f s_{cf} scf和 s c c s_{cc} scc,分别表征mask预测的置信度和聚集度:
S c f = ∑ i , j P i , j ⋅ M i , j ∑ i , j M i , j \mathcal{S}_{\mathcal{cf}}=\frac{\sum_{i,j}\mathcal{P}_{\mathcal{i},\mathcal{j}}\cdot\mathcal{M}_{\mathcal{i},\mathcal{j}}}{\sum_{i,j}\mathcal{M}_{\mathcal{i},\mathcal{j}}} Scf=∑i,jMi,j∑i,jPi,j⋅Mi,j
P i , j \mathcal{P}_{\mathcal{i},\mathcal{j}} Pi,j代表mask中 ( i , j ) \ \left(\mathcal{i},\mathcal{j}\right) (i,j)位置处的预测得分, M \mathcal{M} M表示预测的二进制mask(前景为1,背景为0),即目标分割结果的置信度平均。
聚集度分数定义为最大连通区域面积与预测的二进制mask总面积之比:
S c c = max ( { ∣ R 1 c ∣ , ∣ R 2 c ∣ , ⋯ , ∣ R n c ∣ } ) ∑ 1 n ∣ R i c ∣ \mathcal{S}_{\mathcal{cc}}=\frac{\max{\left(\left\{\left|\mathcal{R}_1^\mathcal{c}\right|,\left|\mathcal{R}_2^\mathcal{c}\right|,\cdots,\left|\mathcal{R}_\mathcal{n}^\mathcal{c}\right|\right\}\right)}}{\sum_{1}^{n}\left|\mathcal{R}_\mathcal{i}^\mathcal{c}\right|} Scc=∑1n∣Ric∣max({∣R1c∣,∣R2c∣,⋯,∣Rnc∣})
然后最终的状态分数定义为
S s t a t e = s c f × s c c \mathcal{S}_{state}=s_{cf}×s_{cc} Sstate=scf×scc
如果 S s t a t e \mathcal{S}_{state} Sstate大于阈值 T \mathcal{T} T,就认为是正常状态,文章里设为0.85。
Feedback
Cropping Strategy Loop
搜索区域是当前目标bbox尺寸计算的,所以最终还是要预测目标的bbox;这里有两种策略,分别对应于正常和非正常状态:对于正常状态,选取mask的最大连通区域的最小外接矩形作为目标的box,最大连通区域就是为了避免FP预测的干扰。对于非正常状态,就用SiamFC++本来的head,也就是最大值响应加目标中心到边框上下左右的距离预测;还增加了位置、尺度、比例的平滑。

上图对这种切换机制进行了说明:跟踪器在mask(白色)和回归框(彩色)之间切换。 第一列中回归框失效(无法区分两个实例),状态评估器就选择了mask框。第二列中对象被截断或部分遮挡,回归框更为完整,分割没有办法跨越较大的像素区域。第三列是快速运动的情况,回归框可以检索目标对象。青色的虚线表示相似性编码器的搜索区域;红色的表示显著性编码器的输入区域,偏了自然没办法正常分割。
Global Modeling Loop :
这部分的目的是动态更新目标的全局特征,如下

使用预测的mask和图像点乘之后得到纯粹的目标图,送入resnet-50提取特征,然后逐渐地(step by step)将高层特征融合起来:
G t = ( 1 − S s t a t e ⋅ μ ) ⋅ G t − 1 + S s t a t e ⋅ μ ⋅ F t \mathcal{G}_\mathcal{t}= (1-S_{state}⋅μ)⋅\mathcal{G}_{t-1}+ S_{state}⋅μ⋅\mathcal{F}_{t} Gt=(1−Sstate⋅μ)⋅Gt−1+Sstate⋅μ⋅Ft
G \mathcal{G} G表示全局表征特征, F \mathcal{F} F表示去除背景的图像特征, μ \mu μ是超参数设置为0.5。如果目标被遮挡,消失或分割不正确,则提取的特征将对全局表示是有害的;因此使用 S s t a t e \mathcal{S}_{state} Sstate来减轻跟踪异常的不利影响。
Experiments
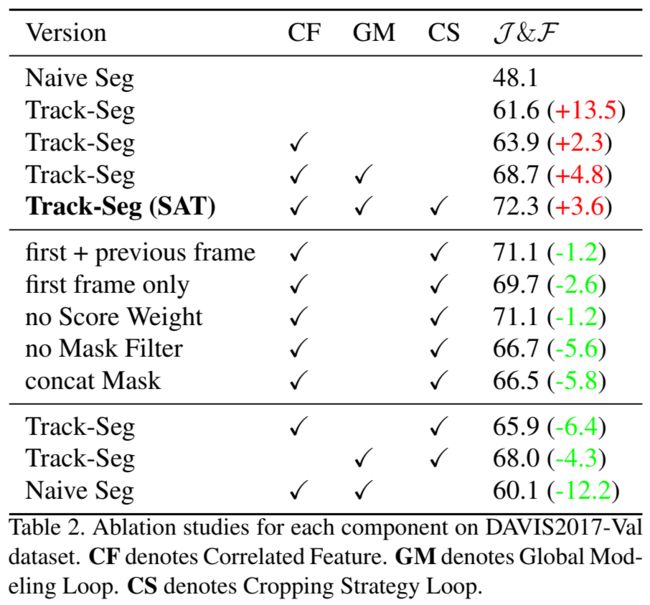
训练和SiamFC++的策略一样,但会freeze SiamFC++相关的模型参数,在全局特征表征的部分用GT代替模型预测的mask。 J \mathcal{J} J估计mask的IOU, F \mathcal{F} F描述轮廓的质量。 I D \mathcal{I}_D ID表示 J \mathcal{J} J随时间的性能衰减。
消融实验&横向对比: