Zeppelin结合Spark等各种Interpreter的使用
Zeppelin结合Spark等各种Interpreter的使用
Apache Zeppelin是基于Web的笔记本,支持SQL、Scala等数据驱动的交互式数据分析和协作文档。技术方面主要有Spark、SQL、Python。在部署方面支持单个用户也支持多用户。
Zeppelin Notebook可以满足数据摄取、数据发现、数据分析、数据可视化与协作。
多语言后端
Apace Zeppelin解析器概念允许将任何语言/数据处理后端插入Zeppelin,目前Apache Zeppelin迟滞许多解释器,入Apache Spark,python,JDBC,Markdown和shell。

安装Zeppelin请参考官网:http://zeppelin.apache.org/
原理简介
Interpreter
Zeppelin中最核心的概念是Interpreter,interpreter是一个插件允许用户使用一个指定的语言或数据处理器。每一个Interpreter都属于一个InterpreterGroup,同一个InterpreterGroup的Interpreters可以相互引用,例如SparkSqlInterpreter 可以引用 SparkInterpreter 以获取 SparkContext,因为他们属于同一个InterpreterGroup。当前已经实现的Interpreter有spark解释器,python解释器,SparkSQL解释器,JDBC,Markdown和shell等。下图是Zeppelin官网中介绍Interpreter的原理图。

Interpreter接口中最重要的方法是open,close,interpert三个方法,另外还有cancel,gerProgress,completion等方
| Open 是初始化部分,只会调用一次。 Close 是关闭释放资源的接口,只会调用一次。 Interpret 会运行一段代码并返回结果,同步执行方式。 Cancel可选的接口,用于结束interpret方法 getPregress 方法获取interpret的百分比进度 completion 基于游标位置获取结束列表,实现这个接口可以实现自动结束 |
操作
启动Zeppelin之后显示的页面是如下:

点击Login登入,输入账号和密码登入。
选择Notebook下拉箭头可以创建Notebook(Create new note)

可以加入很多解释器,加入配置可参考官网(http://zeppelin.apache.org/docs/0.8.0/quickstart/install.html):
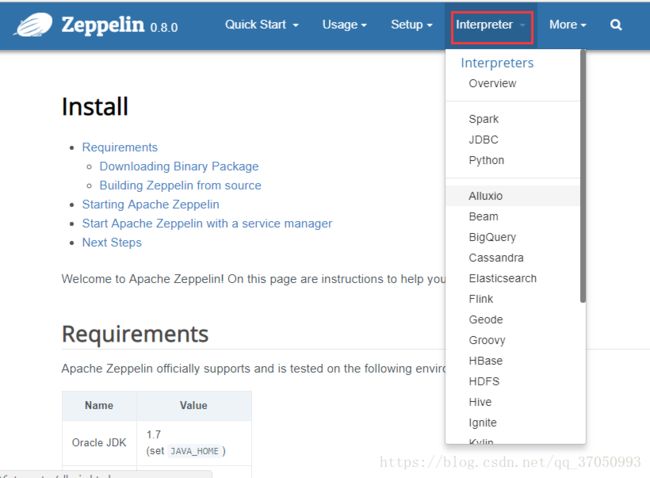
修改配置如下,点击登入用户下拉箭头,如果要添加新的Interpreter,可以选择+Create:

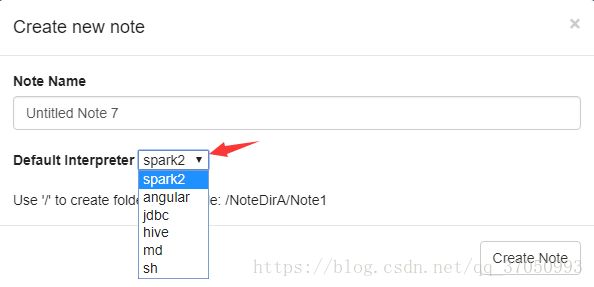
创建好了Notebook之后就可以开始写程序(http://zeppelin.apache.org/docs/0.8.0/quickstart/tutorial.html):
运行官方例子
官方提供了一个使用Spark执行引擎的例子,详细步骤如下
- Zeppelin启动之后,可以看到Zeppelin本身提供的Tutorial。点击“Create new note”创建新的笔记,名字叫Untitled Note 6
- 将测试文件放到hdfs集群上(/tmp目录下):bank.zip.
- 配置Spark的执行引擎,本例采用一个测试集群,修改的配置如下:
bank.zip压缩包主要包含三个文件:

将bank-full.csv文件上传到服务器下,然后再上传到hdfs上面;

| hdfs dfs -put bank-full.csv /tmp/ |
代码如下:
val bankText = sc.textFile("/tmp/bank-full.csv")
case class Bank(age:Integer, job:String, marital : String, education : String, balance : Integer)
// split each line, filter out header (starts with "age"), and map it into Bank case class
val bank = bankText.map(s=>s.split(";")).filter(s=>s(0)!="\"age\"").map(
s=>Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
)代码运行:

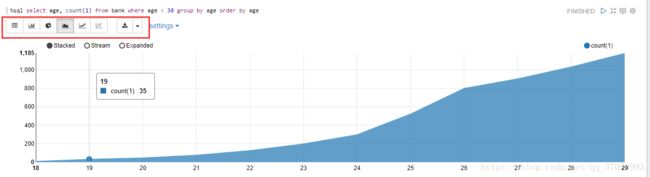
如果想使用图形化看到年龄分布,可以运行如下sql:
%sql select age, count(1) from bank where age < 30 group by age order by age可选择显示图形形状:
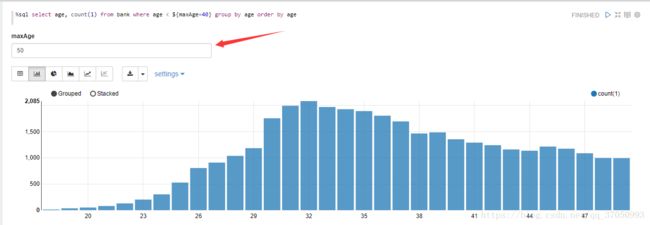
也可以使用${MaxAGE=40 }替换40来设置年龄条件的输入框。
如果希望看到有一定婚姻状况的年龄分布,并添加组合框来选择婚姻状况:
%sql select age, count(1) from bank where marital="${marital=single,single|divorced|married}" group by age order by age

对于每个脚本都有相关的设置:

通过上面的操作我们使用的聚合是count函数,我们可以通过setting来指定某个字段的聚合函数:
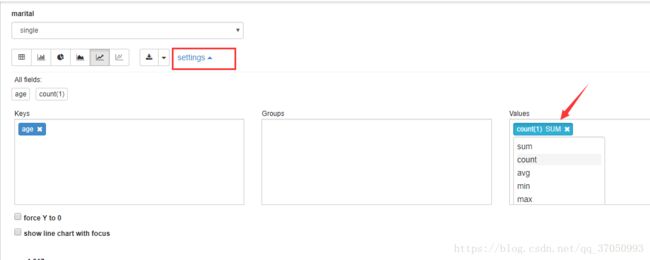
keys和Groups以及Values可以选择相应的X标识将其去除,如果想添加Values可以选择聚合函数会提示其他聚合函数,提供要添加keys,可以再All fields拖至Keys框内。