吴恩达deep learning笔记第四课 卷积神经网络
DL.ai笔记:第四课 卷积神经网络
第一周 卷积神经网络
1.1计算机视觉
当图片尺寸变大后,如1000X1000X3的输入, 如果用全连接网络,第一层隐藏层1000个神经单元,参数量为三百万,参数量会大大增加,不仅无法解决过拟合问题,并且内存也无法满足。
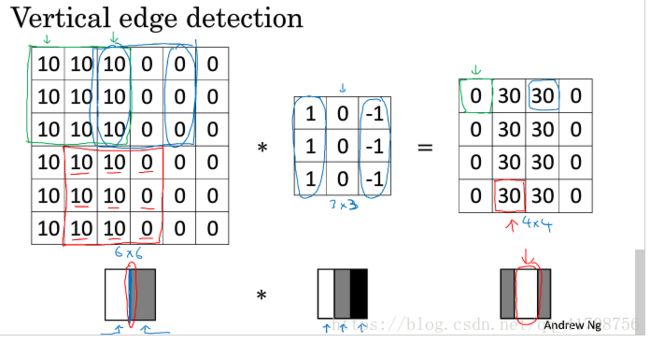
1.2边缘检测示例
用卷积运算实现垂直边缘检测,看数字矩阵下方的图,左边的红色圈出来的边缘通过卷积运算后明显的被识别出来了(右边红色圈出来的边缘)。中间1,0,-1的过滤器可以检测出垂直边缘,水平边缘检测也是同理:稍微改变过滤器中数值。
1.3更多边缘检测内容
区分正边(由亮到暗)和负边(由暗到亮),以不同的边缘滤波器(垂直,水平,弯曲,倾斜60度等等等的)。
为了检测不同边缘从而出现了多个卷积核的应用。
但我们使用时运用了将滤波器中数字都当做参数的思想,通过反向传播来自己学习检测不同边缘。
1.4padding
如果不用SAME方式padding的缺点有两个:
1.输出图片尺寸会缩小。2。输入图片边缘像素点只被触碰一次,意味着你丢弃了图片边缘的许多信息。 Without padding, very few values at the next layer would be affected by pixels as the edges of an image.
解决此问题的方法就是padding(填充)。
至于填充多少元素由两种选择:VALID(不填充),SAME(填充后输入输出大小一样,p = (f-1)/2),滤波器大小基本为奇数(惯例) ,这样same才能对称填充,而不是不对称填充。并且奇数滤波器有一个中心像素点,会更方便指出滤波器的位置。
1.5卷积步长
注意输出尺寸向下取整(如果不能整除,多出来不要了)

1.6卷积为何有效
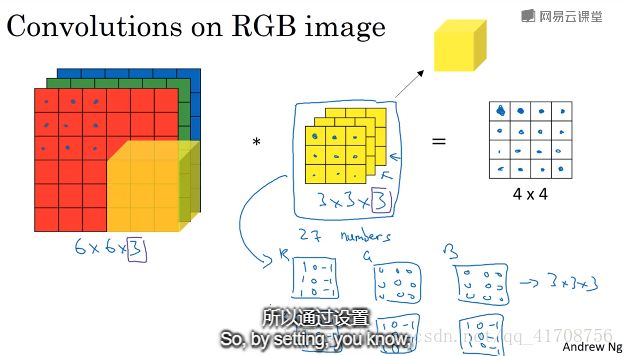
可以通过滤波器的元素大小检测不同颜色通道的边缘。为了检测不同边缘从而出现了多个卷积核的应用。
1.7单层卷积网络
卷积神经网络不管输入图片多少大,参数量都不变,并且大大小于全连接神经网络,所以卷积网络的一个特征:避免过拟合
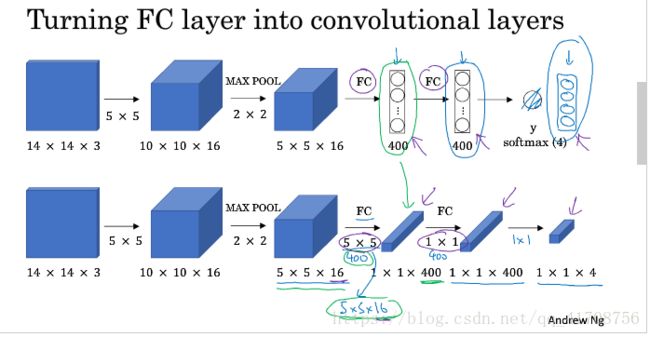
各个参数尺寸大小,标记如下图所示:

1.8简单卷积网络示例

1.9池化层
池化层常用来缩减模型的大小,提高计算速度,同时提高所提取特征的robust。
有超参数:f(尺寸),s(步长),平均或最大池化,很少用到padding,没有参数要学习,一旦确定就是固定运算,不需要梯度下降学习。输出尺寸和卷积一样。
1.10卷积神经网络示例
下图是,是通过卷积池化卷积池化全连接来实现的(典型的LeNet-5),还有其他常用的模式:1至多次卷积再池化,再一至多次卷积再池化....再全连接层。总体流程都是尺寸变小,深度加深。
下面是各层激活值和参数量示意图:
会发现如下几点:
1.池化层没有参数,不需学习
2.卷积层参数相对较少
3.全连接层参数较多
4.激活值不能下降太快,下降太快会影响网络性能,要逐渐下降
5.吴恩达经验!!!如何把模块整合在一起,构建高效的神经网络: 需要深入的理解和感觉,找到整合基本构造模块的感觉最好的方法是大量阅读别人整合基本模块的案例,成功构建高效神经网络的具体案例,或把他人的框架应用于自己的应用程序!

1.11为什么使用卷积
卷积的两个优势:参数共享和稀疏连接(输出中每个单元只与与自己连接的几个单元相关)
第二周 深度卷积网络实例探究
2.1为什么要进行实例探究?
找感觉的最好方法就是去看一些案例,研究别人构建有效组件的案例。在计算机视觉任务中表现良好的神经网络框架,往往也适用于其他任务,此时,也应该可以读一些计算机视觉方面的研究论文了。本周通过讲解LeNnet-5,AlexNet,VGG,ResNet,Inception网络的同时来进行学习。
2.2经典网络
LeNet-5
以手写数字图片为输入
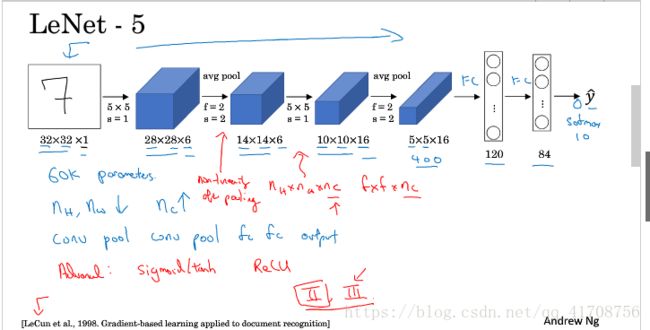
看论文时:发现人们那时用的是simoid或者tanh激活函数,而不是Relu, 以前因为计算能力的原因,在每次卷积的时候用到了很复杂的运算方式,现在已经不用了。吴恩达建议精读第二段,这段重点介绍了这种网络结构,泛读第三段,主要是一些有趣的实验结果。
AlexNet
原文中使用的图像是224x224x3,而尝试推导后会发现227x227x3更好。
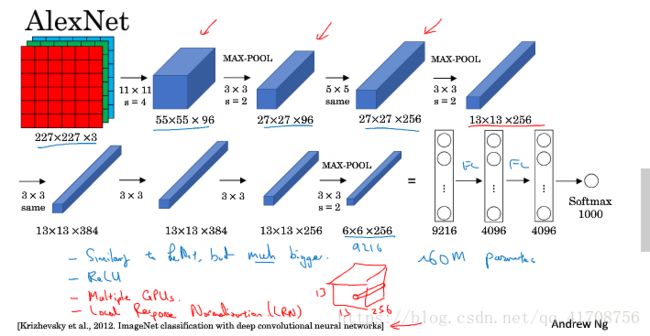
优点见之前的tf实战,不过相比这里也看出来一点,相比LeNet5的6万参数,这里的AlexNet有6千万参数。使用了Eelu激活,还有SAME的填充。
看论文时:因为当时GPU速度慢,AlexNet采用了非常复杂的方法在两个GPU上进行训练。并且经典AlexNet结构还有另一种类型的ceng层,叫做局部响应归一化层,即LRN层,现在用的并不多,作用不大,可以划掉不看。
这是比较容易的一篇,学习起来容易一些。
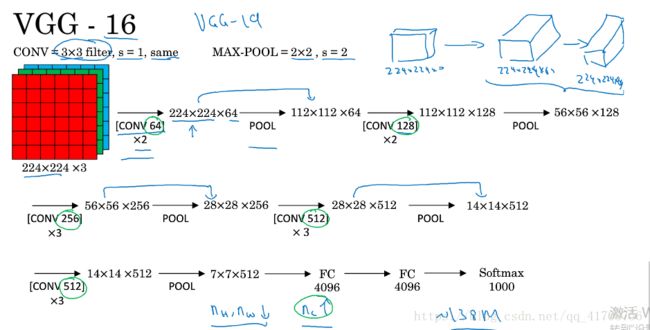
VGG-16
没有那么多超参数,这是一种只需要专注于构建卷积层的简单网络。
一大优点是的确简化了神经网络结构。结构并不复杂,这一点非常吸引人。一定卷积池化后长宽减半,深度翻倍。
缺点是约有1.38亿个参数,需要训练的特征数量非常巨大。
VGG19和VGG16性能相仿,所以普遍使用VGG-16,16的意思是卷积层加池化层加全连接层的数量。
2.3残差网络
因为训练层数很深很深的网络很难,存在梯度消失和梯度爆炸的问题。
这节课我们学习跳远连接,来构建能够训练深度网络的ResNets。深度可达百层。
残差网络由残差块组成。
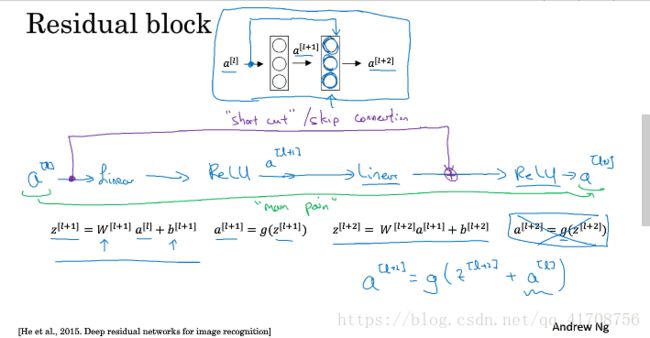
如上图,就是通过捷径建立一个残差块。会发现“跳远连接”就是建立一条捷径,从a[l]至relu前,参与relu运算。跳过的层数可以自由选择。
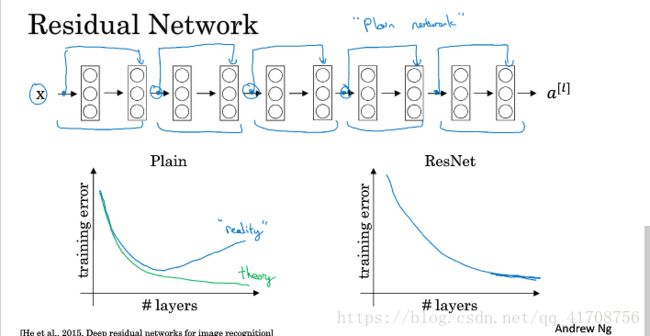
2.4残差网络为什么有用?
第三课了解到:网络在训练集上表现好,才能在Hold-out交叉验证集或dev集和测试集上有好的表现。所以至少在训练集上训练好ResNet是第一步。
如图公式推导,会发现加入残差块的网络效率并不会逊色于更简单的神经网络,因为学习恒等函数对它来说很简单。所以大型的神经网络,将残差块加入中间或者末端并无影响网络的效率。
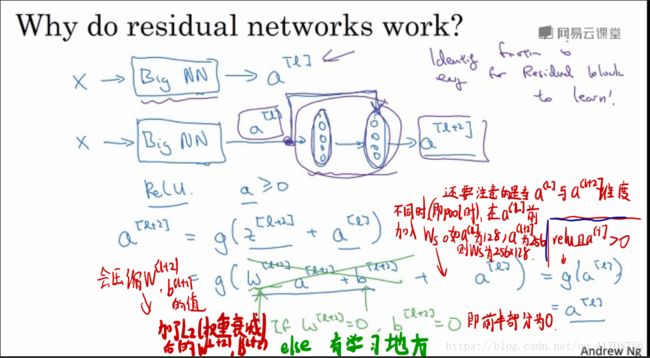
我们的目标不仅仅是保持网络效率,还要提升它的效率:如果这些隐层单元学到一些有用的信息,那么它可能比学习恒等函数表现得更好,如果学不到,也不会影响效率。能确定网络效率不受影响,并且创建类似残差网络很多时候甚至可以提高效率。
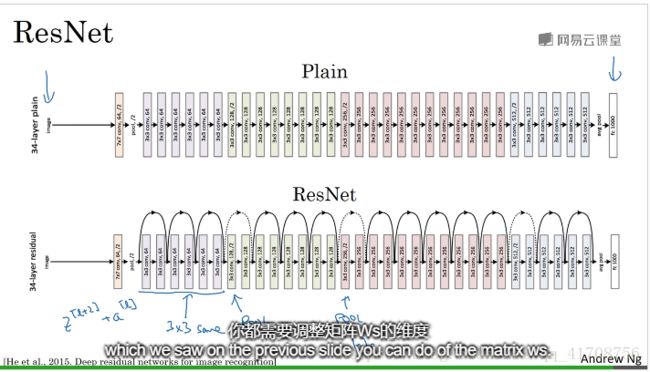
会发现在pool的时候输入和输出维度不一样,此时就需要加入上张图片中的Ws来改变a[L]维度,Ws是一个可以通过网络学习的矩阵。

2.5网络中的网络以及1x1卷积
1x1卷积(network in network)有什么用?看上去只是一个数字乘以一个权重,但别忘了输入有多个通道。见下图
下面的图用了1x1卷积每个主题相当于32xfilters num的全连接网络。
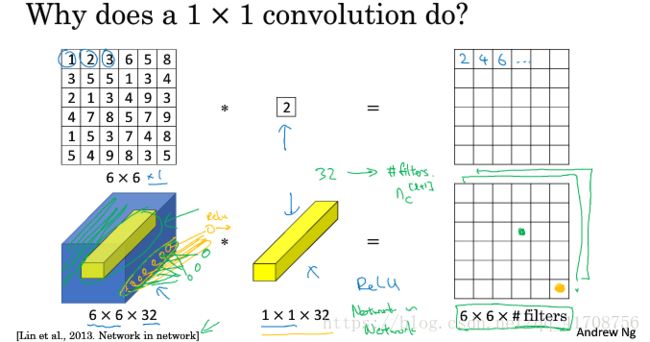
长宽可以通过pool压缩,那信道数量nC大的情况下,怎么压缩信道数量nC减少计算呢?可以通过1x1卷积。

也可以不变信道数量,来让网络学习更复杂的网络(因为加了一次非线性函数)。
总结:1x1卷积可以在学习的同时改变信道数量
2.5谷歌Inception网络简介
构建卷积层时,要考虑过滤器大小究竟是1x3,3x3,5x5,要不要添加lrn层等等
inception网络的作用就是代替你做决定,虽然网络架构因此变得更加复杂,但网络表现却非常好。
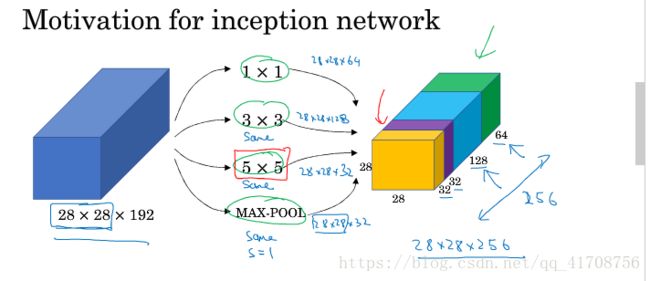
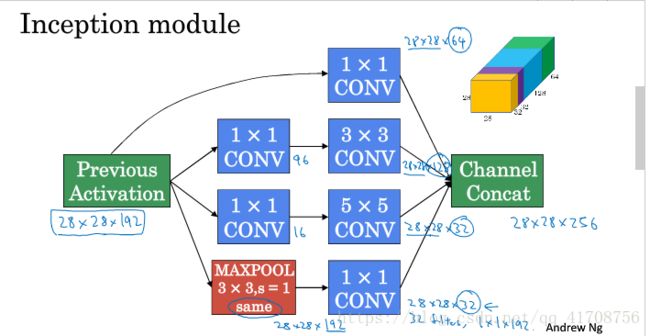
基本思想是Inception网络不需要人为决定使用哪个过滤器,或是否需要池化,而是由网络自行确定这些参数。
你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。不难发现,所描述的inception层有一个问题,就是计算成本。下面该图是5x5的计算成本:
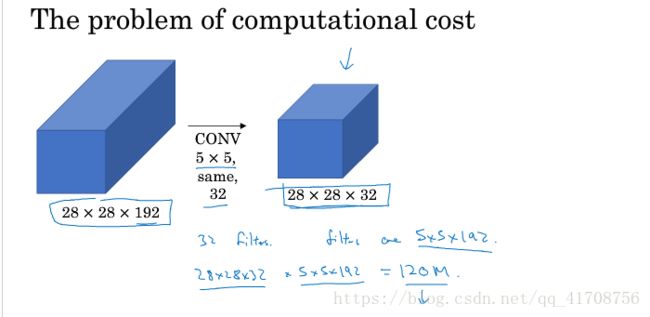
如图,计算成本是:28x28x32 x 5x5x192=120million次乘法运算。
有什么办法可以达到相同的效果,又大大减小运算量呢?通过1x1卷积的中间层。有时这被称为瓶颈层(bottleneck layer)。
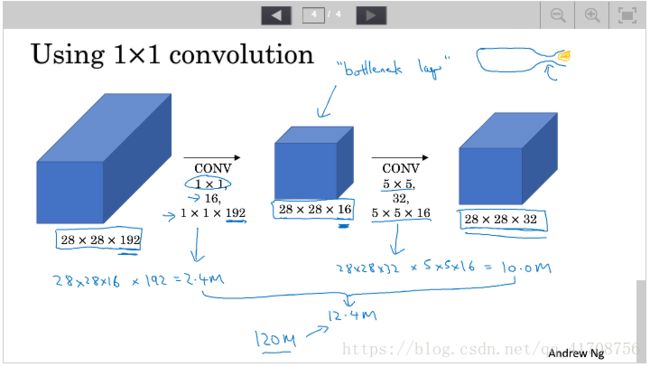
先缩小,再扩大
如图,计算成本为:28x28x16x192=2.4million,28x28x32x5x5x16=10million,共12.4million乘法运算。下降了十倍
总结:1.如果不确定使用什么滤波器,inception模块是最好的选择,我可以应用各种类型的过滤器,只需把输出连起来。
2.通过1x1卷积(瓶颈层battleneck layer)大大减少计算成本。
2.7Inception 网络
本节将学习如何将这些模块组合起来,构筑自己的Inception网络。
如下就是一个Inception模块,Inception网络要做的就是将这些模块组合起来。
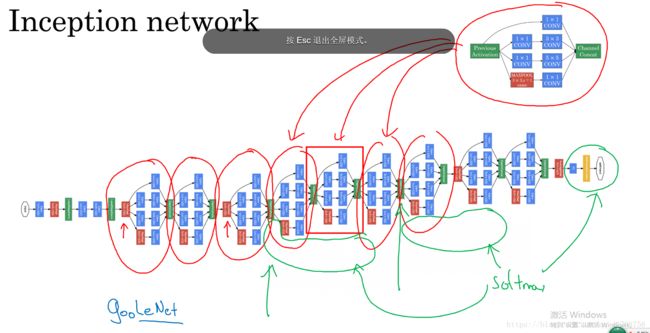
论文中在中间也加入了全连接softmax分支来预测,来证明中间隐藏层也参与了特征运算,也参与了图片分类。
有inceptionv1,v2,v3,v4等版本的论文,通过这些课已经可以去阅读一些inception的论文了。
2.8使用开源的实现方案
当看到一篇论文,想运用其成果时,建议在网上找到其开源实现,会快很多。如Github,视频中介绍了github的简单使用。
2.9迁移学习
如果要做一个计算机视觉的应用,相比于从头训练权重,或者随机初始化权重,如果下载别人已经训练好网络结构的权重,能够进展的相当快,用这个作为预训练,然后转换到感兴趣的部分上。
很多计算机视觉网站上有coco等数据集,通常需要训练好几周,这意味着我们可以运用别人训练好几周做出来的开源的权重参数,把它当作一个很好的初始化,运用到自己的网络上,用迁移学习把公共的知识迁移到自己的问题上。
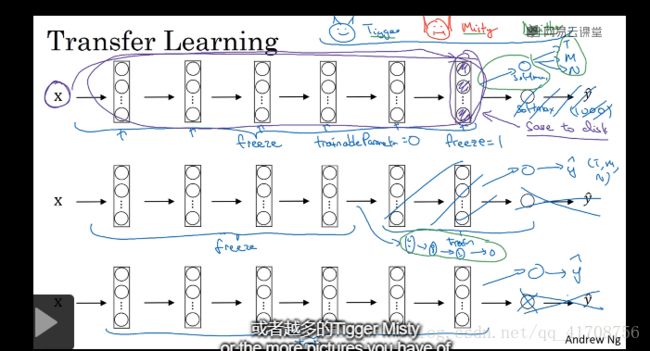
比如上图,你的问题是三分类:Tigger,Misty和None
你可以下载网上训练好的ImageNet的1000分类模型,去掉softmax添加上自己的softmax
前面层部分的权重参数冻结,后面层部分训练,具体取决于:你自己的训练集的多少
如果你的训练集足够多,你可以只用网上训练好的模型参数做初始化,自己再训练
如果你的训练集很少,就用网上模型的参数,并且通过框架里的freeze参数冻结不训练,只用于预测
如果你的训练集不多不少,可以冻结前面部分层,训练后面部分层。
2.9数据扩充
经常使用的实用技巧:垂直镜像对称,随机裁剪
还有:旋转,剪切,扭曲等等,比较麻烦
color shifting:对R,G,B改变数值来变换颜色。了解:PCA(主要部分)颜色增强,如照片是紫色(主要由红黄部分,蓝色很好),PCA会使得红黄变化多一点,蓝色变化少一点,使得颜色总体一致。 可以再网上找到PCA颜色增强的开源实现方法。,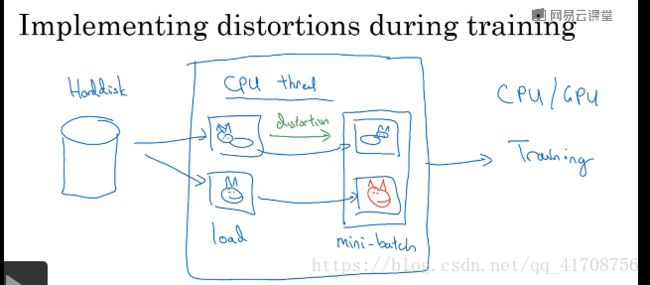
数据增强过程中也有一些超参数,比如颜色变化了多少,以及随即裁剪的时候使用的参数等等,与计算机视觉的其他部分类似,一个好的开始是运用别人的开源实现,了解他们如何实现数据增强。
2.11计算机视觉现状
1.运用于论文和比赛基准(bechmarks)情况提高准确率的方法技巧:
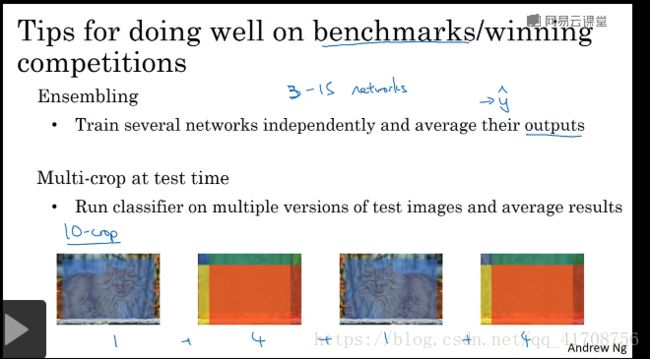
1.集成学习(Ensembling):用3-15个networks分别训练神经网络,对输出值取平均。(不是对权重)
参考:https://blog.csdn.net/h4565445654/article/details/70111058
2.Multi-crop:在测试时用multi-crop方法,并平均结果。如常用的10-crop,即将图片垂直镜像后并各复制一份,第一,三张取中间部分。第二,四张分别取四个边角的大范围部分(如图),共十张来测试平均结果。

第三周 目标检测
3.1目标定位
之前学的是 图像分类问题,这节课学的是构建神经网络的另一个问题,即定位分类问题。
定位分类问题:不仅仅是识别出物体的分类,还要再图片中标记出它的位置。
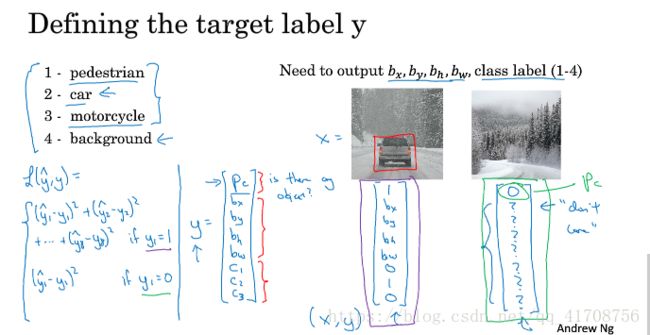
如上图,通过输出y:pc:为1则代表识别出物体,为0则为backgroud,后面的数也就没了意义
bx,by:代表识别出物体的中心点坐标。bh,bw:识别出物体边框的长高
c1,c2,c3:则代表各类物体。
计算损失loss时的一种方法:如果pc为1,则都参与计算得一个损失,如果pc为0,则就pc参与计算的一个损失。
3.2特征点检测
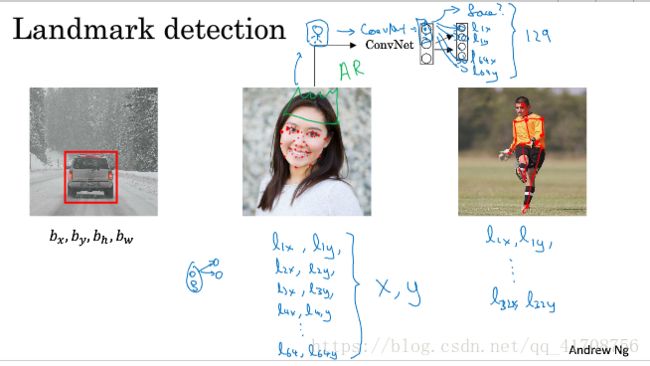
不同于上一节的边框,特征点检测增加了多个特征点(人为在图片中标记)的输出,来勾勒出特征。
3.3目标检测
这节课,我们将学习如何通过卷及网络进行对象检测。

如上图所示,是滑动窗口目标检测,显示通过汽车图片训练好一个判别汽车的模型,然后通过滑动窗口一个个截取图片不同部分,来判断是否有车。并且可以通过不同大小的窗口判断。
滑动窗口目标检测也有明显的缺点,就是计算成本。因为在图像中分出很多小块要一个个通过卷及网络处理。如果通过步幅增大来减少窗口数量,但会影响性能,如果步幅过小,计算成本过高。
3.4卷积的滑动窗口实现
用1x1卷积代替全连接层
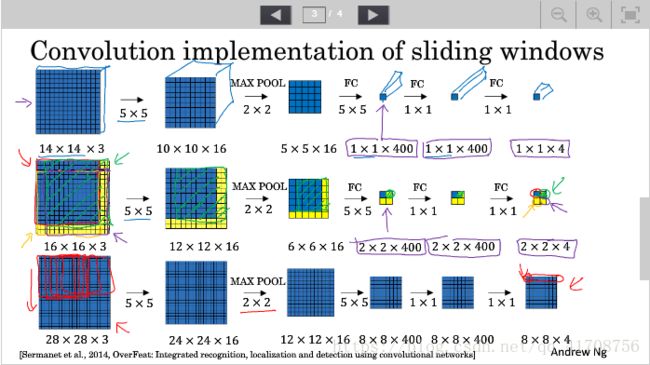
因为一次次输入图片计算成本太高,解决办法:将整张图片输入,实际上不同方框对应着输出结果的不同部分(即方框大小部分输入该神经网络,然后输出得到部分)。这样可以一次得到所有预测值,提高了整个算法的效率。
但这个算法还有一个问题,不能输出最精准的边界框,见下一节。
3.5Bounding Box 预测
得到更精准的边界框,不像之前一样不能找到一个最 匹配汽车的框。
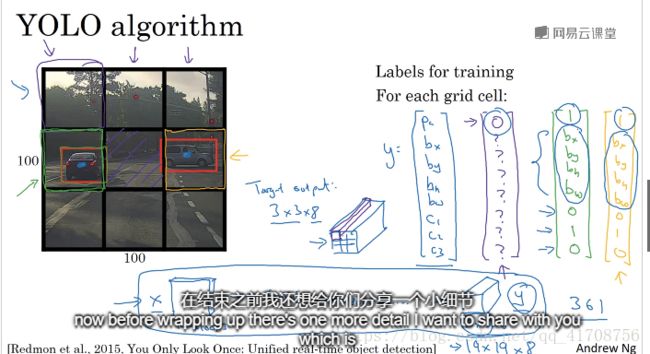
YOLO:将图片分成N X N的方格输入神经网络,每个网格跟3.1定位分类问题一样输出一个包含8个值得y,根据物体中心点在哪个方格就将方框定位在哪个方格。如图分成3x3的格子,最后输出是3x3x9。算法只需单次卷积实现,效率很高,并且因为是卷积实现的,所以运行速度很快,可以实时识别。
如何编码bx,by,bh,bw?
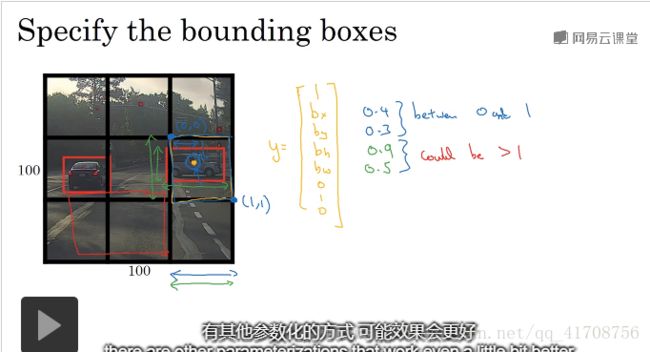
如图,因为中心点在哪个格子,汽车就被分到哪个格子内,以格子左上角为(0,0),右下角为(1,1),所以bx,by肯定在0,1之间,而bh,bw代表汽车长宽,可以占据多个格子,所以可以大于1。当然还有许多其他优秀的参数设置方法(可以看yolo的论文,难度较高,一些细节很难理解),这里就介绍这一种。
3.6交并比
如何判断对象检测算法运作良好?
通过交并比(IoU)函数,用来评价对象检测算法。
交并比函数:计算两个边界框交集和并集之比。

最好情况是1,一半交并比大于1,那么结果是可以接受的,0.5是阈值,定的越高越好。但一般不低于0.5
3.7非极大值抑制(只输出概率最大的框(可能多个物体多个框))
之前说的方法都是对图像检测多次,非极大值算法会是的算法对每个对象只检测一次。
当yolo算法中格子取得多了,很多格子都会报告检测出车辆,因此会造成每辆车都触发多次检测。
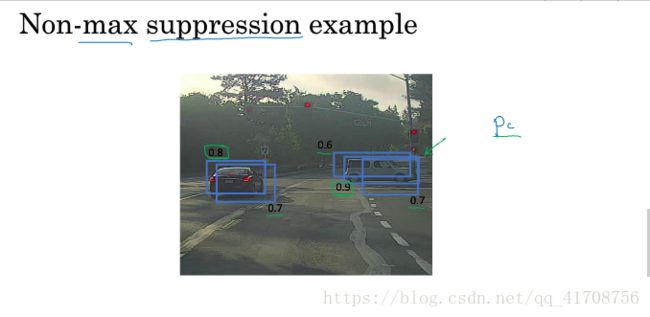
解决办法:先找超过pc超过阈值的框,再找出pc值最高的pc,然后依次找pc值第二高,第三高的pc值得框,如果和最高的框交并比高,就抑制。
所有所有框就会被高亮或者变暗,最后抛弃所有暗的选项,就会剩下预测结果。

3.8anchor box
可能一个格子里即是人的中心点,又是车的中心点。
到目前,对象检测存在的一个问题是,每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,就是使用anchor box的概念。
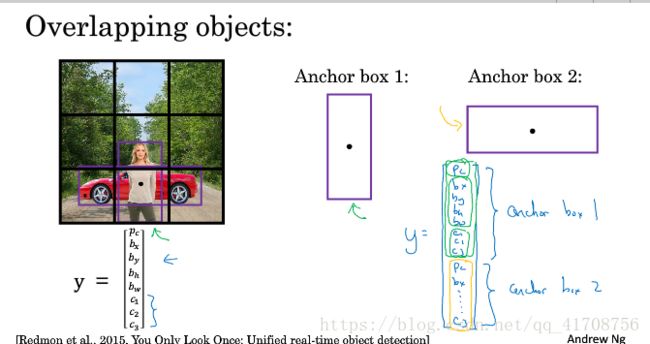
左边是之前的输出y,右边是加入anchor box的输出y(amchor1和anchor2组合而成)。

建立anchor box是为了处理两个对象出现在同一个格子的情况。(事实上,这种情况很少,特别是19x19的格子,而不是3x3的格子)。
3.9YOLO算法
YOLO对象检测算法。该实例分3类,图像分3x3格,2格anchor,所以输出y是3x3x2x8
相当于一遍前向传播后,有3x3x16的输出,即3x3x2的anchor,抛弃低概率(低pc的框),然后根据每一个分类用非极大值抑制得出定位和分类。
3.10(选修)RPN网络
前面说的yolo算法是end to end(端对端)的算法。
no end to end(非端对端):先提取候选框再分别输入分类,即在图上提取出候选框然后再一个个输出CNN来判断是否有物体并定位,如3.1节中的R-CNN算法(regions with CNN features)。缺点:太慢
Fast R-CNN:是对R-CNN的改进,用了卷积滑动窗口,即3.4中的方法。每个原始区域对应输出的一个区域(通过相同的流程算法大小)。缺点:得到候选区域的聚类步骤仍然非常缓慢。
Faster R-CNN:用了卷积神经网络而不是传统的分割算法来提取候选区域。但还是比YOLO慢
YOLO:end to end的一种算法,将图片分成NXN一次输入,结合anchor得到输出,根据pc值和阈值筛选后,再根据anchor非极大值抑制(根据交并比)判断出中心点所在框来完成定位和分类。
SSD(SSD: Single Shot MultiBox Detector)是采用单个深度神经网络模型实现目标检测和识别的方法。该方法是综合了Faster R-CNN的anchor box和YOLO单个神经网络检测思路(end-to-end).
第四周 特殊应用:人脸识别和神经风格转换
4.1什么是人脸识别?
难点在于,要解决“一次学习”的问题。
Face recognition problems commonly fall into two categories:
- Face Verification - "is this the claimed person?". For example, at some airports, you can pass through customs by letting a system scan your passport and then verifying that you (the person carrying the passport) are the correct person. A mobile phone that unlocks using your face is also using face verification. This is a 1:1 matching problem.
- Face Recognition - "who is this person?". For example, the video lecture showed a face recognition video (https://www.youtube.com/watch?v=wr4rx0Spihs) of Baidu employees entering the office without needing to otherwise identify themselves. This is a 1:K matching problem.
4.2One-shot 学习
这意味着通过一张照片或者一个人脸样例就识别出一个人。
通过similarity函数可以实现,输入一张图片,与数据库中存储每张图片对比得出一个“差值”d,小于设定的阈值则same,大于设定的阈值就different。
下面就是通过神经网络来训练函数d。
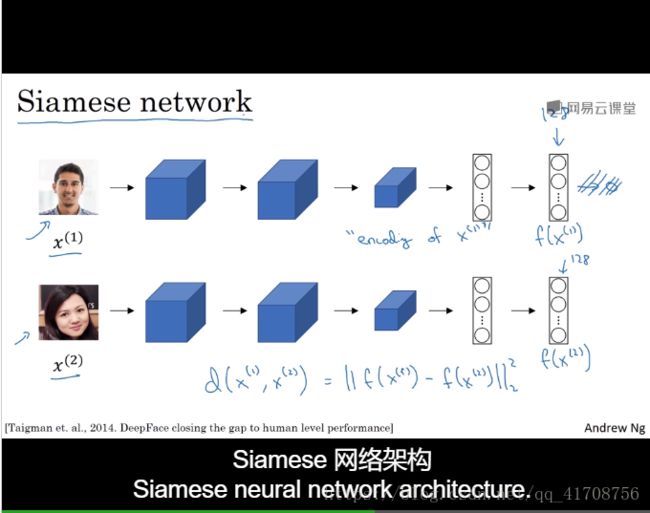
4.3 Siamese网络
如下图,通过输入图片最后输出128个元素的向量,输出f(x1),该向量可以称作是“encoding of x(1)”
第二张图片输入输出的向量f(x2),称作是encoding of x(2)
如图算d(x(1),x(2)),计算f(x1),f(x2)范数。
如何训练这个网络呢?如下图所示,输出一张图片进神经网络,输出128维的向量
通过如果x(i),x(j)是同一个人,则范数较小,反之较大。
输出向量后再反向传播以满足上述条件。

4.4Triplet(三元组)损失
即通过anchor,positive,negative三张图,其中anchor和positive是同一个人,negative不是。
所要做的就是让anchor和positive差值较小,anchor和negative差值较大。
方式如下,其中参数alpha是为了让AP差距远小于AN差距。

基于Triplet损失的损失函数loss如下:
通过max(...,0)当...小于0时损失函数为0,不然就有损失了。

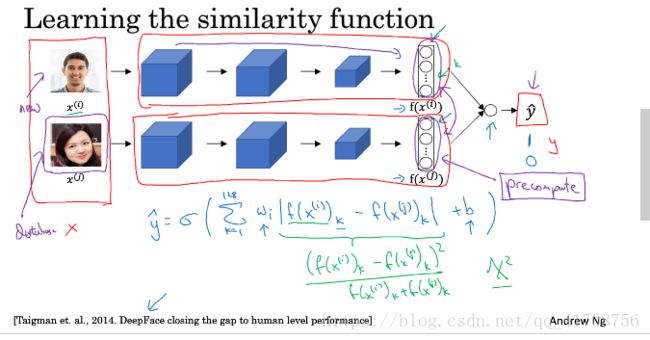
4.5面部验证与二分类
除了triplet loss的方法,还可以把面部识别当做二分类问题。通过下述激活的方法。
可以看出,此时的输入为一对图片,不再是Triple3元组。

4.6什么是神经风格转换?
通过内容图像(C)和风格图像(S)来完成合成图像(G),如画出毕加索风格的金门大桥。
4.7深度卷积网络在学什么?
这节课通过一些可视化的例子来看卷积网络中较大的层在学什么,有助于理解如何实现神经风格迁移。

4.8代价函数(神经风格转换的代价函数)
神经风格转换的原理也是定义个代价函数J,通过反向传播减少它来完成合成。
其中代价函数J由内容代价函数Jc和风格代价函数Js组成。公式如下图

每次反向更新的是合成图片G的100x100x3的像素点,一开始是随机产生的白噪声点,一步步更新产生图片。所以更新的是合成图像G的像素点值。

4.9内容代价函数

1.选取中间隐藏层来计算内容代价(一半不深,也不浅)
2.用预训练的卷积网络(如VGG)
3.观察图片C,G的l层的激活值a[l]
4.两者相近则图片内容相似。
4.10风格损失函数
风格损失函数通过对比不同通道间的相关系数得到。

其中G[l]是为了生成第l层的风格矩阵S和合成矩阵G的G矩阵,用于计算Js,其中G矩阵的各个元素(共Nc X Nc,即Nc的平方的通道组合)计算方法如下。

如果考虑到各层的style函数(这样效果更好),即对各层Js乘以一定系数相加。

所以会发现神经网络风格迁移是unsupervised learning。
4.11一维到三维推广
见视频,讲解了一维和三维数据的卷积处理。