领域驱动设计的概念
大家都知道软件开发不是一蹴而就的事情,我们不可能在不了解产品(或行业领域)的前提下进行软件开发,在开发前通常需要进行大量的业务知识梳理,然后才能到软件设计的层面,最后才是开发。而在业务知识梳理的过程中,必然会形成某个领域知识,根据领域知识来一步步驱动软件设计,就是领域驱动设计(DDD,Domain-Driven Design)的基本概念 。
为什么需要 DDD
在业务初期,功能大都非常简单,普通的 CRUD 就基本能满足要求,此时系统是清晰的。但随着产品的不断迭代和演化,业务逻辑变得越来越复杂,我们的系统也越来越冗杂。各个模块之间彼此关联,甚至到后期连相应的开发者都很难说清模块的具体功能和意图到底是啥。这就会导致在想要修改一个功能时,要追溯到这个功能需要修改的点就要很长时间,更别提修改带来的不可预知的影响面。 比如下图所示:
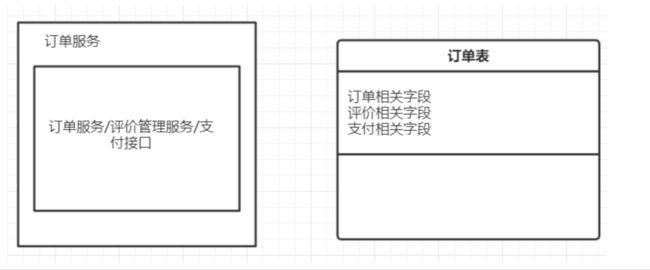
订单服务中提供了查询、创建订单相关的接口,也提供了订单评价、支付的接口。同时订单表是个大表,包含了非常多字段。我们在维护代码时,将会导致牵一发而动全身,很可能原本我们只是想改下评价相关的功能,却影响到了创建订单的核心流程。虽然我们可以通过测试来保证功能的完备性,但当我们在订单领域有大量需求同时并行开发时将会出现改动重叠、恶性循环、疲于奔命修改各种问题的局面,而且大量的全量回归会给测试带来不可接受的灾难。
但现实中绝大部分公司都是这样一个状态,然后一般他们的解决方案是不断的重构系统,让系统的设计随着业务成长也进行不断的演进。通过重构出一些独立的类来存放某些通用的逻辑解决混乱问题,但是我们很难给它一个业务上的含义,只能以技术纬度进行描述,那么带来的问题就是其他人接手这块代码的时候不知道这个的含义或者只能通过修改通用逻辑来达到某些需求。
领域模型追本溯源
实际上,领域模型本身也不是一个陌生的单词,说直白点,在早期开发中,领域模型就是数据库设计。因为你想:我们做传统项目的流程或者说包括现在我们做项目的流程,都是首先讨论需求,然后是数据库建模,在需求逐步确定的过程不断的去变更数据库的设计,接着我们在项目开发阶段,发现有些关系没有建、有些字段少了、有些表结构设计不合理,又在不断的去调整设计,最后上线。在传统项目中,数据库是整个项目的根本,数据模型出来以后后续的开发都是围绕着数据展开,然后形成如下的一个架构 :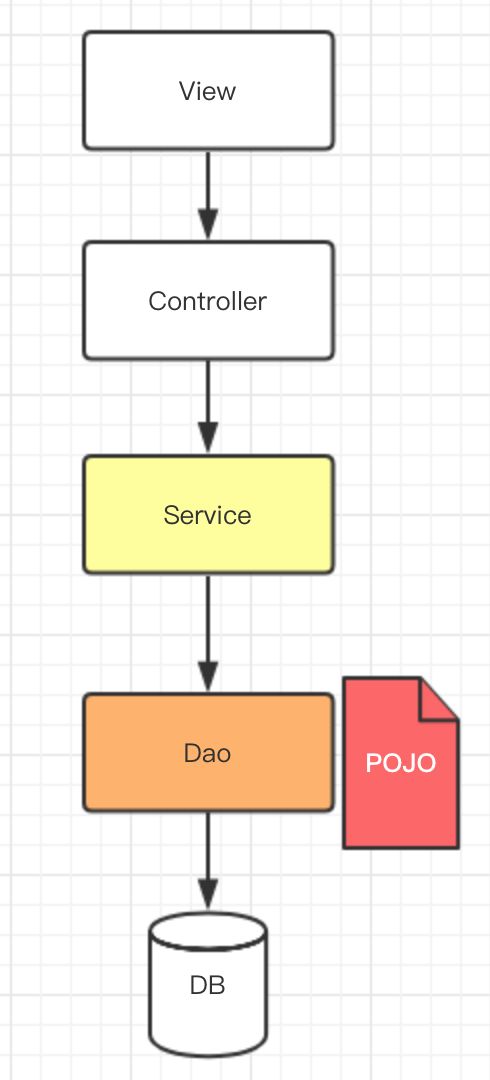 很显然,这其中存在的问题如下:
很显然,这其中存在的问题如下:
- Service层很重,所有逻辑处理基本都放在service层。
- POJO作为 Service 层非常重要的一个实体,会因为不同场景的需求做不同的变化和组合,就会造成 POJO 的几种不同模型(失血、贫血、充血),以此用来形容领域模型太胖或者太瘦。
- 随着业务变得复杂以后,包括数据结构的变化,那么各 个模块就需要进行修改,原本清晰的系统经过不断的演 化变得复杂、冗余、耦合度高,后果就非常严重。
我们试想一下如果一个软件产品不依赖数据库存储设备,那我们怎么去设计这个软件呢?如果没有了数据存储,那么我们的领域模型就得基于程序本身来设计。那这个就是 DDD 需要去考虑的问题。
DDD中的基本概念
实体(Entity)
当一个对象由其标识(而不是属性)区分时,这种对象称为实体(Entity)。比如当两个对象的标识不同时,即使两个对象的其他属性全都相同,我们也认为他们是两个完全不同的实体。
值对象(Value Object)
当一个对象用于对事物进行描述而没有唯一标识时,那么它被称作值对象。因为在领域中并不是任何时候一个事物都需要有一个唯一的标识,也就是说我们并不关心具体是哪个事物,只关心这个事物是什么。比如下单流程中,对于配送地址来说,只要是地址信息相同,我们就认为是同一个配送地址。由于不具有唯一标示,我们也不能说"这一个"值对象或者"那一个"值对象。
领域服务(Domain Service)
一些重要的领域行为或操作,它们不太适合建模为实体对象或者值对象,它们本质上只是一些操作,并不是具体的事物,另一方面这些操作往往又会涉及到多个领域对象的操作,它们只负责来协调这些领域对象完成操作而已,那么我们可以归类它们为领域服务。它实现了全部业务逻辑并且通过各种校验手段保证业务的正确性。同时呢,它也能避免在应用层出现领域逻辑。理解起来,领域服务有点facade的味道。
聚合及聚合根(Aggregate,Aggregate Root)
聚合是通过定义领域对象之间清晰的所属关系以及边界来实现领域模型的内聚,以此来避免形成错综复杂的、难以维护的对象关系网。聚合定义了一组具有内聚关系的相关领域对象的集合,我们可以把聚合看作是一个修改数据的单元。
聚合根属于实体对象,它是领域对象中一个高度内聚的核心对象。(聚合根具有全局的唯一标识,而实体只有在聚合内部有唯一的本地标识,值对象没有唯一标识,不存在这个值对象或那个值对象的说法)
若一个聚合仅有一个实体,那这个实体就是聚合根;但要有多个实体,我们就要思考聚合内哪个对象有独立存在的意义且可以和外部领域直接进行交互。
工厂(Factory)
DDD中的工厂也是一种封装思想的体现。引入工厂的原因是:有时创建一个领域对象是一件相对比较复杂的事情,而不是简单的new操作。工厂的作用是隐藏创建对象的细节。事实上大部分情况下,领域对象的创建都不会相对太复杂,故我们仅需使用简单的构造函数创建对象就可以。隐藏创建对象细节的好处是显而易见的,这样就可以不会让领域层的业务逻辑泄露到应用层,同时也减轻应用层负担,它只要简单调用领域工厂来创建出期望的对象就可以了。
仓储(Repository)
资源仓储封装了基础设施来提供查询和持久化聚合操作。这样能够让我们始终关注在模型层面,把对象的存储和访问都委托给资源库来完成。它不是数据库的封装,而是领域层与基础设施之间的桥梁。DDD 关心的是领域内的模型,而不是数据库的操作。
实战演练如何让DDD落地
DDD 概念理解起来有点抽象, 这个有点像设计模式,感觉很有用,但是自己开发的时候又不知道怎么应用到代码里面,或者生搬硬套后自己看起来都很别扭,那么接下来我们就以一个简单的转盘抽奖案例来分析一下 DDD 的应用。
针对功能层面划分边界
这个系统可以划分为运营管理平台和用户使用层,运营平 台对于抽奖的配置比较复杂但是操作频率会比较低。而用 户对抽奖活动页面的使用是高频率的但是对于配置规则来 说是误感知的,根据这样的特点,我们把抽奖平台划分针 对 C 端抽奖和 M 端抽奖两个子域。
在确认了 M 端领域和 C 端的限界上下文后,我们再对各 自上下文内部进行限界上下文的划分,接下来以 C 端用 户为例来划分界限上下文。
确认基本需求
首先我们要来了解该产品的基本需求
- 抽奖资格(什么情况下会有抽奖机会、抽奖次数、抽 奖的活动起始时间) 。
- 抽奖的奖品(实物、优惠券、理财金、购物卡…) 。
- 奖品自身的配置,概率、库存、某些奖品在有限的概 率下还只能被限制抽到多少次等。
- 风控对接, 防止恶意薅羊毛。
针对产品功能划分边界
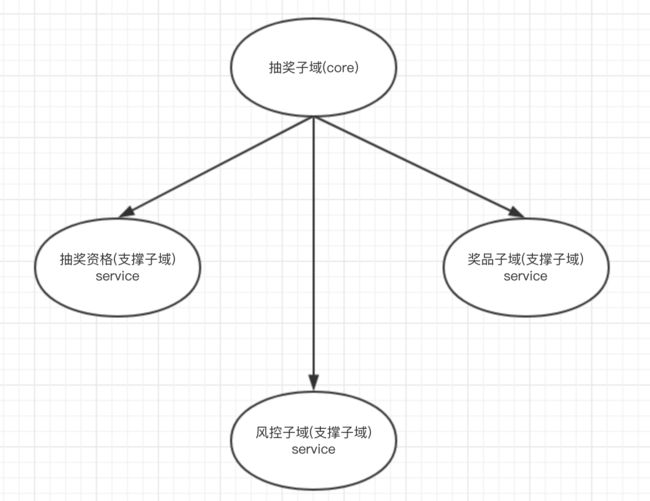
抽奖上下文是整个领域的核心,负责处理用户抽奖的核心业务。
- 对于抽奖的限制,我们定义了抽奖资格的通用语言,将抽奖开始 / 结束时间,抽奖可参与次数等限制条件都收拢到抽奖资格子域中。
- 由于 C 端存在一些刷单行为,我们根据产品需求定义了风控上下文,用于对抽奖进行风控。
- 由于抽奖和发放奖品其实可以认为是两个领域,一个负责根据概率去抽奖、另一个负责将抽中的奖品发放出去,所以对于这一块也独立出来一个领域。
细化上下文
通过上下文划分以后,我们还需要进一步梳理上下文之间的关系,梳理的好处在于:
- 任务更好拆分(一个开发人员可以全身心投入到相关子域的上下文中) 。
- 方便沟通,明确自身上下文和其他上下文之间的依赖关 系,可以实现更好的对接。
代码设计
在实际开发中,我们一般会采用模块来表示一个领域的界 限上下文,比如:
- 抽奖上下文:com.hafiz.business.lottery.*
- 风控上下文:com.hafiz.business.riskcontroller.*
- 奖品上下文:com.hafiz.business.prize.*
- 活动资格上下文 : com.hafiz.business.qualification.*
- 库存上下文:com.hafiz.business.stock.*
对于模块内的组织结构,一般情况下我们是按照领域对象、 领域服务、领域资源库、防腐层等组织方式定义的。
- 领域对象-值对象: com.hafiz.business.lottery.domain.valobj.*
- 领域对象-实体: com.hafiz.business.lottery.domain.entity.*
- 领域对象-聚合根: com.hafiz.business.lottery.domain.aggregate.*
- 领域服务: com.hafiz.business.lottery.domain.service.*
- 领域资源库: com.hafiz.business.lottery.domain.repo.*
- 领域防腐层:com.hafiz.business.lottery.domain.facade.*
部分代码如下:
抽奖聚合根:
拥有抽奖活动id和该活动下所有可用的奖池列表,它最主要的领域功能是根据一个抽奖的场景(DrawLotteryContext),通过chooseAwardPool方法筛选出一个匹配的奖池。
package com.hafiz.business.lottery.domain.aggregate;
import ...;
public class DrawLottery {
private int lotteryId; // 抽奖id
private List awardPools; // 奖池列表
public void setLotteryId(int lotteryId) {
if (lotteryId < 0) {
throw new IllegalArgumentException("非法的抽奖id");
}
this.lotteryId = lotteryId;
}
public AwardPool chooseAwardPool(DrawLotteryContext context) {
...
}
}
奖池值对象:
package com.hafiz.business.lottery.domain.valobj;
import ...;
public class AwardPool {
private String cityIds; // 奖池支持的城市
private String scores; // 奖池支持的得分
private int userGroupType; // 奖池匹配的用户类型
private List awards; // 奖池中包含的奖品
public boolean matchedCity(int cityId) {
...
}
public boolean matchedScore(int score) {
...
}
public Award randomGetAward() {
int sumOfProbablity = 0;
for (Award award : awards) {
sumOfProbablity += award.getAwardProbablity();
}
int randomNumber = ThreadLocalRandom.current().netInt(sumOfProbablity);
int range = 0;
for (Award award : awards) {
range += award.getAwardProbablity();
if (randomNumber < range) {
return award;
}
}
return null;
}
}
抽奖资源库:
我们屏蔽对底层奖池及奖品的直接访问,仅对抽奖的聚合根资源进行管理。
package com.hafiz.business.lottery.domain.repo;
import ...;
public class DrawLotteryRepository {
@Autowried
private AwardDao awardDao;
@Autowried
private AwardPoolDao awardPoolDao;
@Autowried
private DrawLotteryCacheAccessObj drawLotteryCacheAccessObj;
public DrawLottery getDrawLotteryById(int lotteryId) {
DrawLottery drawLottery = drawLotteryCacheAccessObj.get(lotteryId);
if (drawLottery != null) {
return drawLottery;
}
drawLottery = getDrawLotteryFromDB(lotteryId);
drawLotteryCacheAccessObj.add(lotteryId, drawLottery);
return drawLottery;
}
private DrawLottery getDrawLotteryFromDB() {
...
}
}
防腐层:
以用户信息防腐层为例,它的入参是抽奖请求参数(LotteryContext),输出为城市信息(CityInfo)。
package com.hafiz.business.lottery.domain.facade;
import ...;
public class UserCityInfoFacade {
@Autowried
private CityService cityService;
public CityInfo getCityInfo (LotteryContext context) {
CityRequest request = new CityRequest();
request.setLat(context.getLat());
request.setLng(context.getLng());
CityReponse reponse = cityService.getCityInfo(request);
return buildCityInfo(reponse);
}
private CityInfo buildCityInfo(CityReponse reponse) {
...
}
}
抽奖领域服务:
package com.hafiz.business.lottery.domain.service.impl;
import ...;
@Service
public class LotteryServiceImpl implements LotteryService {
@Autowried
private DrawLotteryRepository drawLotteryRepository;
@Autowried
private UserCityInfoFacade userCityInfoFacade;
@Autowried
private AwardSenderService awardSenderService;
@Autowried
private AwardCountFacade awardCountFacade;
public LotteryReponse drawLottery(LotteryContext context) {
// 获取抽奖聚合根
DrawLottery drawLottery = drawLotteryRepository.getDrawLotteryById(context.getLotteryId());
// 增加抽奖计数信息
awardCountFacade.incrTryCount(context);
// 选中奖池
AwardPool awardPool = drawLottery.chooseAwardPool(context);
// 抽出奖品
Award award = awardPool.randomGetAward();
// 发出奖品
return buildLotteryReponse(awardSenderService.sendeAward(award, context));
}
private LotteryReponse buildLotteryReponse(AwardSendReponse awardSendReponse) {
...
}
}
领域驱动的好处
用 DDD 可以很好的解决领域模型到设计模型的同步、演进最后映射到实际的代码逻辑,总的来说,DDD 开发模式有以下几个好处 :
- DDD 能让我们知道如何抽象出限界上下文以及如何去分而治之。
- 分而治之 : 把复杂的大规模软件拆分成若干个子模块,每一个模块都能独立运行和解决相关问题。并且分割后各个部分可以组装成为一个整体。
- 抽象 : 使用抽象能够精简问题空间,而且问题越小越容易理解,比如说我们要对接支付,抽象的纬度应该是支付,而不是具体的微信支付还是支付宝支付。
- DDD 的限界上下文可以完美匹配微服务的要求。在系统复杂之后,我们都需要用分治来拆解问题。一般有两种方式,技术维度和业务维度。技术维度是类似 MVC 这 样,业务维度则是指按业务领域来划分系统。 微服务架构更强调从业务维度去做分治来应对系统复杂度, 而 DDD 也是同样的着重业务视角。
总结
其实我们可以简单认为领域驱动设计是一种指导思想,是一种软件开发方法。通过 DDD 我们可以将系统结构设计的更加合理, 以便最终满足高内聚低耦合的要求。在我的观点来看,有点类似数据库的三范式,我们开始在学的时候并不太理解,当有足够的设计经验以后慢慢会体会到三范式带来的好处。同时我们也并不一定需要完全严格按照这三范式去进行实践,有些情况下是可以也需要灵活调整的。
公众号中,我们正在进行第一次的赠书活动,本期要赠出的三本书为:《Spring Cloud实战》、《Spring Cloud与Docker微服务架构实战》、《架构探险-轻量级微服务架构》。欢迎大家到公众号中去参与赠书活动,活动有效期三天哈~
推荐两篇不错的DDD文章:
https://www.cnblogs.com/netfocus/archive/2011/10/10/2204949.html
https://blog.csdn.net/k6T9Q8XKs6iIkZPPIFq/article/details/78909897