AAAI 2020 | 速度提升200倍,基于耦合知识蒸馏的视频显著区域检测算法
2020 年 2 月 7 日-2 月 12 日,AAAI 2020 将于美国纽约举办。不久之前,大会官方公布了今年的论文收录信息:收到 8800 篇提交论文,评审了 7737 篇,接收 1591 篇,接收率 20.6%。本文介绍了爱奇艺与北航等机构合作的论文《Ultrafast Video Attention Prediction with Coupled Knowledge Distillation》。

论文链接:
https://arxiv.org/pdf/1904.04449.pdf
本论文设计了一个超轻量级网络 UVA-Net,并提出了一种基于耦合知识蒸馏的网络训练方法,在视频注意力预测方向的性能可与 11 个最新模型相媲美,而其存储空间仅占用 0.68 MB,在 GPU,CPU 上的速度分别达到 10,106FPS,404FPS,比之前的模型提升了 206 倍。
由于传统的高精度视频显著区域检测模型往往对计算能力和存储能力有较高要求,处理速度较慢,造成了资源的浪费。因此,视频显著区域检测需要解决如下两个问题:1)如何降低模型的计算量和存储空间需求,提高处理效率?2)如何从视频中提取有效时空联合特征,避免准确率下降?
针对这些问题,作者提出了耦合知识蒸馏的轻量级视频显著区域检测方法 [1]。轻量级视频显著区域检测的难点在于模型泛化能力不足,时域空域线索结合难,影响方法的检测性能。为此,作者提出了一种轻量级的网络结构 UVA-Net,并利用耦合知识蒸馏的训练方法提高视频显著区域检测性能。
MobileNetV2 作为一种轻量级网络结构(如表 3(a)所示)在较大提高的网络的紧凑性的同时,损失了部分精度。作者在 MobileNetV2 的基础上提出了一种 CA-Res block 结构,具体如表 3(b)所示,利用这种网络结构训练的模型比之前的方法快 206 倍。

作者采用耦合知识蒸馏的方法来进行网络的训练,该方法首先使用低分辨率视频帧作为输入,在尽可能保留视频显著区域检测所需的时域和空域信息的前提下,减少网络的计算量;然后利用结构复杂的时域和空域网络作为教师模型,以耦合知识蒸馏的方式,监督训练结构简单的时空联合的学生模型,大幅度降低了模型参数规模和对存储空间的需求。具体如图 6 所示。
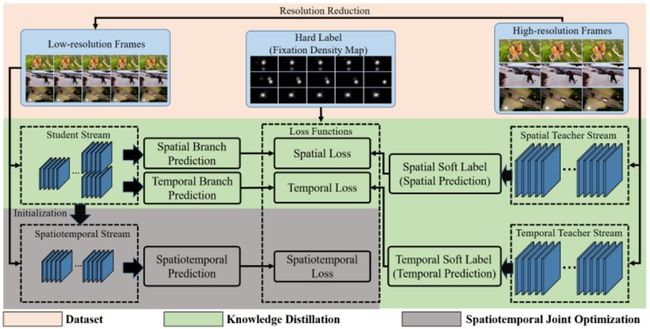
图 6 :基于耦合知识蒸馏的超高速视频显著区域检测方法。
作者在 AVS1K 数据集上进行模型评测,具体结果如表 4 和表 5 所示。从表中我们可以看出 UVA-DVA-64 达到了和其他高性能模型相当的性能,但是模型只有 2.73M,速度达到了 404.3 FPS,而 UVA-DVA-32 性能虽略有下降,模型却只有 0.68M,速度达到了 10,106 FPS。

表 4:在 AVS1K 上的性能对比。

表 5:AVS1K 数据集上的代表性帧结果. (a) Video frame, (b) Ground truth, (c) HFT, (d) SP, (e) PNSP, (f) SSD, (g) LDS, (h) eDN, (i) iSEEL, (j) DVA, (k) SalNet, (l) STS, (m) UVA-DVA-32, (n) UVA-DVA-64.
作者提出的基于耦合知识蒸馏的超高速视频显著区域检测算法与现有的国际高水平方法相比,计算精度与 11 种国际高水平方法相当,能够有效解决任务中模型泛化能力不足,时域空域线索结合难导致的问题,并具有良好的视频显著区域检测效果,且易于迁移到其它任务。
目前该技术已经应用到爱奇艺以图搜剧、视频智能创作等产品中,显著性ROI区域的检测对精准理解图片、视频内容具有很大的帮助。例如爱奇艺智能创作的竖版模式,仅保留视频显著性内容,将从视频理解内容本身提高用户的观看体验。另外,视频显著性分析将对爱奇艺多个业务具有启发意义,例如爱奇艺奇观(AI雷达)、只看TA等,给用户带来更优质的体验。
文献请引用:
[1]Fu, K., Shi, P., Song, Y., Ge, S., Lu, X. & Li, J. (2019). Ultrafast Video Attention Prediction with Coupled Knowledge Distillation. In AAAI, 2020.

也许你还想看
ICCV 2019论文 | 爱奇艺提出利用无标签数据优化人脸识别模型
2019 ICME论文解析:爱奇艺首创实时自适应码率算法评估系统

扫一扫下方二维码,更多精彩内容陪伴你!
