《数学之美》中的模型及启示总结
目录
- 初衷
- 文章编排
- 章节总结
- 第1章 文字和语言 vs 数字和信息
- 第2章 自然语言处理——从规律到统计
- 第3章 统计语言模型
- 第4章 谈谈中文分词
- 第5章 隐含马尔可夫模型
- 第6章 信息的度量和作用
- 第7章 贾里尼克和现代语言处理
- 第8章 简单之美——布尔代数和搜索引擎的索引
- 第9章 图论和网络爬虫
- 第10章 PageRank——Google的民主表决式网页排名技术
- 第11章 如何确定网页和查询的相关性
- 第12章 地图和本地搜索的最基本技术——有限状态机和动态规划
- 第13章 Google AK-47的设计者——阿米特·辛格博士
- 第14章 余弦定理和新闻分类
- 第15章 矩阵运算和文本处理中的两个分类问题
- 第16章 信息指纹及其应用
- 第17章 由电视剧《暗算》所想到的——谈谈密码学的数学原理
- 第18章 闪光的不一定是金子——谈谈搜索引擎反作弊问题
- 第19章 谈谈数学模型的重要性
- 第20章 不要把鸡蛋放到一个篮子里——谈谈最大熵模型
- 第21章 拼音输入法的数学原理
- 第22章 自然语言处理的教父马库斯和他的优秀弟子们
- 第23章 布隆过滤器
- 第24章 马尔可夫链的拓展——贝叶斯网络
- 第25章 条件随机场和句法分析
- 第26章 维特比和他的维特比算法
- 第27章 再谈文本自动分类问题——期望最大化算法
- 第28章 逻辑回归和搜索广告
- 第29章 逐个击破算法和Google云计算的基础
- 第30章 Google大脑和人工神经网络
- 第31章 大数据的威力
- 读后感
初衷
这是我的第一篇博客,主要是自己看完一本书之后总喜欢写点什么。这篇文章主要是为了记录一些《数学之美》这本书中我在意的地方,俗话说“好记性不如烂笔头”嘛,总结一遍加深印象,也方便以后回顾。当然这样总结对于其他读者不免枯燥无味,所以如果你但凡有一点兴趣的话,请务必抽出时间读一读原书。
文章编排
原书的每章最后都有小结,故我在这里主要记录一些我觉得很有启发性的小点和模型,按照原书章节的前后顺序。最后附上心得体会。
章节总结
第1章 文字和语言 vs 数字和信息
信息传播的模型:
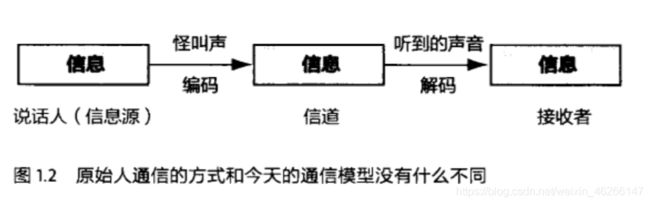
信息经过编码后,通过信道传播,到接受者处解码还原成信息。
信息的冗余是信息安全的保障。罗塞塔石碑上的内容是同一信息重复三次,只要有一份完好保存下来,原有的信息就不会丢失。
犹太人抄写圣经时用到的“校验”系统:将每个字对应为一个数字,记录每一行、每一列的这些数相加成为行校验码、列校验码,最后通过比较和原文的校验码是否相同,检查是否有抄写错误。
第2章 自然语言处理——从规律到统计
基于统计的自然语言处理方法,将自然语言处理“抽象”成了语言的初衷——通信问题。
老科学家可以理解成“老的科学家”和“老科学的家”两种。
第3章 统计语言模型
贾里尼克(统计自然语言处理的开创者)的出发点:一个句子是否合理,就看它的可能性大小如何。一个句子出现的概率越大,他就越有可能合理。
马尔可夫假设:一个“状态”出现的概率只同它前面一个“状态”有关。(此处的状态在统计语言模型中就是指一句话中的某个词)
当然实际应用可以假设概率与前面N个“状态"有关,相应模型的复杂度也会增大,训练难度也会增加,但一般来说会越准确。
假设S表示一个有意义的句子,由一连串特定顺序排列的词w1,w2,…,wn组成,n是句子的长度。P(S)表示S在文本中出现的概率。
P(S) = P(w1,w2,…,wn)
利用条件概率的公式:
P(w1,w2,…,wn) = P(w1)·P(w2|w1)·P(w3|w1,w2)···P(wn|w1,w2,w3,…,wn-1)
其中P(wi)表示第i个词出现的概率;P(w2|w1)表示在第一个词出现的条件下,第二次出现的概率,以此类推。不难发现,第n个词的出现概率取决于它前面的所有词。
这里就可以用马尔可夫假设对模型进行简化。得到:
P(w1,w2,…,wn) = P(w1)·P(w2|w1)·P(w3|w2)···P(wn|wn-1)
上式对应的统计语言模型是二元模型,即每个词只与前面一个词相关。
根据条件概率的定义:P(wi|wi-1) = P(wi, wi-1)/P(wi-1)
而P(wi, wi-1)和P(wi-1)只要数据量足够,可以很容易的统计出来。
此处统计语言模型的推导过程,让我不禁想到了贝叶斯分类器。
平滑处理——零概率问题:
古德-图灵估计:对于没有看见的事件,我们不能认为它发生的概率就是零,因此我们从概率的总量中,分配一个很小的比例给予这些没有看见的事件,同时将所有看见的事件概率按照“越是不可信的统计折扣的越多”的方法调小一点。

仔细想想对于贝叶斯分类器中的零概率问题也是这么解决的。
第4章 谈谈中文分词
运用统计语言模型解决歧义性,原理同上一章,也是依靠句子出现概率来进行判断。
根据不同的应用,”汉语分词“的颗粒度大小应该不同。比如,在机器翻译中,颗粒度应该大一点,”北京大学“就不能被分成两个词。而在语音识别中,”北京大学“一般是被分成两个词。
(即不同的应用场景,算法的精密度要求也不同,针对优化,整体性能通常能得到不错的提升)
统计模型并不是万能的,虽然效果比其他方法更好,但无法做到完全正确。
第5章 隐含马尔可夫模型
马尔可夫链:符合马尔可夫假设的随机过程被称为马尔可夫过程或者马尔可夫链。

把这个马尔可夫链看成一个机器,随机选择一个初始状态,随后按照上面的规律随机选择后续状态。这样运行一段时间后,就会产生一个状态序列:S1,S2,S3,···ST。根据这个序列,输出某个状态mi的出现次数,以及mi转换到mj的次数,从而估计出从mi转换到mj的转换概率。
隐含马尔可夫模型是马尔可夫链的一个拓展:任一时刻t的状态st是不可见的,但是隐含马尔可夫模型在每个时刻会输出一个ot,而且ot和st相关且仅与st相关。这个被称为独立输出假设。

经过一些证明,可以证得:通信解码问题可以通过隐含马尔可夫模型解决,如果能将待解决的问题(如某些自然语言处理)等价于通信解码问题,就可以利用隐含马尔可夫模型来解决。(”抽象“的妙用)
隐含马尔可夫模型的训练:提到了鲍姆-韦尔奇算法,抽象的思路是从假定的一个模型M1出发,找到更好的模型M2。(诸多细节省略)
第6章 信息的度量和作用
信息熵——信息的度量,符号用H表示,单位是bit。数学定义如下:

变量的不确定性越大,信息熵越大。
信息的作用就是消除不确定性,换言之,如果没有信息,任何公式或者数字的游戏都无法排除不确定性。
第7章 贾里尼克和现代语言处理
这一章类似于作者对贾里尼克作的传。故我仅摘录我印象最深刻的一些文字。


好方法是相对的,坏方法是“绝对”的。

第8章 简单之美——布尔代数和搜索引擎的索引
搜索引擎的原理其实非常简单:
1.自动下载尽可能多的网页;
2.建立快速有效的索引;
3.根据相关性对网页进行公平准确的排序。
第9章 图论和网络爬虫
总结一下数据结构中图的常用算法并简述其原理:
图遍历算法:BFS和DFS
最小生成树:Kruskal算法和Prim算法
Kruskal算法:每次选择图中最短的边,但不能与已选的边成环。
Prim算法:选定一个初始点,按照弧的两个端点一端已选一段未选的方法,选择最短的弧,同样要求不能构成回路(环)。
最短路径:Dijkstra算法和Floyd算法
Dijkstra算法:针对单源路径最短问题,给定一出发点,计算出发点到其余各点的距离。给每个点设一个值D代表初始点到该点的最小距离,初始这个值为∞(初始点的D设为0),按照类似广度优先的方法不停深入,每次走最短的那条弧,刷新D的值,直到完成图的遍历。
Floyd算法:针对多源路径最短问题,原理基于:假设从A点到E点的最短路径经过C点,那么这条路径上从A到C的路径一定是A到C的最短路径。是个动态规划问题。
网络爬虫如何下载整个互联网:假定从一家门户网站的首页出发,先下载这个网页,然后通过分析这个网页,可以找到网页里所有的超链接,接下来访问、下载、分析这些超链接所指的网页,又能找到其他的网页,不停重复下去,就能下载整个互联网。避免下载的网页重复,可以利用“哈希表”记录网页是否下载过。如果把每个网页看作一个节点,超链接看作弧,是不是很像图的遍历呢?
“‘如何构建一个网络爬虫’是我在谷歌最常使用的一道面试题”——
三个关键问题:
1.遍历的方法是什么?DFS or BFS?
2.页面的分析和URL的提取
3.记录那些网页已经下载过的小本本——URL本
存储哈希表的服务器之间的通信问题。好的办法一般都用到了这两个技术:首先明确每台下载服务器的分工,也就是说在调度的时候一看到URL就知道改由那个服务器进行下载;URL下载的批处理。
第10章 PageRank——Google的民主表决式网页排名技术
在互联网上,如果一个网页被很多其他网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高。这就是PageRank的核心思想。
网页排名的高明之处就在于它把整个互联网当作一个整体来对待。这无意识中符合了系统论的观点。
第11章 如何确定网页和查询的相关性
搜索关键词权重的科学度量TF-IDF:
根据直觉,包含关键词较多的网页应该比包含它们少的网页相关。当然,需要根据网页的长度,对关键词的次数进行归一化,也就是用关键词的次数除以网页的总字数。我们把这个商称为“关键词频率”,或者“单文本词频”(Term Frequency)。
很容易发现,如果一个关键词只在很少的网页中出现,通过它就容易锁定目标,它的权重也应该大。(比如一些专业性术语)
反之,如果一个词在大量网页中出现,看到它仍不很清楚要找什么内容,因此它的权重就应该小。(比如“的”这个字)
概括的讲,假定一个关键词w在Dw个网页中出现过,那么Dw越大,w的权重就越小,反之亦然。在信息检索中,使用最多的权重是“逆文本频率指数”(Inverse Document Frequency,缩写为IDF),它的公式为log(D / Dw)。
最后对TF,利用IDF,加权求和,用来度量相关性。
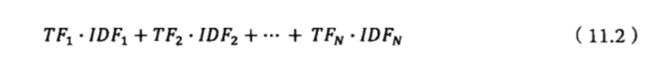
第12章 地图和本地搜索的最基本技术——有限状态机和动态规划
一个有限向量机是一个特殊的有向图,它包括一些状态(节点)和连接这些状态的有向弧。下图是一个识别中国地址的有限状态机的简单例子。

每个有限状态机有一个开始状态和一个终止状态,以及若干中间状态。每一条弧上带有一个从一个状态进入下一个状态的条件。
有限状态机在计算机科学中早期的成功应用是在程序语言编译器的设计中,它只能严格匹配,而无法模糊匹配。
为了解决这个问题,科学家们提出了基于概率的有限状态机。这种基于概率的有限状态机和离散的马尔可夫链基本上等效。
有限状态传感器
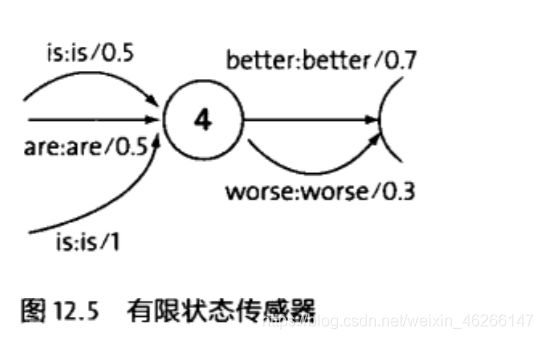
加权的有限状态传感器(Weighted Finite State Transducer,简称WFST)

WFST中的每一条路径就是一个候选的句子,其中概率最大的那条路径就是这个句子的识别结果。
第13章 Google AK-47的设计者——阿米特·辛格博士
遵循简单的哲学
辛格之所以总是能找到那些简单有效的方法,不是靠直觉,也不是靠撞大运,这首先是靠他丰富的科研经验。…其次,辛格坚持每天要分析一些搜索结果不好的例子,以掌握第一手的资料。
辛格非常鼓励年轻人要不怕失败,大胆尝试。
第14章 余弦定理和新闻分类
新闻分类的一种思路:提取出新闻的特征向量,向量的夹角越小,即这两篇新闻相似度越高,用余弦定理算出向量夹角。
可以从中抽象出分类的一个思路:数据->特征向量->计算特征向量之间的“距离”->按照“距离”远近分类。
第15章 矩阵运算和文本处理中的两个分类问题
矩阵运算中的奇异值分解(Singular Value Decomposition,简称SVD)
奇异值分解,就是将一个大矩阵分解成三个小矩阵相乘,可以减小矩阵的储存量和计算量。

而这三个小矩阵都有各自的物理含义。依照这些小矩阵的物理意义,可以解决很多问题。
和上一章利用特征向量余弦的方法相比,奇异值分解的优点是能够更快地得到结果(在实际应用中),因为它不需要一次次的迭代。但是这种方法得到的分类结果比较粗糙,因此它适合处理超大规模文本的粗分类。在实际工作中,可以结合奇异值分解和特征向量余弦。
第16章 信息指纹及其应用
讲到网络爬虫的时候,提到过用一个哈希表存储已经下载过的URL,如果直接储存字符串形式的URL,不仅浪费空间,而且查找也很慢。
因此,如果能找到一个随即映射函数,将每一个URL“不重复”的对应为一个“数”,是不是能节省时间和空间开销呢?对应的那个“数”就称为信息指纹。(不重复也指重复的概率非常小,工程上可以忽略)
网页(字符串)的信息指纹的计算方法一般分两步。首先,将这个字符串看成一个特殊的、长度很长的整数。这一步很容易,因为计算机储存字符串也是把它看成一个整数(我们都知道ASCII码)。接下来就需要一个产生信息指纹的关键算法:伪随机数产生器算法(Pseudo-Random Number Generator,简称PRNG),通过它将任意长度的整数转化为指定长度的伪随机数。现在常用的是梅森旋转算法(Mersenne Twister)。
信息指纹常用于判定集合相同,判定集合基本相同(比如:提取网页的特征词集合再比较,而不是直接比较网页的信息指纹;文章查重)。
第17章 由电视剧《暗算》所想到的——谈谈密码学的数学原理
目前最常用的加密方法:公开密钥
数学形式非常简单,只是一些乘除而已。
第18章 闪光的不一定是金子——谈谈搜索引擎反作弊问题
通信模型对搜索引擎反作弊依然适用。在通信中解决噪音干扰的问题基本有两个思路:
1.从信息源出发,加强通信(编码)自身的抗干扰能力。
2.从传输来看,过滤掉噪音,还原信息。
搜索引擎作弊从本质上来讲看就如同对(搜索)排序的信息中加入了噪音。反作弊则就是除去噪音。
第19章 谈谈数学模型的重要性

1.一个正确的数学模型应当在形式上是简单的。(托勒密的模型显然太复杂)
2.一个正确的模型一开始可能还不如一个精雕细琢过的错误模型来的准去,但是,如果我们认定大方向是对的,就应该坚持下去。(日心说开始还没有地心说准确)
3.大量准确数据对研发很重要(开普勒继承老师第谷的大量数据)
4.正确的模型也可能受噪音的干扰,而显得不准确;这时候不应该用一种凑合的方法来弥补它,而是要找到噪音的根源,这也许能通往重大的发现。
第20章 不要把鸡蛋放到一个篮子里——谈谈最大熵模型
最大熵原理指出,需要对一个随机事件的概率分布进行预测时,我们的预测应该满足全部已知条件,而对未知的条件不要做任何主观假设。(不做主观假设这一点很重要)在这种情况下,概率分布最均匀,预测的风险最小。因为这时候概率分布的信息熵最大,所以人们称这种模型叫“最大熵模型”。
最大熵模型拥有指数函数形式,在形式上是最漂亮,最完美的统计模型。可以将各种信息整合到一个模型,但是训练的计算量巨大。
第21章 拼音输入法的数学原理
香农第一定理指出:对于一个信息,任何编码的长度都不小于它的信息熵。
这一章中,**拼音输入法最终也转换成了最短路径问题!**数学的奇妙!
第22章 自然语言处理的教父马库斯和他的优秀弟子们
马库斯的两个弟子:
追求完美的柯林斯
认为简单才美的布莱尔
两个极端,最终都走向了成功。
第23章 布隆过滤器
前面第16章讲到信息指纹用于优化哈希表查重。由于哈希表的存储效率只有50%,存储上百亿个邮件地址可能需要上百G的内存,但是除了超级计算机,一般的服务器是无法存储的。为了解决这个问题,介绍布隆过滤器。
布隆过滤器的构建过程:
假定需要存储一亿个电子邮件地址,先创建一个16亿二进制位的全零向量。将每一个电子邮件地址用8个随机数产生器产生8个信息指纹。再用一个随机数产生器把这八个信息指纹映射到1到16亿中的8个自然数,将相应位置的二进制位设为1,对所有地址处理完毕后,一个布隆过滤器就完成了。

查看一个电子邮件地址是否在黑名单中,用同样的随机数生成器(F1,F2,F3···F8,G)映射到8个自然数上,如果这八个二进制位都是1,就说明这个电子邮件在黑名单中。
布隆过滤器不会漏过任何一个黑名单中的可疑地址,但是有极小的概率会误判正常的电子邮件地址,这时候可以通过列白名单的方式,防止误判。
第24章 马尔可夫链的拓展——贝叶斯网络
马尔可夫链中,一个状态只与它的前一个状态有关,在现实生活中,两个事物的关系可能是错综复杂的,如下图。

一个满足马尔可夫假设的上述有向图就是一个贝叶斯网络。
由于各节点的概率都可以用贝叶斯公式算的,故得名为贝叶斯网络。
第25章 条件随机场和句法分析
条件随机场是一个特殊的马尔可夫模型。如下图。
xi表示观测值,yi表示隐含的状态值。

条件随机场依然满足马尔可夫假设,即每个状态只与前一个状态有关。
它和之前介绍的贝叶斯网络很像,区别在于,贝叶斯网络是有向图,条件随机场是无向图。
第26章 维特比和他的维特比算法
维特比算法是一个特殊的但应用广泛的动态规划算法。维特比算法是针对一个特殊图——篱笆网络的有向图的最短路径问题而提出的。
它之所以重要,是因为凡是使用隐含马尔可夫模型描述的问题都可以用它来解码。

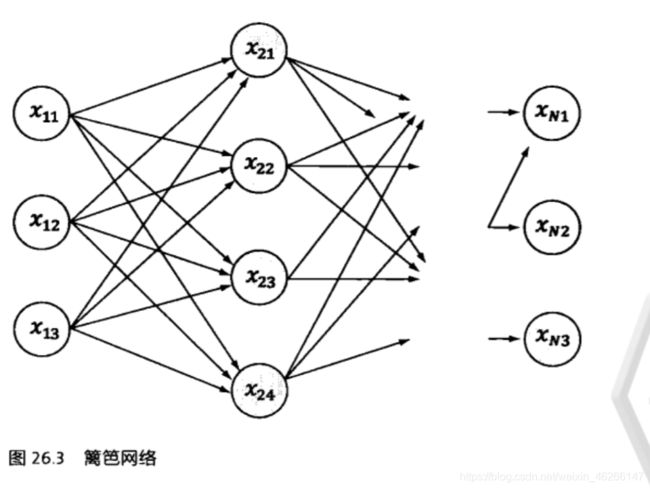
维特比算法的基础可以概括为以下三点:
1.如果概率最大的路径P经过某个点,那么P的从起始点S到这个点的一段子路径,一定是起始点S到这个点的最短路径。(有点像Floyd算法)
2.从起始点S到终点E,必然经过第i时刻的某个状态(这显然是大白话,但很重要),那么如果记录了从S点到第i个状态的所有k个节点的最短路径,最终的最短路径必然经过其中的一条。这样,在任何时刻,只需要考虑有限条最短路径即可。
3.结合以上两点,假定当我们从i状态进入i+1状态,从S到i状态上各个节点的最短路径已经找到,并且记录在这些节点上,那么计算从起点S到i+1状态的最短路径只要考虑从S到状态i的k个节点的最短路径,以及从这k个节点到xi+1,j的距离即可。
即:

第27章 再谈文本自动分类问题——期望最大化算法
期望最大化算法(简称:EM算法)不能保证一定会收敛到全局最优解,对凸函数可以保证,对不一定是凸函数,一般只能找到局部最优解。

EM算法只需要有一些训练数据,定义一个最大化函数,剩下的事就交给计算机了。经过若干次迭代后,我们的模型就训练好了。简直就是上帝的算法。
第28章 逻辑回归和搜索广告
本章介绍了逻辑回归模型。
第29章 逐个击破算法和Google云计算的基础
分治法:将大问题分为小问题,小问题具有和大问题同样的解决方案。
(大事化小,小事化了)
第30章 Google大脑和人工神经网络
梯度下降法
人工神经网络与贝叶斯网络的关系
分布式
第31章 大数据的威力
本章基本上是科普。
大数据不单单是大量的数据,而且是多维度的全方位的数据,才能叫大数据。
读后感
《数学之美》这本书,科普性质,简单易懂。非常适合刚刚学完基础课程的IT专业大学生阅读,不仅开阔视野,除去学习数学时觉得数学没用的迷茫感,而且能接触到到大师们的思想,学到他们的“道”。
在现在很提倡技“术”的环境下,我很同意吴军老师的观点,“道”才是更重要的。
短短几句表达不出,我读完本书的“通透”感,还是那句话——感兴趣的朋友们,请务必来读一读原书领略数学之美。