微服务架构-实现技术之具体实现工具与框架6:Spring Cloud Hytrix原理与注意事项
目录
一、Spring Cloud Hytrix概述和设计目标
(一)Spring Cloud Hytrix基本概述
(二)Spring Cloud Hytrix概述设计目标
二、Spring Cloud Hytrix解决的主要内容
(一)隔离(线程池隔离和信号量隔离)
1.线程和线程池
线程隔离的好处:
线程隔离的缺点
2.信号量隔离(Semaphores)
(二)优雅的降级机制
(三)熔断
(四)缓存
1.Hystrix缓存策略的命令执行流程
2.请求合并实现
(五)支持实时监控、报警、控制(修改配置)
三、Spring Cloud Hytrix工作流程介绍
四、仪表盘讲解
(一)监控单体应用
(二)Turbine集群监控
五、Spring Cloud Hytrix配置说明
1.Execution相关的属性的配置:
2.Fallback相关的属性
3.Circuit Breaker相关的属性
4.Metrics相关参数
5.Request Context 相关参数
6.Collapser Properties 相关参数
7.ThreadPool 相关参数
六、Spring Cloud Hytrix线程调整和计算
七、Spring Cloud Hytrix源码分析
注:以上所有只做理论性的总结与分析,相关实战代码会在后面的博客中和github中逐步增加。
参考书籍、文献和资料:
注:以上所有只做理论性的总结与分析,相关实战代码会在后面的博客中和github中逐步增加。
一、Spring Cloud Hytrix概述和设计目标
(一)Spring Cloud Hytrix基本概述
在软件架构领域,容错特指容忍并防范局部错误,不让这种局部错误不断扩大。我们在识别风险领域,风险可以分为已知风险和未知风险,容错直接应对的就是已知风险,这就要求针对的场景是:系统之间调用延时超时、线程的数量急剧飙升导致CPU使用率升高、集群服务器磁盘被打满等等。面对容错,我们一般都会要求提供降级方案,而且强调不可进行暴力降级(比如把整个论坛功能降掉直接给用户展现一个大白板),而是将一部分数据缓存起来,也就是要有拖底数据。
在一个分布式系统中,必然会有部分系统的调用会失败。Hystrix是一个通过添加超时容错和失败容错逻辑来帮助你控制这些分布式系统的交互。Hystrix通过隔离服务之间的访问,阻止他们之间的级联故障以及提供后背选项来实现进行丢底方案,从而提高系统的整体弹性。
Hystrix对应的中文名字是“豪猪”,豪猪周身长满了刺,能保护自己不受天敌的伤害,代表了一种防御机制,Hystrix提供了熔断、隔离、Fallback、cache、监控等功能,能够在一个、或多个依赖同时出现问题时保证系统依然可用。
查看Hytrix官网有如下描述:
Introduction:
Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems,
services and 3rd party libraries,
stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.大意是:Hytrix是一个延迟和容错库,旨在隔离远程系统、服务和第三方库,阻止级联故障,在复杂的分布式系统中实现恢复能力。
(二)Spring Cloud Hytrix概述设计目标
查看Hytrix官网https://github.com/Netflix/Hystrix/wiki中对设计目标有如下描述:
Hystrix is designed to do the following:
1.Give protection from and control over latency and failure from dependencies accessed
(typically over the network) via third-party client libraries.
2.Stop cascading failures in a complex distributed system.
3.Fail fast and rapidly recover.
4.Fallback and gracefully degrade when possible.
5.Enable near real-time monitoring, alerting, and operational control.翻译如下:
- 1.通过客户端库对延迟和故障进行保护和控制。
- 2.在一个复杂分布式系统中防止级联故障。
- 3.快速失败和迅速恢复。
- 4.在合理情况下回退和优雅降级。
- 5.开启近实时监控、告警和操作控制。
二、Spring Cloud Hytrix解决的主要内容
(一)隔离(线程池隔离和信号量隔离)
在微服务架构中,要求服务的容错隔离,以及对应的回退降级限流方案理论,我们在以下博客中已经初步提到:
https://blog.csdn.net/xiaofeng10330111/article/details/86772740.
隔离的基本要求是:限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用。Spring Cloud Hytrix下针对隔离主要指的是线程池隔离和信号量隔离。如下图所示,可以很明显的说明信号量隔离和线程池隔离的主要区别:线程池方式下,业务请求线程和执行依赖的服务线程不是同一个线程;信号量方式下业务请求线程和执行依赖的线程是同一个线程。
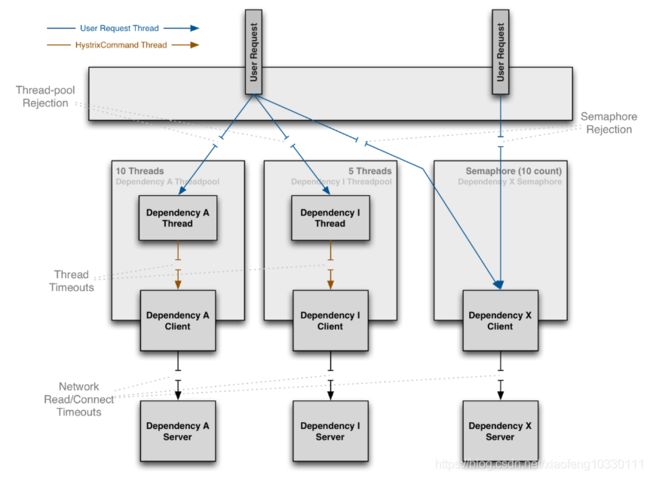
1.线程和线程池
线程隔离指每个服务都为一个个独立的线程组,当某个服务出现问题时,不会导致整个服务瘫痪。由于线程隔离会带来线程开销,有些场景(比如无网络请求场景)可能会因为用开销换隔离得不偿失,为此hystrix提供了信号量隔离,当服务的并发数大于信号量阈值时将进入fallback。
如下图,客户端(第三方,网络调用等)依赖和请求线程运行在不同的线程上,可以将他们从调用线程隔离开来,这样调用者就可以从一个耗时太长的依赖中隔离,也可以为不同的请求开启不同的线程池,彼此之间不相互干扰。
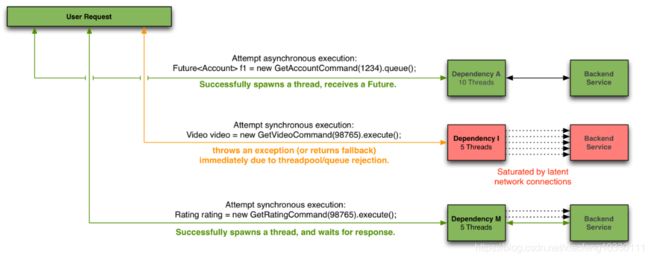
传统上,我们在实现线程池隔离的手段上,一般有以下两种方式:
- 方式一:使用一个大的线程池,固定线程池的大小,比如1000,通过权重的思路为某个方法分配一个固定大小的线程数,比如为某个方法请求分配了10个线程,按照实现方式有“保守型”和“限制性”,具体见以后博客中和github中的代码举例。
- 方式二:利用ConcurrentHashMap来存储线程池,key是方法名,值是每个方法对应的一个ThreadPool。当请求到来的时候,我们获取方法名,然后直接从Map对象中取到响应的线程池去处理。
对于方法一而言,严格意义上讲,它并不属于线程池隔离,因为它只有一个公共的线程池,然后来让大家瓜分,不过也达到了隔离的效果。在Spring Cloud Hytrix的线程池隔离上,我们使用的是方式二。对于以上两种方式,线程池的粒度都是作用在方法上,我们可以结合实际情况也可以按组来分。
线程隔离的好处
整个应用在客户端调用失效的情况下也能健康的运行,线程池能够保证这个线程的失效不会影响应用的运行。当失效的客户端调用回复的时候,这个线程池也会被清理并且应用会立马回复健康,比tomcat那种长时间的恢复要好很多。简而言之,线程隔离能够允许在不引起中断的情况下优雅的处理第三方调用的各种问题。
线程隔离的缺点
主要缺点是增加了上下文切换的开销,每个执行都涉及到队列,调度和上下文切换。不过NetFix在设计这个系统的时候,已经决定接受这笔开销,以换取他的好处。对于不依赖网络访问的服务,比如只依赖内存缓存,就不适合用线程池隔离技术,而是采用信号量隔离。
2.信号量隔离(Semaphores)
可以使用信号量(或者计数器)来限制当前依赖调用的并发数,而不是使用线程池或者队列。如果客户端是可信的,且能快速返回,可以使用信号量来代替线程隔离,降低开销。信号量的大小可以动态调节,线程池却不行。
HystrixCommand和HystrixObserverCommand提供信号量隔离在下面两个地方:
- Fallback:当Hystrix检索fallback的时候,他心总是调用tomcat线程上执行此操作
- 如果你设置execution.isolation.strategy为SEMAPHORE的时候,Hystrix会使用信号量代替线程池去限制当前调用Command的并发数。
对于不依赖网络访问的服务,就不适合使用线程池隔离,而是采用信号量隔离。
(二)优雅的降级机制
超时降级、资源不足时(线程或信号量)降级,降级总之是一种退而求其次的方式,所谓降级,就是指在Hystrix执行费核心链路功能失败的情况下,我们应该如何返回的问题,根据业务场景的不同,一般采用以下两种模式进行降级:
- 第一种:(最常用)如果服务失败,则我们通过fallback进行降级,返回静态值。
- 第二种:调用备选方案
降级会退的方案有很多,以上只是初步的建议,具体降级回退方案如:Fail Fast(快速失败)、Fail Silent(无声失败)、Fallback:Static(返回默认值)、Fallback:Stubbed(自己组装一个值返回)、Fallback:Cache via Network(利用远程缓存)、Primary + Secondary with fallback(主次方式回退),其基本的实现在相关功能由介绍,建议进行扩展学习。
这里需要注意回退处理方式不适合的场景,如以下三种场景我们不可以使用回退处理:
- 写操作
- 批处理
- 计算
(三)熔断器
当失败率达到阀值自动触发降级(如因网络故障/超时造成的失败率高),熔断器触发的快速失败会进行快速恢复,类似于电闸。下图是基本源码中的一个处理流程图:
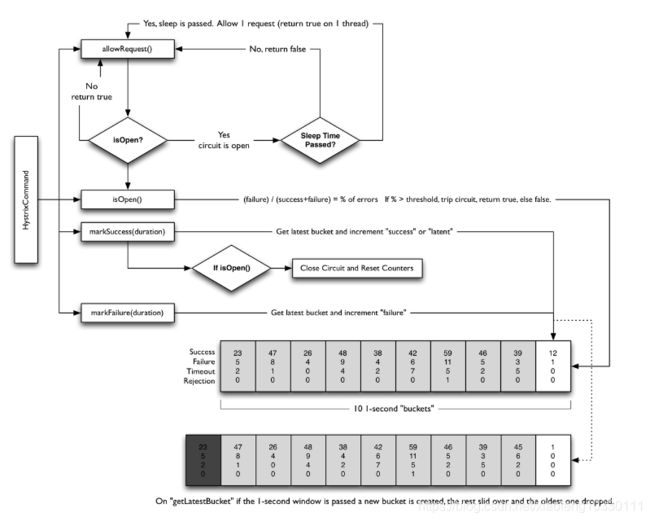
断路器打开还是关闭的步骤如下
- 1.假定请求的量超过预定的阈值(circuitBreakerRequestVolumeThreshold)
- 2.再假定错误百分比超过了设定的百分比(circuitBreakerErrorThresholdPercentage)
- 3.断路器会从close状态到open状态
- 4.当打开的状态,会短路所有针对该断路器的请求
- 5.过了一定时间(circuitBreakerSleepWindowInMilliseconds(短路超过一定时间会重新去请求)),下一个请求将通过,不会被短路(当前是half-open状态)。如果这个请求失败了,则断路器在睡眠窗口期间返回open状态,如果请求成功,则断路器返回close状态,并重新回到第一步逻辑判断。
(四)缓存
提供了请求缓存、请求合并实现。
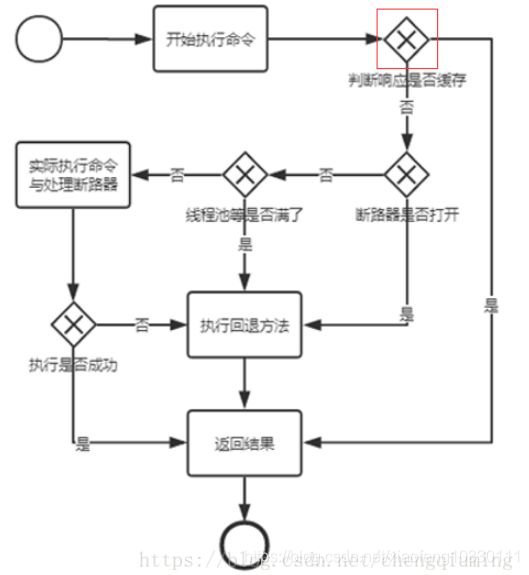
1.Hystrix缓存策略的命令执行流程
2.请求合并实现
为什么要进行请求合并?举个例子,有个矿山,每过一段时间都会生产一批矿产出来(质量为卡车载重量的1/100),卡车可以一等到矿产生产出来就马上运走矿产,也可以等到卡车装满再运走矿产,
前者一次生产对应卡车一次往返,卡车需要往返100次,而后者只需要往返一次,可以大大减少卡车往返次数。显而易见,利用请求合并可以减少线程和网络连接,开发人员不必单独提供一个批量请求接口就可以完成批量请求。
在Hystrix中进行请求合并也是要付出一定代价的,请求合并会导致依赖服务的请求延迟增高,延迟的最大值是合并时间窗口的大小,默认为10ms,当然我们也可以通过hystrix.collapser.default.timerDelayInMilliseconds属性进行修改,如果请求一次依赖服务的平均响应时间是20ms,那么最坏情况下(合并窗口开始是请求加入等待队列)这次请求响应时间就会变成30ms。在Hystrix中对请求进行合并是否值得主要取决于Command本身,高并发度的接口通过请求合并可以极大提高系统吞吐量,从而基本可以忽略合并时间窗口的开销,反之,并发量较低,对延迟敏感的接口不建议使用请求合并。
请求合并的流程图如下:
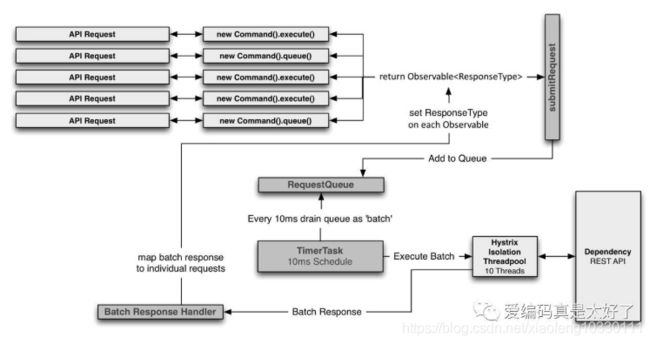
可以看出Hystrix会把多个Command放入Request队列中,一旦满足合并时间窗口周期大小,Hystrix会进行一次批量提交,进行一次依赖服务的调用,通过充写HystrixCollapser父类的mapResponseToRequests方法,将批量返回的请求分发到具体的每次请求中。
(五)支持实时监控、报警、控制(修改配置)
通过仪表盘等进行统计后,从而进行实时监控、报警、控制,最终依据这些来修改配置,得到最佳的选择。
三、Spring Cloud Hytrix工作流程介绍
基本流程图如下:
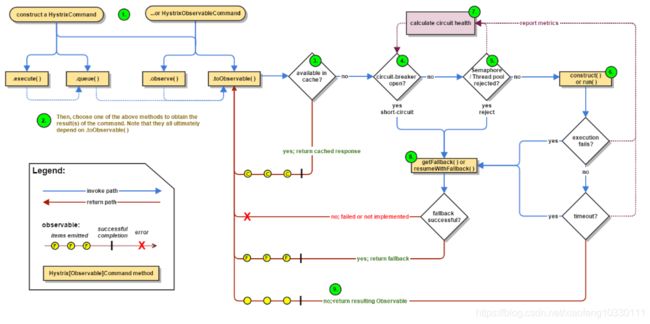
1.创建HystrixCommand或者HystrixObservableCommand对象。用来表示对以来服务的请求操作。从命名就能看的出来,使用的是命令模式,其中HystrixCommand返回的是单个操作结果,HystrixObservableCommand返回多个结果
2.命令执行,共有4中方法执行命令:
- execute():用户执行,从依赖的服务里返回单个结果或抛出异常
- queue():异步执行,直接返回一个Future对象
- observe():放回observable对象,代表了多个结果,是一个Hot Observable
- toObservable():返回Observable对象,但是是一个 Cold Observable(Hystrix大量的使用了RxJava,想更容易的理解Hystrix的,请自行百度RxJava进行阅读。)
3.结果是否被缓存。如果已经启用了缓存功能,且被命中,那么缓存就会直接以Observable对象返回
4.断路器是否已打开,没有命中缓存,在执行命令前会检查断路器是否已打开:
- 断路器已打开,直接执行fallback
- 断路器关闭,继续往下执行
5.线程池And信号量Or请求队列是否已被占满 如果与该命令有关的线程池和请求队列,或者信号量已经被占满,就直接执行fallback
6.执行HystrixObservableCommand.construct () 或 HystrixCommand.run() 方法。如果设置了当前执行时间超过了设置的timeout,则当前处理线程会抛出一个TimeoutyException,如果命令不在自身线程里执行,就会通过单独的计时线程来抛出异常,Hystrix会直接执行fallback逻辑,并忽略run或construct的返回值。
7.计算断路器的健康值。
8.fallback处理。
9.返回成功的响应。
四、仪表盘讲解
Spring Cloud Hystrix Dashboard是一个可以监控HystrixCommand的可视化图形界面,由于某种原因,如网络延迟、服务故障等,这时候可以借助dashboard提供的可视化界面监控各个Hystrix执行的成功率、调用成功数、失败数量、最近十分钟的流量图等等,根据这些数据我们就可以进行错误排查以及进行服务的优化等。Hystrix Dashboard只能对单个服务进行监控,实际项目中,服务通常集群部署,这时候可以借助Turbine进行多个服务的监控。
(一)监控单体应用
不管是监控单体应用还是Turbine集群监控,我们都需要一个Hystrix Dashboard,当然我们可以在要监控的单体应用上继续添加功能,让它也具备仪表盘的功能,但是这样并不符合我们微服务的思想,所以,Hystrix仪表盘我还是单独创建一个新的工程专门用来做Hystrix Dashboard。Hystrix Dashboard仪表盘是根据系统一段时间内发生的请求情况来展示的可视化面板,这些信息时每个HystrixCommand执行过程中的信息,这些信息是一个指标集合和具体的系统运行情况。如Hystrix Dashboard界面图:
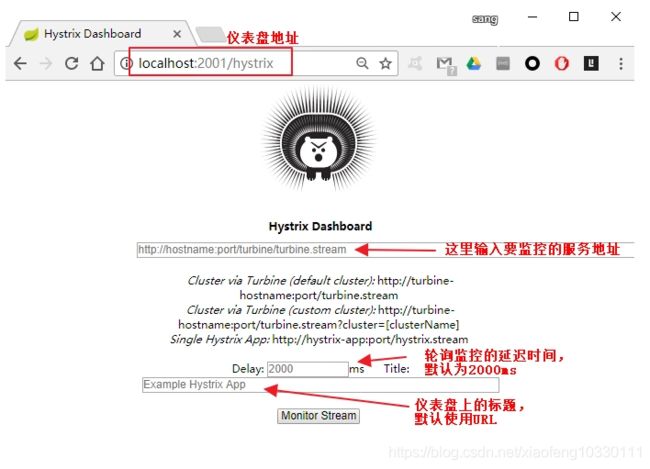
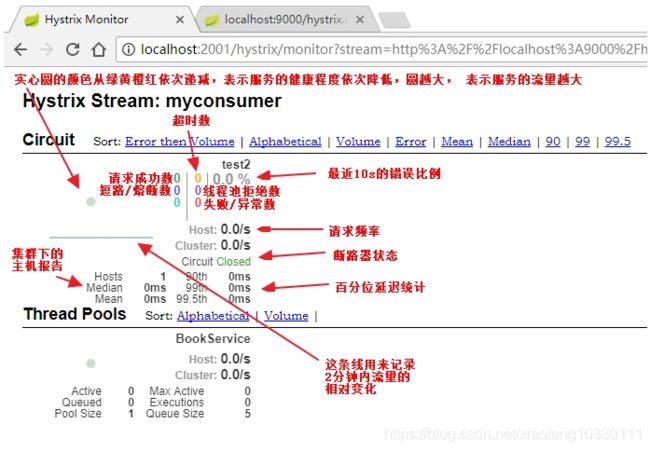
输入相关数据,得到如下仪表盘:
(二)Turbine集群监控
在实际应用中,我们要监控的应用往往是一个集群,这个时候我们就得采取Turbine集群监控了。Turbine有一个重要的功能就是汇聚监控信息,并将汇聚到的监控信息提供给Hystrix Dashboard来集中展示和监控。
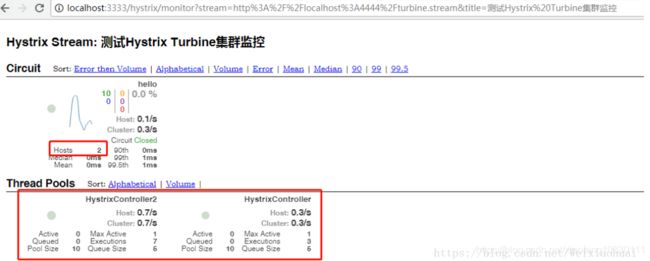
在实际项目中,这种实时监控有点耗性能,通常采用消息中间件如RabbitMQ等,我们接口调用把Hystrix的一些信息收集到RabbitMQ中,然后Turbine从RabbitMQ中获取监控的数据。
五、Spring Cloud Hytrix配置说明
以下的属性都是spring cloud 1.5.9版本的。
1.Execution相关的属性的配置:
-
hystrix.command.default.execution.isolation.strategy 隔离策略,默认是Thread, 可选Thread|Semaphore
-
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds 命令执行超时时间,默认1000ms
- hystrix.command.default.execution.timeout.enabled 执行是否启用超时,默认启用true
- hystrix.command.default.execution.isolation.thread.interruptOnTimeout 发生超时是是否中断,默认true
- hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests 最大并发请求数,默认10,该参数当使用ExecutionIsolationStrategy.SEMAPHORE策略时才有效。如果达到最大并发请求数,请求会被拒绝。理论上选择semaphore size的原则和选择thread size一致,但选用semaphore时每次执行的单元要比较小且执行速度快(ms级别),否则的话应该用thread。
semaphore应该占整个容器(tomcat)的线程池的一小部分。
2.Fallback相关的属性
这些参数可以应用于Hystrix的THREAD和SEMAPHORE策略
- hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests 如果并发数达到该设置值,请求会被拒绝和抛出异常并且fallback不会被调用。默认10
- hystrix.command.default.fallback.enabled 当执行失败或者请求被拒绝,是否会尝试调用hystrixCommand.getFallback() 。默认true
3.Circuit Breaker相关的属性
- hystrix.command.default.circuitBreaker.enabled 用来跟踪circuit的健康性,如果未达标则让request短路。默认true。
- hystrix.command.default.circuitBreaker.requestVolumeThreshold 一个rolling window内最小的请求数。如果设为20,那么当一个rolling window的时间内(比如说1个rolling window是10秒)收到19个请求,即使19个请求都失败,也不会触发circuit break。默认20。这个参数非常重要,熔断器是否打开首先要满足这个条件。
- hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds 触发短路的时间值,当该值设为5000时,则当触发circuit break后的5000毫秒内都会拒绝request,也就是5000毫秒后才会关闭circuit。默认5000
- hystrix.command.default.circuitBreaker.errorThresholdPercentage错误比率阀值,如果错误率>=该值,circuit会被打开,并短路所有请求触发fallback。默认50
- hystrix.command.default.circuitBreaker.forceOpen 强制打开熔断器,如果打开这个开关,那么拒绝所有request,默认false
- hystrix.command.default.circuitBreaker.forceClosed 强制关闭熔断器 如果这个开关打开,circuit将一直关闭且忽略circuitBreaker.errorThresholdPercentage
4.Metrics相关参数
- hystrix.command.default.metrics.rollingStats.timeInMilliseconds 设置统计的时间窗口值的,毫秒值,circuit break 的打开会根据1个rolling window的统计来计算。若rolling window被设为10000毫秒,则rolling window会被分成n个buckets,每个bucket包含success,failure,timeout,rejection的次数的统计信息。默认10000
- hystrix.command.default.metrics.rollingStats.numBuckets 设置一个rolling window被划分的数量,若numBuckets=10,rolling window=10000,那么一个bucket的时间即1秒。必须符合rolling window % numberBuckets == 0。默认10
- hystrix.command.default.metrics.rollingPercentile.enabled 执行时是否enable指标的计算和跟踪,默认true
- hystrix.command.default.metrics.rollingPercentile.timeInMilliseconds 设置rolling percentile window的时间,默认60000
- hystrix.command.default.metrics.rollingPercentile.numBuckets 设置rolling percentile window的numberBuckets。逻辑同上。默认6
- hystrix.command.default.metrics.rollingPercentile.bucketSize 如果bucket size=100,window=10s,若这10s里有500次执行,只有最后100次执行会被统计到bucket里去。增加该值会增加内存开销以及排序的开销。默认100
- hystrix.command.default.metrics.healthSnapshot.intervalInMilliseconds 记录health 快照(用来统计成功和错误绿)的间隔,默认500ms
5.Request Context 相关参数
hystrix.command.default.requestCache.enabled 默认true,需要重载getCacheKey(),返回null时不缓存
hystrix.command.default.requestLog.enabled 记录日志到HystrixRequestLog,默认true
6.Collapser Properties 相关参数
hystrix.collapser.default.maxRequestsInBatch 单次批处理的最大请求数,达到该数量触发批处理,默认Integer.MAX_VALUE
hystrix.collapser.default.timerDelayInMilliseconds 触发批处理的延迟,也可以为创建批处理的时间+该值,默认10
hystrix.collapser.default.requestCache.enabled 是否对HystrixCollapser.execute() and HystrixCollapser.queue()的cache,默认true
7.ThreadPool 相关参数
线程数默认值10适用于大部分情况(有时可以设置得更小),如果需要设置得更大,那有个基本得公式可以follow:
requests per second at peak when healthy × 99th percentile latency in seconds + some breathing room
每秒最大支撑的请求数 (99%平均响应时间 + 缓存值)
比如:每秒能处理1000个请求,99%的请求响应时间是60ms,那么公式是:
1000 (0.060+0.012)
基本得原则时保持线程池尽可能小,他主要是为了释放压力,防止资源被阻塞。
当一切都是正常的时候,线程池一般仅会有1到2个线程激活来提供服务
- hystrix.threadpool.default.coreSize 并发执行的最大线程数,默认10
- hystrix.threadpool.default.maxQueueSize BlockingQueue的最大队列数,当设为-1,会使用SynchronousQueue,值为正时使用LinkedBlcokingQueue。该设置只会在初始化时有效,之后不能修改threadpool的queue size,除非reinitialising thread executor。默认-1。
- hystrix.threadpool.default.queueSizeRejectionThreshold 即使maxQueueSize没有达到,达到queueSizeRejectionThreshold该值后,请求也会被拒绝。因为maxQueueSize不能被动态修改,这个参数将允许我们动态设置该值。if maxQueueSize == -1,该字段将不起作用
- hystrix.threadpool.default.keepAliveTimeMinutes 如果corePoolSize和maxPoolSize设成一样(默认实现)该设置无效。如果通过plugin(https://github.com/Netflix/Hystrix/wiki/Plugins)使用自定义实现,该设置才有用,默认1.
- hystrix.threadpool.default.metrics.rollingStats.timeInMilliseconds 线程池统计指标的时间,默认10000
- hystrix.threadpool.default.metrics.rollingStats.numBuckets 将rolling window划分为n个buckets,默认10
六、Spring Cloud Hytrix线程调整和计算
在实际使用过程中会涉及多个微服务,可能有些微服务使用的线程池过大,有些服务使用的线程池小,有些服务的超时时间长,有的短,所以Hystrix官方也提供了一些方法供我们来计算和调整这些配置,总的宗旨是,通过自我预判的配置先发布到生产或测试,然后查看它具体的运行情况,在调整为更符合业务的配置,通常做法有:
1.超过时间默认为1000ms,如果业务明显超过1000ms,则根据自己的业务进行修改。
2.线程池默认10,如果知道确实要使用更多时可以调整。
3.金丝雀发布,如果成功则保持。
4.在生产环境中运行超过24小时。
5.如果系统有告警和监控,那么可以依靠他们捕捉问题。
6.运行24小时后,通过延时百分位和流量来计算有意义的最低满足值。
7.在生产或测试环境中实时修改值,然后用仪表盘监控。
8.如果断路器产生变化和影响,则需要再次确认这个配置。
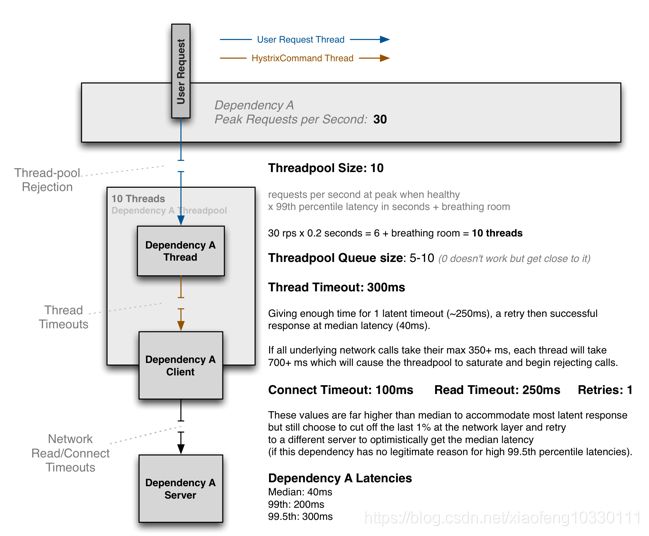
官方例子如图,Threadpool的大小为10,如下计算公式:
每秒请求的峰值 X 99%的延迟百分比(请求响应的时间)+ 预留缓存的值
即 30 x 0.2s = 6 + 预留缓存的值 = 10 ,这里预留了4个线程数。
Thread Timeout:预留了一个足够的时间,250ms,然后加上重试一次的中位数值。
Connect Timeout & Read Timeout:100ms和250ms,这两个值的设置方法远高于中位数值,以适应大多数请求。
在实际的生产测试过程中,配置每个服务时可以根据官方推荐的这些方法来测试自己的业务需要的数值,这样产生最合适的配置。
七、Spring Cloud Hytrix源码分析
Spring Cloud Hystrix的使用:
- 1.启动类添加@EnableHystrix注解。
- 2.方法上添加@HystrixCommand注解,并指定fallback的方法。
查看@EnableHystrix注解
/**
* Convenience annotation for clients to enable Hystrix circuit breakers (specifically).
* Use this (optionally) in case you want discovery and know for sure that it is Hystrix
* you want. All it does is turn on circuit breakers and let the autoconfiguration find
* the Hystrix classes if they are available (i.e. you need Hystrix on the classpath as
* well).
*
* @author Dave Syer
* @author Spencer Gibb
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@EnableCircuitBreaker
public @interface EnableHystrix {
}这个注解的功能就是开启Hystrix。这个注解还引入了@EnableCircuitBreaker注解。
在代码同一级目录下,还可以看到两个配置类:HystrixAutoConfiguration和HystrixCircuitBreakerConfiguration。
下面是HystrixAutoConfiguration配置类的配置:
@Configuration
@ConditionalOnClass({ Hystrix.class, HealthIndicator.class })
@AutoConfigureAfter({ HealthIndicatorAutoConfiguration.class })
public class HystrixAutoConfiguration {
@Bean
@ConditionalOnEnabledHealthIndicator("hystrix")
public HystrixHealthIndicator hystrixHealthIndicator() {
return new HystrixHealthIndicator();
}
}从代码中可以看到,HystrixAutoConfiguration这个配置类主要是hystrix的健康检查的配置。再看下HystrixCircuitBreakerConfiguration这个类,这个类里面就配置了很多内容。
@Bean
public HystrixCommandAspect hystrixCommandAspect() {
return new HystrixCommandAspect();
}这里返回了HystrixCommandAspect的bean,这个切面中定义了Pointcut:
@Pointcut("@annotation(com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand)")
public void hystrixCommandAnnotationPointcut() {
}
@Pointcut("@annotation(com.netflix.hystrix.contrib.javanica.annotation.HystrixCollapser)")
public void hystrixCollapserAnnotationPointcut() {
}所以,这个Aspect就是利用AOP切面对 HystrixCommand 、 HystrixCollapser 两种注解的方法进行扩展处理。
我们在方法上添加@HystrixCommand注解,就会经过这个切面,这个切面中定义了@Around(…)拦截所有请求。
下面看下这个方法:
@Around("hystrixCommandAnnotationPointcut() || hystrixCollapserAnnotationPointcut()")
public Object methodsAnnotatedWithHystrixCommand(final ProceedingJoinPoint joinPoint) throws Throwable {
Method method = getMethodFromTarget(joinPoint);
Validate.notNull(method, "failed to get method from joinPoint: %s", joinPoint);
if (method.isAnnotationPresent(HystrixCommand.class) && method.isAnnotationPresent(HystrixCollapser.class)) {
throw new IllegalStateException("method cannot be annotated with HystrixCommand and HystrixCollapser " +
"annotations at the same time");
}
MetaHolderFactory metaHolderFactory = META_HOLDER_FACTORY_MAP.get(HystrixPointcutType.of(method));
MetaHolder metaHolder = metaHolderFactory.create(joinPoint);
HystrixInvokable invokable = HystrixCommandFactory.getInstance().create(metaHolder);
ExecutionType executionType = metaHolder.isCollapserAnnotationPresent() ?
metaHolder.getCollapserExecutionType() : metaHolder.getExecutionType();
Object result;
try {
result = CommandExecutor.execute(invokable, executionType, metaHolder);
} catch (HystrixBadRequestException e) {
throw e.getCause();
}
return result;
}这个方法中,一开始先获取拦截的Method,然后判断,如果方法上同时加了@HystrixCommand和@HystrixCollapser两个注解的话,就抛异常。
在创建MetaHolder的时候,调用了MetaHolderFactory的create方法,MetaHolderFactory有两个子类,CollapserMetaHolderFactory和CommandMetaHolderFactory,最终执行的是子类的create方法,下面是CommandMetaHolderFactory中的create方法:
private static class CommandMetaHolderFactory extends MetaHolderFactory {
@Override
public MetaHolder create(Object proxy, Method method, Object obj, Object[] args, final ProceedingJoinPoint joinPoint) {
HystrixCommand hystrixCommand = method.getAnnotation(HystrixCommand.class);
ExecutionType executionType = ExecutionType.getExecutionType(method.getReturnType());
MetaHolder.Builder builder = metaHolderBuilder(proxy, method, obj, args, joinPoint);
return builder.defaultCommandKey(method.getName())
.hystrixCommand(hystrixCommand)
.observableExecutionMode(hystrixCommand.observableExecutionMode())
.executionType(executionType)
.observable(ExecutionType.OBSERVABLE == executionType)
.build();
}
}MetaHolder.Builder metaHolderBuilder(Object proxy, Method method, Object obj, Object[] args, final ProceedingJoinPoint joinPoint) {
MetaHolder.Builder builder = MetaHolder.builder()
.args(args).method(method).obj(obj).proxyObj(proxy)
.defaultGroupKey(obj.getClass().getSimpleName())
.joinPoint(joinPoint);
if (isCompileWeaving()) {
builder.ajcMethod(getAjcMethodFromTarget(joinPoint));
}
FallbackMethod fallbackMethod = MethodProvider.getInstance().getFallbackMethod(obj.getClass(), method);
if (fallbackMethod.isPresent()) {
fallbackMethod.validateReturnType(method);
builder
.fallbackMethod(fallbackMethod.getMethod())
.fallbackExecutionType(ExecutionType.getExecutionType(fallbackMethod.getMethod().getReturnType()));
}
return builder;
}在创建MetaHolder的过程中,就会指定fallback方法。
创建完MetaHolder之后,就会根据MetaHolder创建HystrixInvokable。
public HystrixInvokable create(MetaHolder metaHolder) {
HystrixInvokable executable;
if (metaHolder.isCollapserAnnotationPresent()) {
executable = new CommandCollapser(metaHolder);
} else if (metaHolder.isObservable()) {
executable = new GenericObservableCommand(HystrixCommandBuilderFactory.getInstance().create(metaHolder));
} else {
executable = new GenericCommand(HystrixCommandBuilderFactory.getInstance().create(metaHolder));
}
return executable;
}这段代码里定义了后续真正执行HystrixCommand的GenericCommand实例
方法最终会去执行CommandExecutor.execute方法:
public static Object execute(HystrixInvokable invokable, ExecutionType executionType, MetaHolder metaHolder) throws RuntimeException {
Validate.notNull(invokable);
Validate.notNull(metaHolder);
switch (executionType) {
case SYNCHRONOUS: {
return castToExecutable(invokable, executionType).execute();
}
case ASYNCHRONOUS: {
HystrixExecutable executable = castToExecutable(invokable, executionType);
if (metaHolder.hasFallbackMethodCommand()
&& ExecutionType.ASYNCHRONOUS == metaHolder.getFallbackExecutionType()) {
return new FutureDecorator(executable.queue());
}
return executable.queue();
}
case OBSERVABLE: {
HystrixObservable observable = castToObservable(invokable);
return ObservableExecutionMode.EAGER == metaHolder.getObservableExecutionMode() ? observable.observe() : observable.toObservable();
}
default:
throw new RuntimeException("unsupported execution type: " + executionType);
}
}这里会分成同步和异步的场景,进入execute方法看下:
/**
* Used for synchronous execution of command.
*
* @return R
* Result of {@link #run()} execution or a fallback from {@link #getFallback()} if the command fails for any reason.
* @throws HystrixRuntimeException
* if a failure occurs and a fallback cannot be retrieved
* @throws HystrixBadRequestException
* if invalid arguments or state were used representing a user failure, not a system failure
* @throws IllegalStateException
* if invoked more than once
*/
public R execute() {
try {
return queue().get();
} catch (Exception e) {
throw decomposeException(e);
}
}这个方法的注释中说明了返回值,可以返回请求的结果,当失败的时候,则会通过getFallback()方法来执行一个回退操作,由于是GenericCommand实例,那就看下这个实例中的getFallback()方法:
@Override
protected Object getFallback() {
if (getFallbackAction() != null) {
final CommandAction commandAction = getFallbackAction();
try {
return process(new Action() {
@Override
Object execute() {
MetaHolder metaHolder = commandAction.getMetaHolder();
Object[] args = createArgsForFallback(metaHolder, getExecutionException());
return commandAction.executeWithArgs(commandAction.getMetaHolder().getFallbackExecutionType(), args);
}
});
} catch (Throwable e) {
LOGGER.error(FallbackErrorMessageBuilder.create()
.append(commandAction, e).build());
throw new FallbackInvocationException(e.getCause());
}
} else {
return super.getFallback();
}
}大体的一个流程也就知道了,就是通过HystrixCommandAspect,请求成功返回接口的结果,请求失败执行fallback的逻辑。
参考书籍、文献和资料:
【1】徐进,叶志远,钟尊发,蔡波斯等. 重新定义Spring Cloud. 北京:机械工业出版社. 2018.
【2】郑天民. 微服务设计原理与架构. 北京:人民邮电出版社,2018.
【3】王新栋.架构修炼之道.北京:电子工业出版社,2019.
【4】https://blog.csdn.net/hzq472583006/article/details/81110443.
【5】https://www.cnblogs.com/niechen/p/8513597.html.
【6】https://blog.csdn.net/lij231/article/details/82956455.
【7】https://blog.csdn.net/chayangdz/article/details/82561158.
【8】https://segmentfault.com/a/1190000011478978?utm_source=tag-newest.
【9】https://blog.csdn.net/Weixiaohuai/article/details/82699125.
【10】https://www.cnblogs.com/huangjuncong/p/9043844.html.
【11】https://blog.csdn.net/chengqiuming/article/details/81151734.
【12】https://www.cnblogs.com/huangjuncong/p/9043844.html.