TokenScope: Automatically Detecting Inconsistent Behaviors of Cryptocurrency Tokens in Ethereum 论文笔记
今天我要分享的这篇文章来自CCS 2019,叫做TokenScope,主要是自动化检测了以太坊上实现的加密货币与ERC20标准不一致的行为,第一作者是电子科大的陈厅老师。
首先讲一下Introduction和background,现在大部分的加密货币很少会有原生资产(Native Assests),就像比特币那样,部署在一条属于自己的公链上,基本上都是通过智能合约的形式部署在以太坊上。因为这样的合约越来越多,所以也就提出了相关的规范标准,来约束这类合约的实现。用户通常也会采用一些第三方工具来操作这些货币,比如用钱包来转账,使用交易市场来买卖货币,以及用一些explorer来检查交易,而这些工具与货币合约进行交互很多都是通过刚说的那些标准所提供的接口和event。

然后在这些标准中,最出名和最流行的叫做ERC20,它定义了六个接口和两个event,举个例子比如transferFrom这个函数,可以看红色标出来的,ERC20要求从地址from转价值为value的货币到地址to,另外ERC20还要求每当货币被转移的时候都要发送一个名为transfer的event,不论是标准里边定义的方法还是自己实现的方法都需要发送。
 背景介绍
背景介绍
如果这些加密货币的合约所实现的标准方法与要求的不一致,那么第三方工具将会无法和这个合约进行正确的交互,甚至没有办法识别出合约里的货币。然后现有的工作几乎很少关注这种不一致性,本文是第一个来检测这种不一致行为的工作。
为了检测这种不一致行为,有两个主要的challenge:
第一是如何自动化地识别出保存了货币持有者身份和余额的数据结构,其实就是一个map;
第二个challenge是如何识别通过跨合约调用所触发的货币转移行为。
为了解决这些challenge,作者提出了一个基于trace的方法,这个方法利用了区块链的一个特点,就是所有智能合约的执行记录都是会被保存在链上,这些记录是公开透明的。然后这个方法主要有三个步骤,我先简要介绍一下:
第一步是通过插桩本地的以太坊节点程序来获取执行的trace;
第二步是定位保存了余额的核心数据结构,然后识别出来操作这个数据结构的行为;
第三步是收集货币合约所实现的标准方法的相关交易行为,进行一个不一致性的对比;
 本文的总体方法
本文的总体方法
下面介绍一个不一致的例子,可以看一下下边这个图里的合约代码。第2,3,5,7,12行分别对数据进行了直接的相加操作,没有用SafeMath的相关函数来避免整数溢出的问题,这可能会导致第4、6行所发送的event所包含的交易金额与实际金额不同,因为可以构造_feeUgt和value数值来溢出,然后实际上from地址只要存一小笔钱就可以取出一大笔钱到地址to,这和第四行的transfer event所记录的行为不一致。第10行是一个fake deposit的问题,因为这里会返回false,而实际上transfer应该是给to这个地址转value个货币,因此与定义不符,也是不一致的行为。最后12行一方面会有整数溢出的问题,另一方面它有一个转账行为,但是漏掉了发送transfer event,也是不一致问题。
 Motivating Example
Motivating Example
然后对于这个例子,先来简要介绍一下它的解决流程:首先会去定位出这个保存货币持有者信息的核心数据结构,就是balance这个变量,然后监控对这个变量的修改,就在3、5、7行来获取真实的货币行为,另外还会检测通过event来获取的合约行为,就是第4、6行代码,最后会比较这两个地方拿到的行为信息,然后来对比检测是否有不一致。
下图是接下来介绍工作中要用到的一些记号:

然后来介绍一下什么是inconsitency,主要有两种不一致的情况,首先说一下Bm,Be和Br分别为空的意思,如果Bm为空就是说要么外部交易没有调用过ERC20标准方法,如果Be为空,就说明合约的执行过程没有发送过标准event,如果Br为空说明合约没有修改过M。那么当交易调用了一个ERC20标准方法时,inconsistency就是指Bm,Be和Br不匹配。如果调用的并不是ERC20的标准方法,那就是Be和Br不匹配。
下图是一个工具的整体结构流程图,可以看到一共有三个Stage:
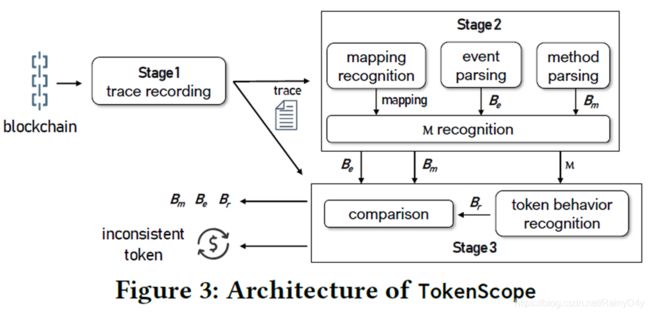 Overall Architecture
Overall Architecture
Stage 1是用来记录trace的,一个trace是指合约的执行记录,这里需要注意的是,一个外部交易可能会通过触发合约执行,产生一些内部交易调用了别的合约。然后每一条trace包含了四个部分,分别是外部交易的哈希、交易的receiver、交易携带的数据(指定的调用方法和参数)以及这个过程中所包含的EVM所有按顺序执行的操作,实际上也就是EVM字节码。
现在讲一下它的stage 1是怎么做的,TokenScope通过插桩以太坊节点来获取trace,在本地节点同步主链区块的时候可以拿到这些信息,另外作者没有采用EVM自带的API,因为那个速度太慢了。然后作者在这两个地方进行插桩,一个是对于外部交易,在ApplyTransaction这个函数插桩,对于内部交易则在CALL、CALLCODE、DELEGATECALL和STATICCALL这四个函数的handler进行插桩,在这两个地方插桩后可以在它们的参数里拿到trace的前三个信息,对于第四个信息就是要执行的EVM字节码,作者则在每一个EVM解释执行字节码的handler进行了插桩。
然后Stage 2是定位刚刚说的那个保存货币持有者信息的数据结构M,这一步同时也可以拿到Bm和Be,可以看一下这幅图上的伪代码,输入是trace,然后输出是M,Bm和Be。
 识别M的伪代码
识别M的伪代码
然后看这个图可以看到它有四个步骤,先简单介绍一下这个伪代码的四个步骤,步骤一是首先会定位到合约中所有的mapping变量,然后步骤二和步骤三会从trace的信息中提取出来有哪些ERC20定义的标准方法和event被调用,第四步就是排除不相关的map变量,这一步主要是去看Bm和Be中涉及到的转账行为相关的mapping变量是哪个,然后这个就是要获取的M。
现在来详细介绍一下Stage 2的四个步骤,然后第一步是定位mapping变量,在没有合约源码的情况下,这是一个challenge,因为在字节码中没有明显的map变量信息。然后作者的一个动机就是根据操作mapping变量的字节码行为来识别,然后要注意的是所有的mapping变量都会被保存在Storage中,与之相关的字节码是SLOAD和SSTORE来读写,然后作者从16248个有源码的合约中总结了四种类型的mapping变量以及他们的字节码读写pattern来识别。
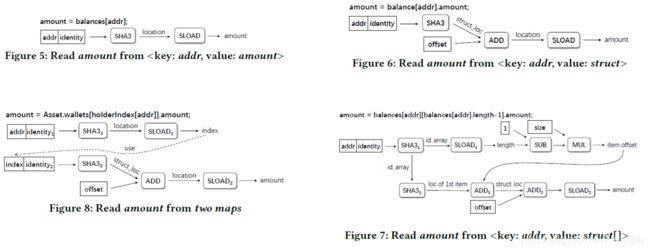 四种Map操作的字节码Pattern
四种Map操作的字节码Pattern
接下来第二步是从合约中parse出标准方法的信息,这里以transfer函数为例,它的意思是向地址_to转价值为value的token,然后会产生两个tuple分别是
然后是第三步,从合约中parse出标准Event,首先会去查找所有的LOGGING相关的字节码,然后这个字节码会首先读取一个32 byte的数,它表示了event ID,然后通过event ID来识别出标准event,接着在log函数的第4-6个参数可以拿到剩余的构造tuple所需要的信息。
Step 4是识别核心数据结构M,因为一个合约中可能会含有很多Mapping类型的变量,这里作者的一个想法是通过联系mapping类型变量和标准方法与event来完成这件事,如果修改一个mapping类型变量涉及到的参数是来自于ERC20的标准方法与event的参数,那么就认为它是M,比如下面这串代码的第十行可以得到balances是M,而修改另一个mappnig变量的victim则不是,比如第12行代码可以看出来。
然后Stage 3是检测不一致的行为,这里主要分为两步,第一步是通过监控对M的读写识别真实的token行为,第二步是比较BmBe和Br,伪代码如下图所示:

Br也是由一堆tuple构成的,识别过程和stage 2的第一步很类似,因为也是通过字节码特征对map变量读写进行识别,首先第一步会找到所有与M相关的SHA3操作,这里会拿到访问货币持有者的信息,然后做一个前向的def-use分析,去看获取到的信息是否会被SSTORE指令用到,如果用到的话就可以认为会对M进行了写操作。
然后这里有个问题是可能会找到一系列的对这个货币持有者信息进行写操作的指令,那么会得到多个新的余额,作者在这里统一把这些记为一个tuple,仅保存第一个和最后一个余额。
这样最后可以获取到Bm,Be和Br,对它们作比较即可找到是否有不一致存在,可参考下图:
