深度学习之单目深度估计:无监督学习篇
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者:桔子毛
https://zhuanlan.zhihu.com/p/29968267
本文仅做学术分享,如有侵权,请联系删除。
Previously on 单目深度估计:
在chapter.1 基础篇中,我们主要介绍了一些使用深度学习来进行单目深度估计的例子。Multi-layer的结构,形状大小各异的知名pre-trained网络将神经网络这种函数模拟器的优点发挥的淋漓尽致。但是这类方法有一个缺点就是在训练的过程中,我们需要预先知道大量的输入的图片所对应深度值的参考标准作为训练的约束,从而对神经网络进行反向传播,训练出我们的神经网络用来对于相似的场景进行深度预测。这类方法也就是常说的“监督学习”。但是现实情况下,求取场景所对应的深度值并不是一件容易的事。目前比较常用的方法是从kinect的红外传感器中得到深度(NYU Depth V2)或者借助于激光雷达(KITTI),kinect虽然比较廉价,但是所采集到的深度范围(超过4m kinect估计的深度的精度就会下降)和精度都有限。而激光雷达的成本就比较高了。那有没有一种方法能够在训练的时候不需要在已知深度的情况下得到一个估计深度的神经网络呢?本节中我们介绍几种通过非监督学习的方法进行单目深度估计的例子。
1. 基础知识
神奇的达尔文进化定律告诉我们,单个眼睛的自然界生物大都灭绝了。自然界的大多物种都是和人一样,需要两只眼睛来做三维空间定位。那为什么需要两只眼睛呢?
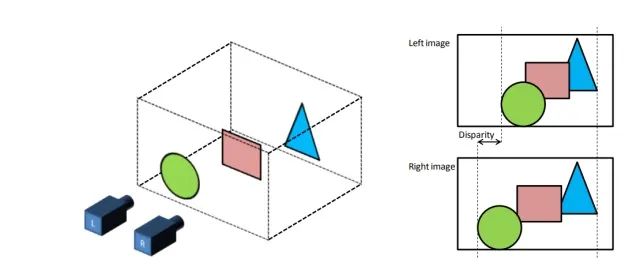
因为一只眼睛看到的图像是二维的,二维的信息是无法用来表示三维的空间的,如上图所示,虽然处于同一水平面上的照相机L,R拍摄了同一个物体,两者之间产生的图片是不同的。并且这种不同是不能通过平移生成的图片所消除的。离照相机近的物体偏离的位置比较大,离照相机远的物体偏离的比较少。这种差异性的存在就是三维空间带来的。同时同一水平线上的两个照相机拍摄到的照片是服从以下物理规律的:
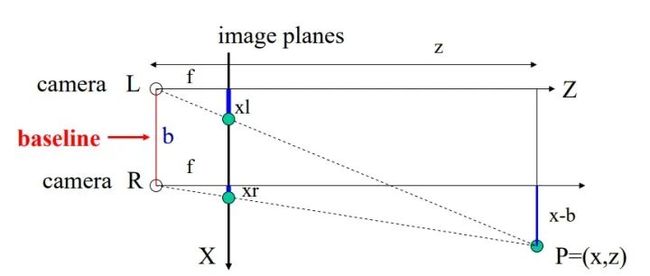
在图中, 为场景所距离我们的深度, 为三维场景映射到的二维图像平面,也就是最终我们得到的二维图像所在的平面。 为相机的焦距。 为两个相机之间的距离, 和 分别为相同物体在左右两个不同相机中成像的坐标。根据以上信息,和简单的三角形相似规律我们可以得到:
这里 就是我们常说的视差 (disparity), 代表了 这个点在照相机 和照相机 中成像的偏离值。也就是说这个值代表了左照相机中的像素需要通过平移 才能形成右照相机中相应的像素。所以两个视角之间的关系可以写作:
假设我们有一个很强大的函数 ,没错这个函数就是神经网络,使得 ,那么就有:
只要我们以 作为训练的输入, 作为所对应的参考标准,建立如上关系的神经网络 ,通过大量的双目图片对的训练,得到的神经网络 就是一个 输入一张图片 来预测所对应的视差 的函数,这样就将一个没有约束的问题变成了符合如上规律的问题,就可以采用常规思路进行求解了。同时视差 在已知照相机参数 的情况下,就能求取相对应的深度 。
总结以上规律我们得到:因为单目求深度需要昂贵的激光雷达,但是两个同一水平线上的两个照相机所拍摄的照片却相对容易得到。只要我们通过单张输入图片求取相对应的disparity ,同时在得知照相机参数( )的情况下也就能求得所对应的深度 。
这种思路最先应用于使用单张图片生成新视角问题:DeepStereo 和 Deep3d之中, 在传统的视角生成问题之中,首先会利用两张图(或多张)求取图片之间的视差d,其次通过得到的视差(相当于三维场景)来生成新视角。深度学习在这方面也有很多漂亮的工作,这个新坑以后再填。
2. 一些细节问题
在之前我们将单目深度估计问题写成了一个简单的函数:
通过本篇文章第一节的内容,这个函数可以进化成如下形式:
其中 为所预测的深度, 为固定相机下的视差, 为相机两个镜头之间的距离, 为焦距。
那我们知道, 这种关系可以轻而易举的使用CNN模拟出来,而(3)中的关系就有一个问题,我们预测到的d是连续的浮点数,如果使用 的套路,那么很有可能会落入到不在(整数)像素点的位置,同时由于不同位置 不同,也有可能有一个 中的像素点 接受多个来自 的像素点颜色,因为它们都满足 。而也有一些点并没有相符合的 ,因为这些点由于视差的原因在原图中可能根本不可见。为了解决这个问题,一般采用backward(reverse) mapping的方法,如下图所示:
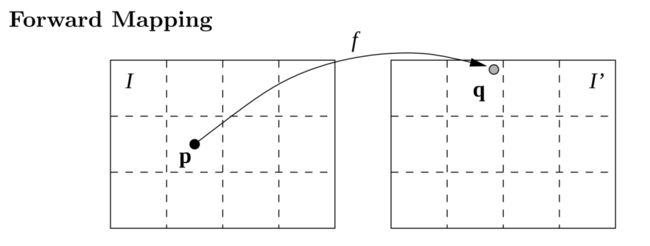
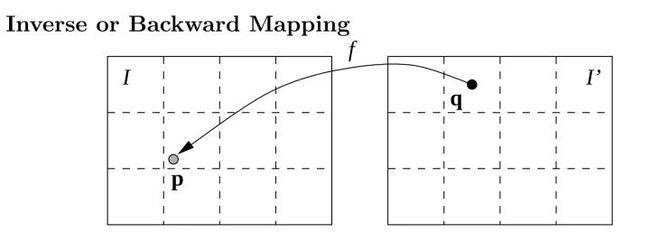
这两种方法的区别在于,在forward mapping中,我们得到 中的点可能会落在不是整数像素点的位置,这时只能通过最近原则将原图 中的像素点对应到 中去,而在Inverse mapping中,我们从 出发(也就是 ),去寻找相对应的原图中的点,这样能够确保 中的每一个点都有赋值不会出现空洞,并且如果 得到的原图中的点不属于(整数)像素点,这时可以通过插值的方法求得所对应非像素点的位置。一般在这里采用双线性插值的方法,而且它在sub-pixel level是可导的[Spatial Transformer Networks]。所以我们就可以end-to-end的来训练网络啦。
所以在训练的时候我们的网络分为了以下步奏:
而所对应的损失函数为:
至此,正向传播过程通过 来得到所对应的视差 ,mapping过程将右图转换成左图,损失函数计算当前的准确度并且进入优化过程,反向传播过程如下式所述:
上式中, 为 中需要优化的神经网络的参数, 由损失函数得到, 由mapping方法提供, 由神经网络自己back-propagation得到。测试过程只需要将 传入神经网络 就能得到所对应的视差,结合相机参数,就能求得深度。大功告成!接下来看看各路神仙都是怎么用这个思路来做深度预测的吧!
3. Naive 方法
Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue(ECCV 2016)

这篇文章所采用的方法和我上述描述稍有不同,我所采用的是:
而文章中所采用的是:
第一个不同在于mapping方程的求导方法上,在这篇文章中为了求得mapping相对于d的导数,使用泰勒展开式来得到。相当于一个numeric的求导过程:
而我们上一节中介绍的方法是通过线性插值来求导,更快,准确度更高。
第二个不同就是它通过 来map回 ,同时约束了输入图 与生成的输入图 之间的关系。但是不要小看这个区别,我的方法所预测的disparity描述了 经过 生成 的过程,而文章中预测到的disparity描述了 通过 生成 的过程。根据本文之前讨论的,输入图片的内容中由于不同视角物体的遮挡关系,原图 所表现出来的像素点位置可能在新视角 中并不存在。所以我预测到的 是 所对应的深度,而文章中预测到的则是 所对应的深度,虽然这两者在大部分的像素点的深度范围都相同,但也就是这样的细节告诉了我们,为什么人家的方法能够发ECCV而我只能发知乎专栏都是有原因的。
在网络方面,这篇文章采用了一个类似FCN的结构,没有全连接层的参与,体量小速度快。同时skip-connect的参与保证了输出特征细节的相对完整性,再其次就是可以使用pre-trained的网络结构作为encoder部分,在数据不足的情况下也能达到相对好的效果。
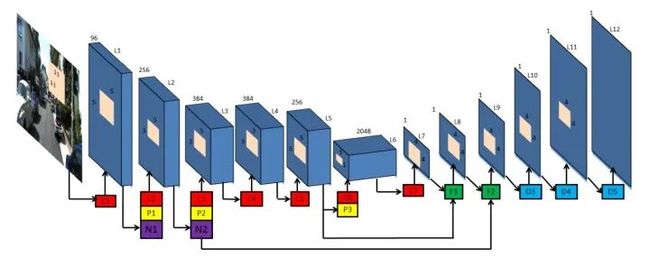
4. Unsupervised Monocular Depth Estimation with Left-Right Consistency
在刚才的文章中,我们介绍了Naive的方法来求解深度,同时也指出了我介绍的方法的不足,但是有没有方法能够结合这两种估计深度的方法得到更多的约束呢?接下来我们就来介绍一种robust,multi-level,multi-loss的方法用来做非监督的深度估计。
Unsupervised Monocular Depth Estimation with Left-Right Consistency(2017 CVPR)
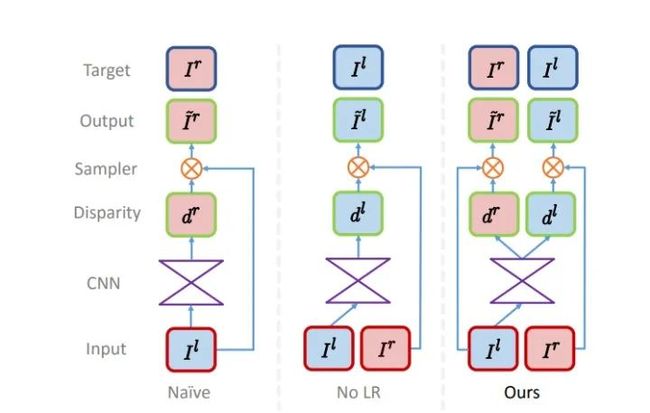
这篇文章方法上的贡献点可以参考上图,naive可以说是ECCV 2016的方法,No LR是本文之前介绍的方法,这篇文章相当于结合了这两个方法得到的结果。通过 进入神经网络可以求得 和 , 通过输入不同的参考图片在mapping中可以得到相对应的原图 和右图 。所以ECCV2016的损失函数仅仅是 ,而这一篇文章可以加的约束就多很多了:
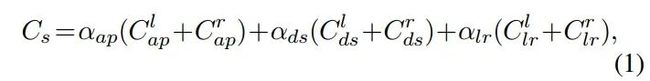
如上图所示,第一对 表示了图片重建的损失函数,在这里,作者采用了一个SSIM和L1相结合的损失函数,因为L1并不能很好的表示真实的图片分布(相关讨论可以看损失函数的讨论和SRGAN):
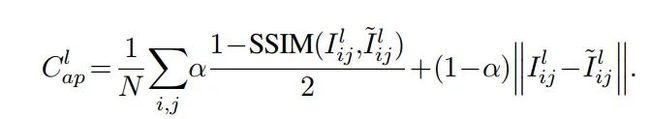
其次,理想状况下, 和 之间也存在着与原图相同的视差关系,也就是说:
所以,当预测的深度达到最优时,以下损失函数达到最小值,同理,交换 和 的位置所得等式依旧成立,这一项也就是本节文章题目中所说得到的left-right Consistency:
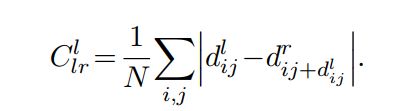
关于损失函数中的 部分,作者提出了一个edge preserving的损失函数,主要的意图是因为depth的不连续性往往发生在边缘附近。提出了这个损失函数用来保证所得到的深度图的光滑性与图像梯度一致。
说完了损失函数再来说说网络:
这篇文章所使用的网络和之前的方法类似,均采用了FCN的方法进行训练,不同的是在decoder部分的最外面4层,作者都估计了当前特征大小所对应的视差的值,并且将它上采样后传递给了decoder的下层,这样能确保每一层都在做提取disparity这件事,同时也相当于做了一个coarse-to-fine的深度预测,同时由于我们采用了双线性差值,梯度的范围始终来自于周围的4个坐标点,coarse-to-fine的预测能够让梯度来自于离当前位置更远的坐标点,6中也讨论了这个问题。

对于一个robust的系统来说 ,这篇文章可以说是典范了。各种novel的损失函数,multi-level的结果,solid的实验结果,加上简单有效的贡献点。五星推荐。所以这篇文章出来之后,就有人想,能不能结合有监督学习和无监督学习来共同进行深度预测?
5. Semi-Supervised Deep Learning for Monocular Depth Map Prediction
Semi-Supervised Deep Learning for Monocular Depth Map Prediction(2017 CVPR)
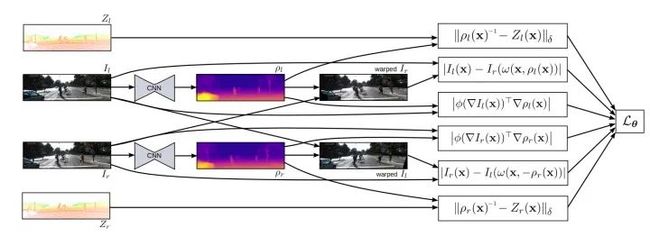
理解了上一篇就知道作者为什么要来写这一篇了。既然无监督学习深度能够取得好的效果,那么我们将传感器得到的稀疏的深度作为参考标准,和4中提到的完全非监督的方法共同去估计深度应该也会有好的效果。所以这篇文章的贡献点主要集中在损失函数部分,既有监督学习得到的loss(稀疏深度和预测到的深度的差值),又有非监督学习得到的loss(生成的新视角图片之间的差值),还有深度域上的正则项(depth梯度的正则)。结合以上一起用来训练。这篇文章的对比实验部分很详细,感觉可以挖掘出很多信息。
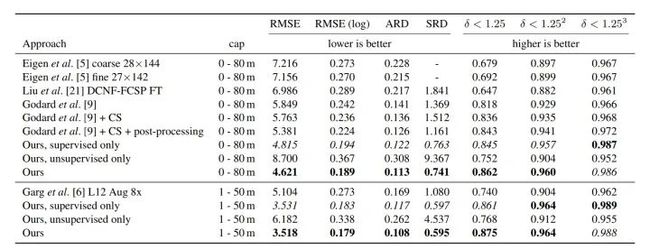
如图所示,[9]为我们之前在4中介绍过的"Unsupervised Monocular Depth Estimation with Left-Right Consistency”,[6]为我们在3中介绍过的"Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue",可以看到当前的方法仅仅采用非监督学习的方法是要差于[9]的,因为[9]中用了multi-scale的深度估计,left-right consistency的损失项等等。
同理我们再来比较一下每一个贡献点之间方法关系:
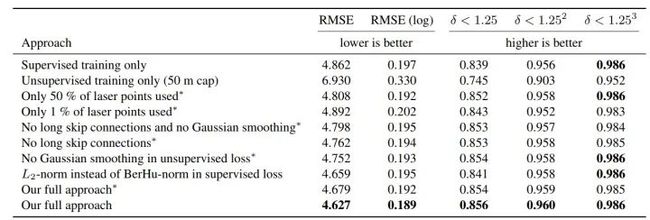
效果提升最明显有以下几个部分:1. 非监督学习和监督学习相结合,更多的监督数据得到更好的效果。2. skip-connection。3. Gaussian smoothing 也就是文章所说的正则项。第一个可以说是它这篇文章的主要贡献点,第二个则是一个非常general的方法。第三个算是一个很小的贡献点(这种smooth在上篇文章中也有用到)。所以这篇文章的自身的贡献点还是集中于非监督学习和监督学习的结合。
所以这篇文章(CVPR Spotlight)是没有上一篇文章(CVPR oral)好的。
6. Unsupervised Learning of Depth and Ego-Motion from Video
Unsupervised Learning of Depth and Ego-Motion from Video(CVPR 2017)
这篇文章的方法可以说是继承与ECCV2016这篇文章。在之前的文章中我们介绍到,在已知相机参数的情况下,我们可以通过视差 来得到相对应的深度 。那如果相机不在同一个平面并且参数我们也不知道呢?
如下图所示,先将 输入到Depth CNN 中用来预测深度 ,其次将 输入到pose CNN中来预测得到的照相机参数,所以就有 和 。这里G代表了depthCNN, F代表poseCNN, 通过深度 和照相机的参数 和两者之间的关系V,能够算出在t-1时刻或者t 1时刻所得到的重建图 ,以视角合成问题作为监督学习,所预测到的深度depth 和照相机的pose都是通过非监督学习过程得到的。网络方面这篇文章还是采用了FCN的结构(看来FCN这种结构已经制霸image-to-image translation领域了)
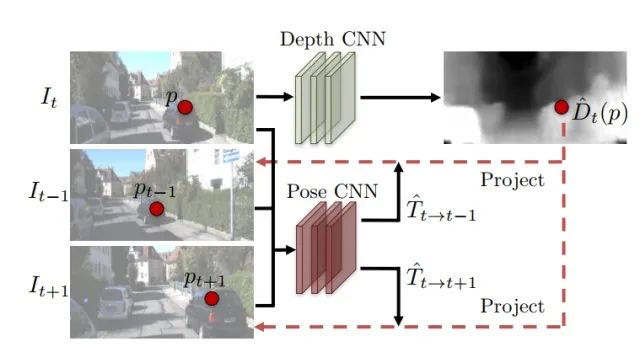
同时这篇文章的损失函数是很有意思的,这一系列视频帧中其实只是有一部分出现在了最后重建的结果之中,那么就需要对于每一帧有一个mask能够让我们挑选出出现在最终结果之中的部分,也就是这里的 用来过滤没有用的信息。我们知道,如果非监督学习来做这个问题我们拿到的数据就只有视频帧,是没有mask的参考标准的,如果我们通过如下损失函数去进行预测,那么当E中所有的值为0时,损失函数达到最小。但是这并不是我们想要的。所以这里作者使用了一个约束,用来得到E:假设mask所有的值都为1,然后使得像素值均为1的mask和 之间的交叉熵(cross-entropy loss)尽可能小(意味着两者更相似)。这也就意味着,我们需要得到一个尽可能大的mask,并且这个mask能够让重建的损失函数达到最小!

个人觉得是很聪明的做法,所以整个损失函数就变成了,其中smooth为预测的深度图的正则项:
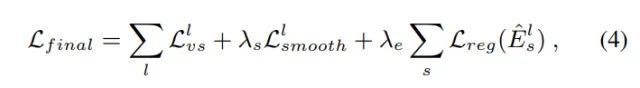
还有就是因为这篇文章中的算法是纯非监督学习的(甚至是照相机的参数),所以预测得到的深度相比前两篇CVPR的文章稍差一点。不过我觉得方法和适用性可以说是这三者里最好的一个了。
7.参考
部分图片来自于:
http://www.cs.tut.fi/~suominen/SGN-1656-stereo/stereo_instructions.pdf
https://courses.cs.washington.edu/courses/cse455/09wi/Lects/lect16.pdf
https://www.comp.nus.edu.sg/~cs4340/lecture/imorph.pdf
推荐阅读:
专辑|相机标定
专辑|3D点云
专辑|SLAM
专辑|深度学习与自动驾驶
专辑|结构光
专辑|事件相机
专辑|OpenCV学习
专辑|学习资源汇总
专辑|招聘与项目对接
专辑|读书笔记
专辑|相机标定
专辑|3D点云
专辑|SLAM
专辑|深度学习与自动驾驶
专辑|结构光
专辑|事件相机
专辑|OpenCV学习
专辑|学习资源汇总
专辑|招聘与项目对接
专辑|读书笔记
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近1000+星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题