java虚拟机
通常java虚拟机我们需要了解的是执行流程,类加载器,双亲委托机制,内存模型,以及Gc算法四大块内容。下面我们挨个讲解下:
执行流程:
java虚拟机分为编译和运行阶段,编译阶段将.java文件转化为.class文件,运行阶段解析class文件
类加载器:
1、BootStrap ClassLoader 用于加载jdk核心库,java.lang、java.util,应用层用不到
2、Extension ClassLoader 用于加载jie和系统属性类,应用层用不到
3、Application ClassLoader(System ClassLoader) 应用层类加载器,一般我们用到的就是这个,可以加载当前应用程序的类信息,framework层的类信息。
jdk中有个基础的classLoader类,我们看下Dalvik虚拟机中的使用:
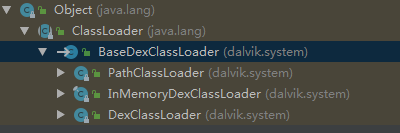
分为三个子类:
PathClassLoader:只能加载系统中已经安装过的apk
DexClassLoader:可以加载jar/apk/dex,可以从SD卡中加载未安装的apk
android o 增加了InMemoryDexClassLoader:从内存中加载dex
简单分析下 BaseDexClassLoader的构造函数:
public BaseDexClassLoader(String dexPath, File optimizedDirectory, String librarySearchPath, ClassLoader parent) {
throw new RuntimeException("Stub!");
}
参数:
dexpath:dex文件的地址,可以为Application 类中的sourceDir值,jar或者apk的路径
optimizedDirectory:输出odex的路径
librarySearchPath:native层的路径,没有so库的可以传null,
DexClassLoader 与 PathClassLoader 构造函数区别就是多了个optimizedDirectory参数。
那么optimizedDirectory是什么呢?这是一个内部存储目录,DexClassLoader 指定这个目录,可以将外部的apk/jar对应的dex文件复制到这个目录里,再通过这个目录解析,而PathClassLoader 无法指定,所以只能直接加载已有的dex文件,如Application 类中的sourceDir。
双亲委托机制查找一个需要的类:
1、每个类加载器都有自己的类缓存队列,从当前的ClassLoader缓存队列中,查找已经解析过的类,如果没找到,让父classLoader去找
2、父ClassLoader也在自己查找过的类中找,如果没找到,再交给它的父类,最终交给BootStrap Classloader
3、当从所有的缓存队列中都没找到,再通过当前的ClassLoader进行加载
根据这个机制,热修复的实现,借助DexPathList查找类的方式,将dex文件封装成Element数组,看下关键代码;
public Class findClass(String name, List suppressed) {
for (Element element : dexElements) {
DexFile dex = element.dexFile;
if (dex != null) {
// 在dex文件中查找类名与name相同的类
Class clazz = dex.loadClassBinaryName(name, definingContext, suppressed);
if (clazz != null) {
return clazz;
}
}
}
if (dexElementsSuppressedExceptions != null) {
suppressed.addAll(Arrays.asList(dexElementsSuppressedExceptions));
}
return null;
} Element是Dex文件,而dex文件是.class文件的数组,它从dexElements对象中一个个取出文件,如果我们通过反射的形式,将要替换的类放在第一个位置,是不是就不需要加载老的类了,这应该是常用的一种热更新的形式了。
内存模型:
一般分为程序计数器、java堆,方法区,运行时常量池,本地方法栈,java栈
程序计数器:虚拟机自行维护的,每个线程都有自己的程序计数器,确保执行的字节码顺序,开发不用管
java堆:所有线程的共享区域,存放对象实例,内存不够,会抛出OutOfMemoryError异常
java栈:生命周期与当前线程相同,如局部变量,如申请内存时分配的内存超过虚拟机所允许的最大内存,会抛出Stack Overflow,而动态变化内存时,没有足够的内存,会抛出OutOfMemoryError异常
方法区:所有线程的共享区域,存放静态变量,常量池、方法信息等,独占内存,内存不够,会抛出OutOfMemoryError异常
本地方法栈:native层的栈,C层的方法和变量都存在这里
运行时常量池:方法区的一部分,类或者接口里的常量在运行时的表现形式
Gc算法:
gc回收的功能分为两个,1、找出需要回收的类,2、如何处理回收的类,那么怎么找?
找的方式分为两种:引用计数算法和根搜索算法。
引用计数:每个对象都有一个引用计数器,引用一次加一次,移除引用就减一次,但目前的java虚拟机没有采用,因为当存在互相引用又双方都释放的情况下,引用计数器为1,但实际应该都失效了,可以回收的情况有问题
根搜索算法:找一个Gc Root对象,向下搜索,如果目标对象和Gc Root对象有引用关系,则说明可达,如果没有,则表示可回收,而Gc Root对象一般为:java栈中引用的对象,c层引用的对象,方法区引用的对象等
还有对于对象有四种引用模式:强、弱、软、虚,引用模式的不同,会在gc回收时是否将这个对象标记为可回收有关。
强引用:无论是否内存不足,都不会回收,宁愿抛出OutOfMemoryError异常
弱引用:gc回收的时候,无论内存是否不足,都会回收掉
软引用:内存不足时,gc回收,会释放当前对象,当释放完内存还不够,抛出OutOfMemoryError异常
虚引用:和没引用一样,没有引用关系,但回收的时候会发出系统通知
以上是怎么标记一个对象是否是可回收的方式,那么找到这些对象后,需要收集起来,进行释放,那么怎么收集呢?
垃圾对象收集有4种算法:
1、标记-清除:找到回收对象,做下标记,直接对对象清除,这种方式会产生大量不连续的内存碎片,导致后续没有足够的内存,效率也不高
2、复制算法:将内存空间划分为两个相等的区域,把存活的对象复制到另一个区域,再清除原来区域所有的对象,复制算法的效率与存活对象的数量有很大关系,因为需要复制,如果存活数量很少,那效率会很高,因此jvm中有新生代和老年代的区分,.class文件的数据结构也有一个age对象,新生代的存活对象要少,因此用复制算法
3、标记-压缩算法:老年代的存活对象很多,复制效率低,将所有存活的对象压缩到内存一端,使他们紧紧排列在一起,再把边界以外的内存进行回收
4、分代收集算法:
目前流行的算法,主要是对对象的类型先做区分,java堆就基于这一算法,对新生代垃圾执行复制算法,对老年代垃圾执行标记-压缩或者标记清除算法