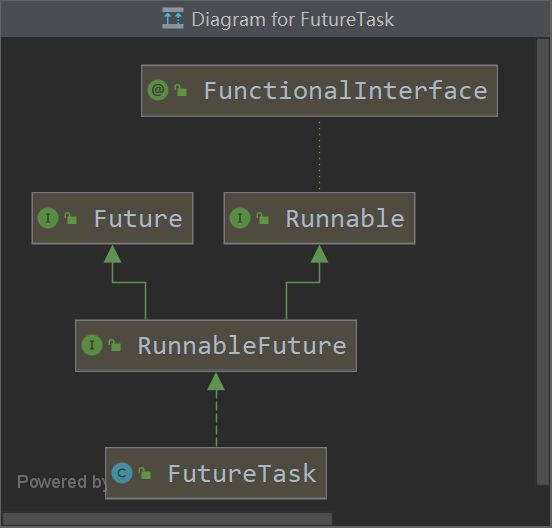
FutureTask是一个具体的实现类,实现了RunnableFuture接口,RunnableFuture分别继承了Runnable和Future接口,因此FutureTask类既可以被线程执行,又可以拿到线程执行的结果。FutrueTask应用于多线程中异步处理并得到处理结果的场景,比如:加入有个流程需要调用远程接口拿到相关数据在本地进行处理,但是这个接口花费时间比较长。如果使用传统的阻塞线程去处理的话,那么就会一直阻塞在调用接口这里,其它的事情都干不了,这样操作显然效率相对较低的。因此,我们可以使用FutureTask来解决这个问题,FutureTask可以异步调用远端接口,那么当前线程就可以做与远端接口无关的数据,双管齐下提高效率。
FutureTask UML类图:
FutureTask类简单的使用示例:
public static void main(String[] args) throws InterruptedException, ExecutionException {
FutureTask futureTask = new FutureTask<>(() -> {
System.out.println("异步处理");
Thread.sleep(3000);
return "ok";
});
new Thread(futureTask).start();
System.out.println("同步处理其它事情");
Thread.sleep(1000);
System.out.println("等待异步处理结果:" + futureTask.get());
System.out.println("处理完成");
}
一、成员变量
FutureTask类有state,callable,outcome,runner和waiters 5个成员变量
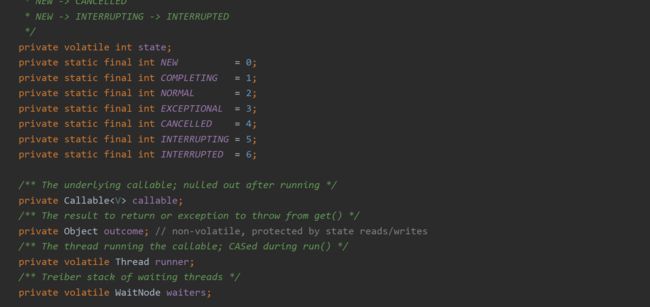
1.state
线程运行状态,有以下几种状态:
NEW:初始状态,在初始化时的状态,状态值为0;
COMPLETING: 完成中状态,run方法被调用时,对返回值进行赋值欠的状态,值为1;
NORMAL: 正常状态,线程正常执行,在返回值被赋值被赋值成功后的状态,值为2;
EXCEPTIONAL:异常状态,在执行用户回调方式call的过程中出现异常,值为3;
CANCELLED: 取消状态,用户调用cancel(false)方法时的状态,值为4;
INTERRUPTING:打断中状态,用户调用cancel(true)方法时的状态,值为5;
INTERRUPTED: 被打断状态,用户调用cancel(true)方法时,runner线程执行打断方法完成后的状态,值为6;
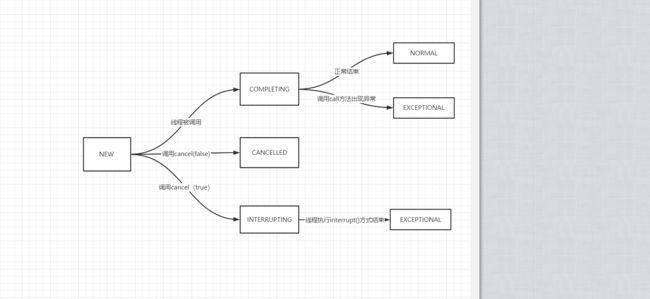
运行状态转换:
NEW -> COMPLETING -> NORMAL
NEW -> COMPLETING -> EXCEPTIONAL
NEW -> CANCELLED
NEW -> INTERRUPTING -> INTERRUPTED
2.callable
该成员变量用于异步执行用户自定义业务代码,当futureTask获得cpu时间片后调用run方法,在run方法中调用callable.call(),获取到执行结果。
3.outcome
异步执行输出结果,类型为object。赋值时机时在callable.call()方式执行完成后。
4.runner
用于执行callable接口,在futureTask被cpu调度时会使用cas赋值为当前线程。当前线程执行完成后设置为null,等待gc回收。
5.waiters
内部类实现的单向链表,用于等待获取执行结果。每次调用get()方法时都会将该线程放入等待队列的头部,当该线程被打断后,或者get(timeout)方法过期后就会重这个等待队列中移除。当callable.call()执行完成后会从头部开始遍历逐个唤醒等待线程,并将执行结果返回。
二、核心方法
1.run方法
run方法间接实现于Runnable的接口,所以当futureTask线程获得cpu资源后会调用该方法。
1.首先先判断当前状态是否为初始化状态,如果不是初始状态直接结束该方法。否则使用cas方式给成员变量runner赋值,赋值为当前线程。用cas方式能够保证多线程环境下赋值是线程安全的。不懂cas的同学自行查阅相关资料。
2.如果callable不为null并且state状态为NEW,则执行callable.call()方法,并得到该方法的返回值。
3.如果执行call方法出现异常时,执行setException方法,该方法将state的NEW状态使用cas方式修改为COMPLETING状态,修改成功后outcome设置为当前抛出的异常,状态再次改为EXCEPTIONAL状态。然后将等待队列中的线程都唤醒,并从队列中移除。调用钩子done()方法,将callable掷为null。
4.如果call方式执行成功,下一步则调用set方法,该方法首先将NEW状态用cas修改成COMPLETING状态,修改成功后将call执行结果赋值到outcome变量,COMPLETING状态修改为NORMAL,唤醒等待线程并从队列移除,调用狗子方法。
5.执行finally代码的代码,将runner掷为null,如果当前状态为打断中,那么会将当前资源让出,直到线程最终被打断。
/**
* Runnable#run();
* 线程获得cpu资源后会执行该方法
*/
public void run() {
//判断当前状态是不是初始状态
//将runner赋值为当前线程
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
//调用用户业务流程
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
//抛出异常,修改响应的状态
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
/**
* 1.修改状态值 NEW --> COMPLETING --> EXCEPTIONAL
* 2.移除并唤醒所有等待中的线程
* @param t
*/
protected void setException(Throwable t) {
//将state修改为COMPLETING
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = t;
//将state修改为EXCEPTIONAL
UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); // final state
//对返回值进行处理
finishCompletion();
}
}
/**
* 1.状态值 NEW --> COMPLETING --> NORMAL
* 2.设置执行结果值
* 3.唤醒所有等待中的线程
* @param v
*/
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = v;
UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state
finishCompletion();
}
}
2.get() 和 get(long timeout,TimeUnit timeUnit);
两个方法的区别在于前者没有超时时间,后者由超时时间,流程是基本差不多的。
1.如果state为COMPLETED,进入report方法,该方法会判断当前的状态为NORMAL时将outcome返回,否则抛出异常。
2.如果state不为COMPLETED进入awaitDone方法。
3.awaitDone方法顾名思义就是等待操作结果。方法里面是一个死循环,在循环过程中如果线程被打断,就会抛出异常,并将刚创建的等待线程从队列中移除。
4.如果状态已完成,将等待线程绑定的线程设为null,并将状态返回。
5.如果当前状态为COMPLETING则将当前cpu资源让出给其它线程。
6.如果等待节点为null,就创建一个新的节点,该节点绑定了当前的线程。
7.如果新创建的节点还没有与等待队列进行绑定,那么就将该节点放入队列头部。
8.如果调用的是由过期时间的方法,那么判断如果已经到期了则将该节点从队列中移除,并返回状态。否则进入有过期的等待。
9.线程进入等待状态,线程会阻塞在这里,等待run方法执行完成后调用unPark方法。
10.线程被唤醒后,进入report方法。
/**
* @throws CancellationException {@inheritDoc}
*/
/**
* 获取执行结果
* @return
* @throws InterruptedException
* @throws ExecutionException
*/
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
/**
* @throws CancellationException {@inheritDoc}
*/
/**
* 获取执行结果
* @param timeout
* @param unit
* @return
* @throws InterruptedException
* @throws ExecutionException
* @throws TimeoutException
*/
public V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
if (unit == null)
throw new NullPointerException();
int s = state;
if (s <= COMPLETING &&
(s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING)
throw new TimeoutException();
return report(s);
}
3.awaitDone(boolean timed, long nanos)
该方法是等待完成,或者线程被打断而抛出异常退出,有或者是经过nanos 这么多纳秒后退出。方法内部是一个死循环,通过各种条件判断是否满足条件退出,否则线程进入等待状态,直到被其他线程唤醒。
1.首先会判断当前线程是否有打断标记,如果被打断过,删除刚创建出来的等待节点,并抛出InterruptedException异常。
2.如果当前任务是已完成状态,直接将当前状态返回。
3.如果当前任务状态为完成中,说明其他线程正在操作,当前线程无需要重复操作,只需要将cpu资源让出来。
4.如果前三个条件均未满足,则会创建等待节点,然后进入第二轮循环。
5.第二轮循环,将第二轮循环创建的等待节点放入等待链表的头部,并使用cas方式给waiters赋值,保证多线程下正常正确的赋值。
6.第三轮循环,如果用户调用的是有过期时间的get方法,则会计算当前剩余时间,1)如果剩余时间小于等于0,则说明已经过期,那么就会移除当前等待中的节点,将当前任务状态返回。2)否则调用LockSupport的有过期时间的parkNanos,该方法会让线程进入等待状态,也即线程会阻塞在这里,过期时间不会超过用户传入的过期时间。如果用户调用的是没有过期时间的方法,那么调用LockSupport的有无过期时间的parkNanos,该方法会让线程无限的等待下午,知道有其他线程将他唤醒。
源码:
/**
* Awaits completion or aborts on interrupt or timeout.
*
* 等待完成或打断退出或超时退出
* @param timed true if use timed waits 是否有超时时间
* @param nanos time to wait, if timed 等待时间
* @return state upon completion 状态码
*/
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
//返回true,线程被打断过,但并不会直接抛出异常
//而是等其他线程将线程唤醒之后,发现该线程在等待过程中执行了打断操作
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
//这里的意思是任务已完成,又可以能是正常结束,也有可以能是用户取消,或者异常,打断
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
//让出cpu资源
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
//第一次循环会进入这个条件创建节点
else if (q == null)
q = new WaitNode();
//第二次循环给新创建的q节点放在waiters链表的头部
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
//过期退出
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
//有限时间挂起线程
LockSupport.parkNanos(this, nanos);
}
else
//无限时间挂起线程
LockSupport.park(this);
}
}
三、总结
FutureTask是运用了高并发设计思想的Future设计模式。它很好的处理了高并发下处理多件获取或创建数据并无相关联的操作耗时长的问题。设计者可以将耗时比较长的操作(比如远程调用接口等)使用异步的方式(即创建一个新的线程)去处理,那么主线程就可以做其他的事情了,这样可以大大减少整体的处理时间。这个模式适用于多个无关联的时间,如果A操作的进行需要B操作的结果才可以开始,那么A其实是一直带阻塞等待B的结果的,这个串行执行的耗时差不多,使用future模式意义不大。
FutureTask的get方法在用户逻辑代码未返回结果时仍然后进入阻塞,但是用户业务代码的执行并不受主线程(创建FutureTask的线程)的影响。我们可以通过重写done方法来获取到完成动作,这样我们再调用get方法时就不会阻塞。
在现实生活中就有很多类似Future模式的例子。比如你的生日快到了,你需要去蛋糕店订蛋糕,同时还需要买其他的礼品,开party所需的东西等,假设蛋糕店制作蛋糕需要花费1个小时,购买其他物品需要2小时。用传统的串行的方式就是你去蛋糕店跟老板说你要订蛋糕,老板根据你的需求开始制作蛋糕,你就在店里坐着等制作完成。1个小时后终于制作好蛋糕了,然后你才能拿着蛋糕去买其他东西,买完其他东西有需要耗费2小时,最后你总共花费了3小时。当使用Future模式时,你事先写好你需要订多大的,什么口味的蛋糕,然后去到蛋糕跟老板说你先去买其他东西,一会再过来拿。但是你忘记留联系方式给蛋糕店老板了(没有重写done方法),所以你并不知道蛋糕什么时候做好,提前过去拿,那你还得在店里等蛋糕做好。如果重写了done方法,相当于给店老板留了电话号码,等蛋糕做好老板就会打电话给你,你过拿蛋糕时就不会说太早过去要等一会或太晚过去了。我们用最坏的情况来计算,你买其他东西花了两个小时,制作蛋糕花了1个小时。由于制作蛋糕和你没其他东西是分开同时进行的,所以最终你只花了2个小时,比串行的方式快了1个小时。
以上就是我在看FutureTask源码过程中的总结,如有错漏欢迎提出。