每周总结(@OneToMany的用法)
这周主要遇到的问题是开发一对多的关系,由于需求的变更,以前项目中的几个字段现在可以保存多选的情况,又因为这个字段还关联了其它的表,所以现在重新设计了数据库表,多的一方添加了外键关联,关联一的一方的主键,假设有个学校表school是一的一方,学生表student是多的一方,学生表中有sch_id外键关联学校表。建表语句如下:
学校表:
Create Table
CREATE TABLE `school` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` varchar(16) DEFAULT NULL COMMENT '学校名',
`address` varchar(64) DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
学生表:
CREATE TABLE `student` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`sch_id` bigint(20) DEFAULT NULL COMMENT '关联学校表主键',
`sch_name` varchar(16) DEFAULT NULL COMMENT '学校名',
`age` int(3) DEFAULT NULL COMMENT '年龄',
`name` varchar(16) DEFAULT NULL COMMENT '学生姓名',
`address` varchar(64) DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`),
KEY `sch_id` (`sch_id`),
CONSTRAINT `student_ibfk_1` FOREIGN KEY (`sch_id`) REFERENCES `school` (`id`) ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8
实体类的创建可以自动生成,可以参考教程:https://blog.csdn.net/itguangit/article/details/78696797 ,需要注意的是自动生成实体类的主键id上应再加上@GeneratedValue(strategy = GenerationType.IDENTITY)这个注解,IDENTITY:主键由数据库自动生成(主要是自动增长型)。
接下来就到了比较重要的@OneToMany和@ManyToOne的使用方式,首先应知道有两种用法,第一种是单向使用@OneToMany或者@ManyToOne,第二中是同时使用@OneToMany和@ManyToOne这两个注解,这里先讲解一下单向@OneToMany的用法:
private List studentEntityList = new ArrayList();
//注解写在属性或者getter方法上是一样的效果
@OneToMany(cascade = CascadeType.ALL) //表示级练操作
@JoinColumn(name = "sch_id") //表示对应子表的关联外键,如果不使用这个注解则需要创建中间表
public List getStudentEntityList() {
return studentEntityList;
}
public void setStudentEntityList(List studentEntityList) {
this.studentEntityList = studentEntityList;
} 测试保存方法:
@Test
public void test01(){
SchoolEntity entity = new SchoolEntity();
entity.setName("a学校");
entity.setAddress("龙场");
StudentEntity stu1 = new StudentEntity();
stu1.setName("小明");
stu1.setAge(12);
StudentEntity stu2 = new StudentEntity();
stu2.setName("小华");
stu2.setAge(15);
List list = new ArrayList();
list.add(stu1);
list.add(stu2);
entity.setStudentEntityList(list);
schoolRepository.saveAndFlush(entity);
} 如果不添加 @JoinColumn注解,又因为我配置自动创建数据库表为false,所以直接报错,查看log日志:
log4j:WARN No appenders could be found for logger (org.springframework.test.context.junit4.SpringJUnit4ClassRunner).
log4j:WARN Please initialize the log4j system properly.
Hibernate: insert into school (address, name) values (?, ?)
Hibernate: insert into student (address, age, name, sch_id, sch_name) values (?, ?, ?, ?, ?)
Hibernate: insert into student (address, age, name, sch_id, sch_name) values (?, ?, ?, ?, ?)
Hibernate: insert into school_student (SchoolEntity_id, studentEntityList_id) values (?, ?)
//由于没有school_student中间表,然后就报错了更新和保存类似,只不过更新需要先查出数据再保存,更新测试代码:
@Test
public void test02(){
SchoolEntity entity =schoolRepository.findById(1L);
entity.setName("a学校");
entity.setAddress("aaa");
StudentEntity stu1 = new StudentEntity();
stu1.setName("小明");
stu1.setAge(12);
StudentEntity stu2 = new StudentEntity();
stu2.setName("小华");
stu2.setAge(15);
List list = new ArrayList();
list.add(stu1);
list.add(stu2);
entity.setStudentEntityList(list);
schoolRepository.saveAndFlush(entity);
} 更新操作的log日志:
log4j:WARN No appenders could be found for logger (org.springframework.test.context.junit4.SpringJUnit4ClassRunner).
log4j:WARN Please initialize the log4j system properly.
Hibernate: select schoolenti0_.id as id1_0_, schoolenti0_.address as address2_0_, schoolenti0_.name as name3_0_ from school schoolenti0_ where schoolenti0_.id=?
Hibernate: select schoolenti0_.id as id1_0_1_, schoolenti0_.address as address2_0_1_, schoolenti0_.name as name3_0_1_, studentent1_.sch_id as sch_id5_1_3_, studentent1_.id as id1_1_3_, studentent1_.id as id1_1_0_, studentent1_.address as address2_1_0_, studentent1_.age as age3_1_0_, studentent1_.name as name4_1_0_, studentent1_.sch_id as sch_id5_1_0_, studentent1_.sch_name as sch_name6_1_0_ from school schoolenti0_ left outer join student studentent1_ on schoolenti0_.id=studentent1_.sch_id where schoolenti0_.id=?
Hibernate: insert into student (address, age, name, sch_id, sch_name) values (?, ?, ?, ?, ?)
Hibernate: insert into student (address, age, name, sch_id, sch_name) values (?, ?, ?, ?, ?)
Hibernate: update student set sch_id=null where sch_id=? and id=?
Hibernate: update student set sch_id=null where sch_id=? and id=?
Hibernate: update student set sch_id=? where id=?
Hibernate: update student set sch_id=? where id=?发现对于子表是先插入数据,然后在把以前的关联外键sch_id置为null
数据库中表的截图:
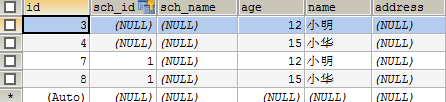
如果@OneToMany(cascade = CascadeType.ALL,orphanRemoval = true)添加orphanRemoval = true这个属性就会在更新的时候就不会保留sch_id为null的数据。
对于删除操作就没什么可以说的,直接根据主键删除,由于设置的是级联操作,根据主表的id删除则对应子表的数据也会被删除,我发现使用自己写的deleteById()删除方法会报"No EntityManager with actual transaction available for current thread- cannot reliably process 'remove' call "这个错,原来这是因为我自己写的deleteById()方法上面没有加事物导致的,方法上添加@Transactional即可解决。至于单向的@ManyToOne和单向的@OneToMany类似的。
接下来就是第二种方式,双向使用@OneToMany和@ManyToOne:
重新换个案例,一个公司有多个员工,Company和Employee也是一对多的关系;
/**拥有的员工*/
@OneToMany(mappedBy="company",cascade=CascadeType.ALL,fetch=FetchType.LAZY,orphanRemoval = true)
//拥有mappedBy注解的实体类为关系被维护端,双向关联需要用此注解
//mappedBy="company"中的company是Employee中的company属性
//orphanRemoval为true,表示会先直接删除对应的子表数据,级联更新此配置最为关键
private Set employees = new HashSet();
public Set getEmployees() {
return employees;
}
public void setEmployees(Set employees) {
this.employees = employees;
}
/**所属公司*/
@ManyToOne(cascade={CascadeType.MERGE,CascadeType.REFRESH},optional=false)//可选属性optional=false,表示company不能为空
@JoinColumn(name="company_id")//设置在employee表中的关联字段(外键),另注意因为这里已经写了company_id,所以员工类不用在写companyId这个属性
private Company company;
public Company getCompany() {
return company;
}
public void setCompany(Company company) {
this.company = company;
}
测试更新方法:
@Test
public void testUpdateCompany() {
Company one = companyRepository.findOne(7L);
//new 一个雇员
Employee e1 = new Employee();
e1.setName("11111");
//设置所属的公司,必须要设置(实体属性注解使用了optional=false,雇员必须要属于公司,所以公司属性不能为空)
e1.setCompany(one);
//new 一个雇员
Employee e2 = new Employee();
e2.setName("2222");
//设置所属的公司,必须要设置(实体属性注解使用了optional=false,雇员必须要属于公司,所以公司属性不能为空)
e2.setCompany(one);
//把雇员放到集合中
Set employees = new HashSet();
employees.add(e1);
employees.add(e2);
//设置公司拥有的雇员
one.setEmployees(employees);
companyRepository.saveAndFlush(one);
} 使用双向关联最大的好处是在于执行的效率更高,一般在实际项目中都是同时使用@OneToMany和@ManyToOne的,还有级联的操作也要慎重考虑,一般不会使用cascade=CascadeType.ALL这个属性的。