Java 哈夫曼编码与解码
1.哈夫曼树
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度(wpl)达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
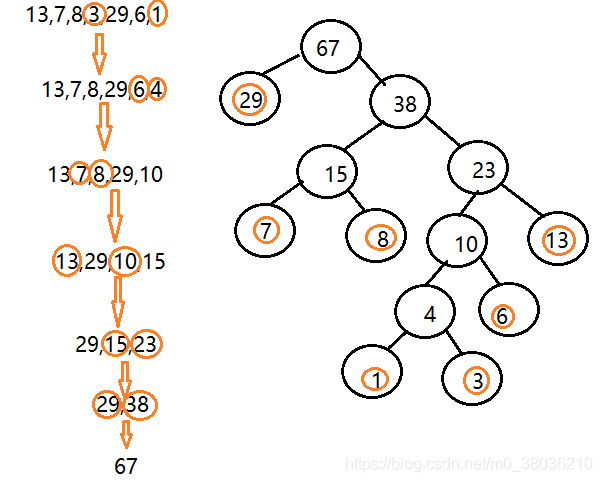
构成哈夫曼树的步骤:
- 从小到大进行排序, 将每一个数据,每个数据都是一个节点 , 每个节点可以看成是一颗最简单的二叉树
- 取出根节点权值最小的两棵二叉树
- 组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两棵二叉树根节点权值的和
- 再将这颗新的二叉树,以根节点的权值大小 再次排序, 不断重复 1-2-3-4
的步骤,直到数列中,所有的数据都被处理,就得到一棵哈夫曼树
以{13,7,8,3,29,6,1}为例:
2.哈夫曼编码与解码的具体步骤
以"good good study为例"
1)根据字符,统计权值
//统计每个字符的权值,转为HNode,存入nodes
public static List getNodes(char[] chars){
List nodes=new ArrayList<>();
Map counts=new HashMap<>();
for(char c:chars){
Integer count=counts.get(c);
if(count==null){
counts.put(c, 1);
}
else{
counts.put(c, count+1);
}
}
//遍历Map,转为HNode存入nodes
for(Map.Entry entry: counts.entrySet()) {
nodes.add(new HNode(entry.getKey(), entry.getValue()));
}
return nodes;
}
[data= , weight=2]
[data=s, weight=1]
[data=d, weight=3]
[data=t, weight=1]
[data=u, weight=1]
[data=g, weight=2]
[data=y, weight=1]
[data=o, weight=4]
2)根据权值,生成Huffman树
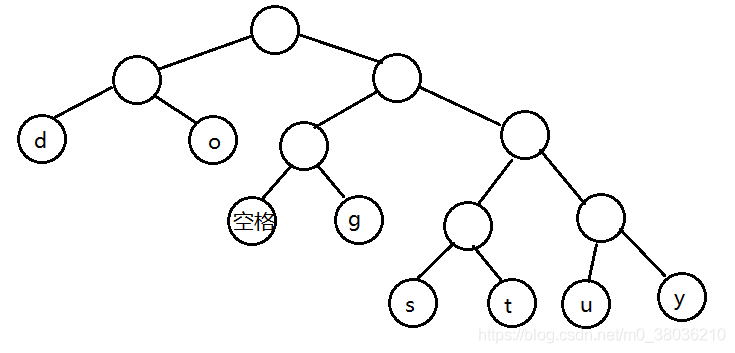
//创建Huffman树
//构成赫夫曼树的步骤:
//1) 从小到大进行排序, 将每一个数据,每个数据都是一个节点 , 每个节点可以看成是一颗最简单的二叉树
//2) 取出根节点权值最小的两颗二叉树
//3) 组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和
//4) 再将这颗新的二叉树,以根节点的权值大小 再次排序, 不断重复 1-2-3-4 的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树
public static HNode createHuffmanTree(List nodes){
while(nodes.size()>1){
Collections.sort(nodes);
//取出最小的作为左结点
HNode leftNode=nodes.get(0);
//取出次小的结点作为右结点
HNode rightNode=nodes.get(1);
//新建一个结点作为父节点
HNode parent=new HNode(null,leftNode.weight+rightNode.weight);
//父节点指向两个子节点
parent.left=leftNode;
parent.right=rightNode;
//从nodes中删除leftNode和rightNode
nodes.remove(leftNode);
nodes.remove(rightNode);
//nodes中加上parent结点
nodes.add(parent);
}
return nodes.get(0);
}
3)编码:
1.根据Huffman树,得到Huffman编码表(左-0,右-1)
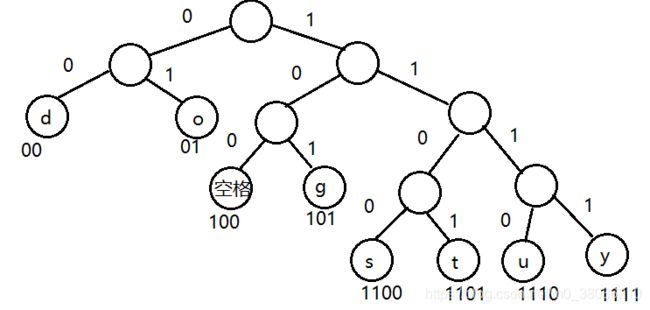
生成的哈夫曼编码表:{ 空格=100, s=1100, d=00, t=1101, u=1110, g=101, y=1111, o=01}
static Map huffmanCodes=new HashMap();//使用Map保存编码表
/**生成哈夫曼树对应的编码
* @param root 哈夫曼根节点
* @return 哈夫曼编码表
*/
public static Map getCodes(HNode root){
if (root!=null){
getCodes(root,"",new StringBuilder());
}
else{
System.out.println("该二叉树为空");
}
return huffmanCodes;
}
/**
* 功能:将所有叶子结点的赫夫曼编码得到,并放入到huffmanCodes集合
* @param node
* @param code 左-0 右-1
* @param sb 用于拼接
*/
private static void getCodes(HNode node,String code,StringBuilder sb){
StringBuilder sb2 = new StringBuilder(sb);
//将code 加入到 stringBuilder2
sb2.append(code);
if(node != null) { //如果node == null不处理
//判断当前node 是叶子结点还是非叶子结点
if(node.data == null) { //非叶子结点
//递归处理
//向左递归
getCodes(node.left, "0", sb2);
//向右递归
getCodes(node.right, "1", sb2);
} else { //说明是一个叶子结点
//就表示找到某个叶子结点的最后
huffmanCodes.put(node.data, sb2.toString());
}
}
}
2.根据Huffman编码表,将待编码的字符串进行编码 
/**
* zip:将字符串按照编码表的编码规则转为HuffmanCode
* @param s 待压缩的字符串
* @param huffmanCodes 编码表
*/
public static String zip(String s,MaphuffmanCodes){
StringBuilder sb=new StringBuilder();
for(int i=0;i 4)解码:
1.根据Huffman编码表得到Huffman解码表
生成的哈夫曼解码表:{00=d, 100=空格 , 01=o, 101=g, 1101=t, 1100=s, 1111=y, 1110=u}
/**
* 解码表,将编码表的key-value反转,得到解码表
* @param 编码表
* @return 解码表
*/
public static Map decodeTable(MaphuffmanCodes){
Map deCodeTable=new HashMap<>();
for(Entry entry: huffmanCodes.entrySet()) {
deCodeTable.put(entry.getValue(), entry.getKey());
}
return deCodeTable;
}
2.根据Huffman解码表得到解码后的字符串

/**
* UnZip:将HuffmanCode按照解码表的编码规则转为字符串
* @param s
* @param decodeTable
*/
public static String UnZip(String s,Map decodeTable){
StringBuilder res=new StringBuilder(); //用于存储返回结果值
StringBuilder sb=new StringBuilder(); //用于存储当前解码的码值
for(int i=0;i 3.完整实现
package tree;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
/**
* 实现Huffman编码与解码
* @author BayMax
*/
@SuppressWarnings("all")
public class HuffmanTree {
public static void main(String[] args) {
String s="good good study";
char []chars=s.toCharArray();
ArrayList li=(ArrayList) getNodes(chars);
System.out.println("生成HNode结点:");
for(Iterator it=li.iterator();it.hasNext();) {
HNode tmp=it.next();
System.out.println(tmp);
}
System.out.println("遍历Huffman树:");
HNode root=createHuffmanTree(li);
preOrder(root);
Map HCodeTable=getCodes(root);
System.out.println("生成的哈夫曼编码表:"+HCodeTable);
String code=zip(s, HCodeTable);
System.out.println("生成的哈夫曼编码:"+code);
Map DeCodeTable=decodeTable(HCodeTable);
System.out.println("生成的哈夫曼解码表:"+DeCodeTable);
String decode=UnZip(code,DeCodeTable);
System.out.println("解码:"+decode);
}
//统计每个字符的权值,转为HNode,存入nodes
public static List getNodes(char[] chars){
List nodes=new ArrayList<>();
Map counts=new HashMap<>();
for(char c:chars){
Integer count=counts.get(c);
if(count==null){
counts.put(c, 1);
}
else{
counts.put(c, count+1);
}
}
//遍历Map,转为HNode存入nodes
for(Map.Entry entry: counts.entrySet()) {
nodes.add(new HNode(entry.getKey(), entry.getValue()));
}
return nodes;
}
//创建Huffman树
//构成赫夫曼树的步骤:
//1) 从小到大进行排序, 将每一个数据,每个数据都是一个节点 , 每个节点可以看成是一颗最简单的二叉树
//2) 取出根节点权值最小的两颗二叉树
//3) 组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和
//4) 再将这颗新的二叉树,以根节点的权值大小 再次排序, 不断重复 1-2-3-4 的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树
public static HNode createHuffmanTree(List nodes){
while(nodes.size()>1){
Collections.sort(nodes);
//取出最小的作为左结点
HNode leftNode=nodes.get(0);
//取出次小的结点作为右结点
HNode rightNode=nodes.get(1);
//新建一个结点作为父节点
HNode parent=new HNode(null,leftNode.weight+rightNode.weight);
//父节点指向两个子节点
parent.left=leftNode;
parent.right=rightNode;
//从nodes中删除leftNode和rightNode
nodes.remove(leftNode);
nodes.remove(rightNode);
//nodes中加上parent结点
nodes.add(parent);
}
return nodes.get(0);
}
//后续遍历
public static void preOrder(HNode root){
if(root!=null){
root.preOrder();
}
else{
System.out.println("该二叉树为空");
}
}
//编码
//1.得到编码表
//2.编码
static Map huffmanCodes=new HashMap();//使用Map保存编码表
/**生成哈夫曼树对应的编码
* @param root 哈夫曼根节点
* @return 哈夫曼编码表
*/
public static Map getCodes(HNode root){
if (root!=null){
getCodes(root,"",new StringBuilder());
}
else{
System.out.println("该二叉树为空");
}
return huffmanCodes;
}
/**
* 功能:将所有叶子结点的赫夫曼编码得到,并放入到huffmanCodes集合
* @param node
* @param code 左-0 右-1
* @param sb 用于拼接
*/
private static void getCodes(HNode node,String code,StringBuilder sb){
StringBuilder sb2 = new StringBuilder(sb);
//将code 加入到 stringBuilder2
sb2.append(code);
if(node != null) { //如果node == null不处理
//判断当前node 是叶子结点还是非叶子结点
if(node.data == null) { //非叶子结点
//递归处理
//向左递归
getCodes(node.left, "0", sb2);
//向右递归
getCodes(node.right, "1", sb2);
} else { //说明是一个叶子结点
//就表示找到某个叶子结点的最后
huffmanCodes.put(node.data, sb2.toString());
}
}
}
/**
* zip:将字符串按照编码表的编码规则转为HuffmanCode
* @param s 待压缩的字符串
* @param huffmanCodes 编码表
*/
public static String zip(String s,MaphuffmanCodes){
StringBuilder sb=new StringBuilder();
for(int i=0;i decodeTable(MaphuffmanCodes){
Map deCodeTable=new HashMap<>();
for(Entry entry: huffmanCodes.entrySet()) {
deCodeTable.put(entry.getValue(), entry.getKey());
}
return deCodeTable;
}
/**
* UnZip:将HuffmanCode按照解码表的编码规则转为字符串
* @param s
* @param decodeTable
*/
public static String UnZip(String s,Map decodeTable){
StringBuilder res=new StringBuilder(); //用于存储返回结果值
StringBuilder sb=new StringBuilder(); //用于存储当前解码的码值
for(int i=0;i{
Character data; //字符
int weight; //结点权值
HNode left; //指向左子节点
HNode right; //指向右子节点
public HNode(Character data, int weight) {
super();
this.data = data;
this.weight = weight;
}
@Override
public String toString() {
return "HNode [data=" + data + ", weight=" + weight + "]";
}
@Override
public int compareTo(HNode o) {
return this.weight-o.weight;
}
//后续遍历
public void preOrder(){
System.out.println(this);
//左子树
if(this.left!=null){
this.left.preOrder();
}
//右子树
if(this.right!=null){
this.right.preOrder();
}
}
}