大数据系列教程004-完全分布式环境搭建步骤
版权声明:大数据系列教程文章由Java潘老师辛苦原创,免费公开供java爱好者学习。如需转载请获得潘老师授权并保留原文链接,如有疑问或建议,可以联系潘老师:
Q:1562691348
V:A1562691348
本教程学习知识储备:Java SE基础、Linux基础、数据库基础
一.说明:
1、伪分布式环境是一台虚拟机,自身既是主节点又是从节点,即既是NameNode也是DataNode
2、完全分布式环境,需要多台虚拟机,这里我们使用一主两从配置
3、我们这里的分布式环境搭建基于之前的伪分布式master主机
二、具体步骤
1.再安装两台虚拟主机分别为slave1、salve2
2.设置静态和主机名,要求如下:
| 主机 |
主机名 |
ip |
| master |
master |
192.168.217.100 |
| slave1 |
slave1 |
192.168.217.101 |
| slave2 |
slave2 |
192.168.217.102 |
然后重启虚拟主机。
3.修改hosts文件需要注意:
3台虚拟机的hosts文件都需配置如下信息:
| 192.168.217.100 master 192.168.217.101 slave1 192.168.217.102 slave2 |

可以将master的修改好后,可以统一远程copy到slave1和slave2,使用指令:
| scp /etc/hosts root@slave1:/etc/hosts scp /etc/hosts root@slave2:/etc/hosts |
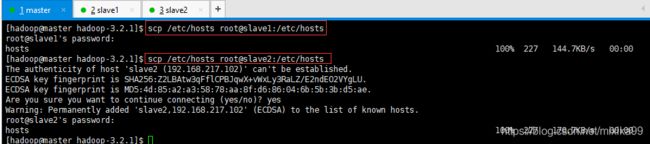
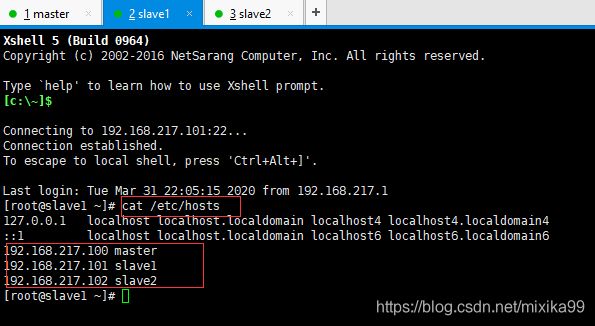
查看slave1和slave2的hosts:
4.永久关闭slave1和slave2的防火墙
注意:关闭setlinux也可以通过远程copy的方法
5.在slave1和slave2新建hadoop用户,注意用户名和密码必须都和master一致
注意:修改sudoers也可以通过远程copy的方法
6.设置3台机器的免密登录
注意1:最少要实现master向slave1和slave2的免密登录,也可以实现3者相互免密登录,不过有点多余,在此我们只实现master向slave1和slave2的免密登录
1)在slave1和slave2中分别使用自己的hadoop用户生成公私钥对
2) 在master中使用ssh-cpoy-id将master的公钥copy到slave1和slave2
| ssh-copy-id -i slave1 ssh-copy-id -i slave2 |
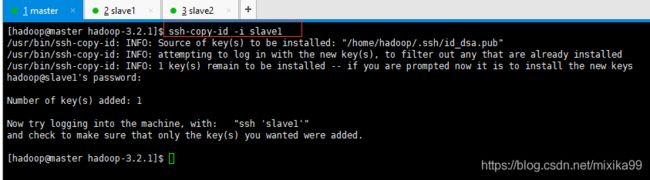
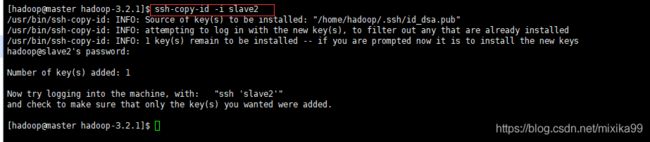
查看salve1和slave2:
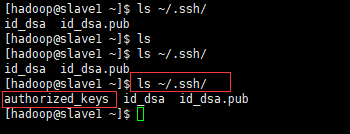
会多出authorized_keys文件
测试免密登录:
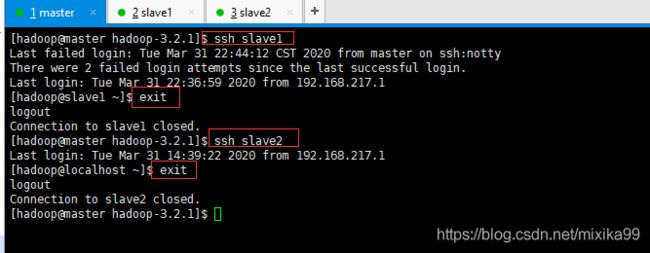
如果想相互通信,则可以将所有从节点的pub公钥copy到master,然后在master中将所有从节点的公钥内容cat到authorized_keys中,再将authorized_keys文件copy到所有从节点即可。
7.通过root用户远程复制jdk到slave1和slave2
| 安装包: scp -rq /usr/java/ slave1:/usr/ scp -rq /usr/java/ slave2:/usr/ 配置文件: scp -rq /etc/profile/ slave1:/etc/ scp -rq /etc/profile/ slave2:/etc/ 文件生效:在slave1和slave2中: source /etc/profile java -version |


耐心等待,不能Ctrl + c
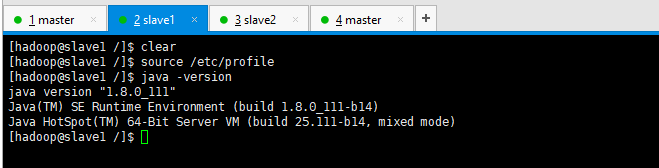
查看slave1和slave2的usr目录和profile
分别测试java -version
8.通过hadoop用户安装与配置hadoop
1)删除master原来的/usr/hadoop目录
| sudo rm -rf /usr/hadoop/ |

2)参考大数据系列教程003-hadoop伪分布式环境搭建步骤11-启动与验证环境
重新上传安装与配置
注意1:环境变量不需要再次配置
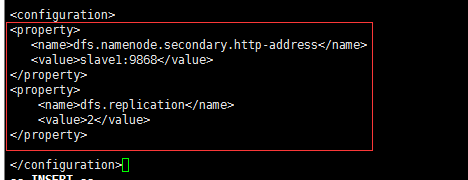
注意2:hdfs-site.xml文件的dfs.replication的value改为2,因为有两个datanode从节点
注意3:hdfs-site.xml再新增SecondaryName的启动路径,默认在主节点上,这里我们将其配置在slave1节点上
| |
注意4:yarn-site.xml再新增 resourcemanager启动位置
|
|
注意5:新增对workers文件配置,配置从节点主机名
| sudo vi workers |
原:
现:

注意4:将master的/usr/hadoop目录赋予777权限
| sudo chmod -R 777 /usr/hadoop |
3)将master上的hadoop目录远程copy到slave1和slave2上:
| sudo scp -rq /usr/hadoop/ slave1:/usr/ sudo scp -rq /usr/hadoop/ slave2:/usr/ |
时间比较长,需要耐心等待

9.启动验证
1)进入master主机目录:
| cd /usr/hadoop/hadoop-3.2.1 |
2)格式化hdfs文件系统
| bin/hdfs namenode -format |
注意:只需要格式化一次,不需要每次使用都格式化,如果格式化出错,最好先删除/usr/hadoop/hadoopdata目录再重新格式化
3)启动hadoop
| sbin/start-all.sh |

4)master执行jps命令,有如下进程:

slave1:
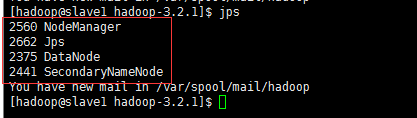
slave2:

5)也可以通过web ui进行访问查看
yarn:http://192.168.217.100:8088/cluster
master:http://192.168.217.100:9870
datanode1:http://192.168.217.101:9864
datanode2:http://192.168.217.102:9864
6)停止hadoop
| sbin/stop-all.sh |