深入分析zookeeper(理论加实战)
本文目录
- 一、zookeeper基础
- 1.1、什么是zookeeper?
- 1.2、文件系统
- 1.2、监听通知机制
- 二、实际生产中的作用
- 2.1、配置管理
- 2.2、统一命名服务
- 2.3、分布式锁
- 2.4、集群管理等服务
- 三、纸上得来总觉浅,zookeeper实战
- 3.1、使用docker安装zookeeper最新版
- 3.1.1、下载zookeeper镜像
- 3.1.2、启动容器并暴露2181端口
- 3.1.3、查看容器状态
- 3.1.4、一起来玩一些基本命令操作
- 3.2、使用idea配置zookeeper plugin
- 3.3、Talk is cheap ,Show me the code
- 3.3.1、首先把三种客户端的maven依赖搞进来
- 3.3.2、 原生zookeeper基本操作demo
- 3.3.3、开源的zkClinet基本操作demo
- 3.3.4、Apache Curator基本操作demo
- 四、补充一点相关面试题
一、zookeeper基础
1.1、什么是zookeeper?
先来看下zookeeper的图标:

很帅有没有。。。
zookeeper这个单词本身是动物管理员的意思,也就是负责管理动物的岗位,学大数据的应该都熟悉几个动物—Hadoop(会飞的大象)、Hive(小蜜蜂)、Flink(超人松鼠)以及可爱的pig(佩奇)等等等。那这个管理员是怎么管理这些小动物的呢,管理他们的哪些方面呢?
在大数据环境下或者更准确的说是在分布式环境下,zookeeper可以说无处不在。它是Google的Chubby一个开源的实现,是一个分布式的、开源的程序协调服务,是 hadoop 项目下的一个子项目。它主要提供了配置管理、统一命名服务、分布式锁、集群管理等服务。
从架构设计上来看,zookeeper主要分为两部分,文件系统和监听通知机制。
1.2、文件系统
文件系统顾名思义就是一个多层级的类似咱们电脑上的文件夹之类的数据结构,如下图所示:
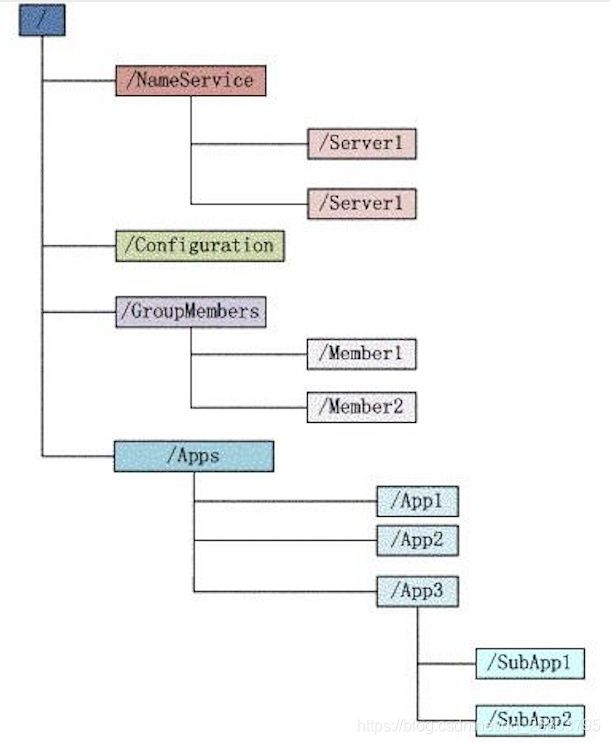
每个子目录项如 NameService 都被称作为 znode(这里NameService属于目录节点),和平常使用的文件夹一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode。当然znode有自己独特的地方,也就是它的这些znode可以用来设置关联的数据,具体就是只有文件节点可以存放数据而目录节点不可以。同时为了保证高吞吐低延迟,zookeeper需要在内存中维护这个树状的目录结构,因此zookeeper不能存放大量的数据,每个节点的存放数据上限是1M。
zookeeper一共有四个类型的znode节点:
-
PERSISTENT 持久化节点
持久化节点是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点。否则不会因为创建该节点的客户端会话失效而消失。
-
PERSISTENT_SEQUENTIAL 持久顺序节点
持久顺序节点和持久化节点的基本特征是一致的。只是它额外的特性是:在zookeeper中,每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序。基于这个特性,我们在创建子节点的时候,可以设置这个属性,这样在创建节点过程中,zookeeper会自动为这个节点名加上一个数字后缀作为新的节点名。 这个数字后缀的范围是整型的最大值。 比如在创建节点的时候只需要传入节点 “csdn_”,然后zookeeper自动会给”csdn_”后面补充数字。
-
EPHEMERAL 临时节点
和持久节点不同的是,临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。(注意:这里提到的是会话失效,而非连接断开)另外,在临时节点下面不能创建子节点。 这里还要注意一件事,就是当你客户端会话失效后,所产生的节点并不是瞬间就消失了,而是需要一段时间,大概是 10 秒以内。例如,本机操作生成节点,在服务器端用命令来查看当前的节点数目,你会发现客户端已经 stop,但是产生的节点还在。
-
EPHEMERAL_SEQUENTIAL 临时自动编号节点
属于带有顺序的临时节点,在客户端会话结束后节点就消失。
1.2、监听通知机制
简单来说就是客户端会对某个znode建立一个watcher事件,当这个znode发生了变化,比如数据改变、删除、子目录节点新增删除等情况时,客户端会收到zookeeper的通知,然后好处就是客户端就可以根据znode的变化来调整对应的业务情况。
二、实际生产中的作用
2.1、配置管理
通过前面介绍zookeeper的数据结构,相信很多人首先想到的就是它可以解决各种需要同步的麻烦的配置。比如数据库连接等。一般我们都是使用配置文件的方式,在代码中引入这些配置文件。当我们只有一种配置,只有一台服务器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多, 有很多服务器都需要这个配置,这时使用配置文件就不是个好主意了。这个时候往往需要寻找一种集中管理配置的方法,就是希望我们在这个集中的地方修改了配置,然后所有使用这个配置的服务器上的服务都可以获得变更。
Zookeeper就是这种服务,它使用Zab这种一致性协议来提供一致性。
其实有很多开源项目都是使用 Zookeeper 来维护配置,比如在HBase中,本来内置的就有zookeeper,也可以使用外部的zookeeper。它的客户端就是通过连接一个Zookeeper,获得必要的 HBase 集群的配置信息,然后才可以进一步操作。
再比如实际生产中必不可少的开源的消息队列Kafka,也是使用 Zookeeper来维护broker的信息。还有Alibaba开源的SOA框架Dubbo中也是通过使用Zookeeper管理一些配置来实现服务治理的。
2.2、统一命名服务
统一命名服务比较容易理解,就像DNS一样,由于我们访问网络时直接输入IP地址非常不友好(记不住),因此诞生了域名,但是域名也不是每台计算机都保存的,我们不可能在每台计算机上保存全世界所有的域名和IP的映射。因此DNS诞生了,我们只需要固定的访问一个大家都熟知的服务器(根服务器),它就会告诉你这个域名对应 的 IP 是什么(根服务器一般会根据域名的构成来指向一级、二级服务器层层去寻找这个域名对应的IP)。
在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候,如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都熟知的访问点,然后从这里提供统一的入口,那么维护起来将方便得多了。
2.3、分布式锁
zookeeper本质上是一个分布式协调服务。因此我们可以利用zookeeper来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服 务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进行操作,那又存在单点故障风险。
因此通常情况下我们的做法就是使用分布式锁,在某个时刻只让一个服务去干活,当这台服务出故障的时候把锁释放掉,并立即fail over到别的服务。这在很多分布式系统中都是这么做,这种设计有一个更好听的名字叫 Leader Election(leader 选举)。比如 HBase 的 Master 就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所以使用的时候要比同一个进程里的锁更谨慎的使用。
2.4、集群管理等服务
在现在大数据的场景及微服务的场景下,由于是分布式的集群,经常会由于各种原因,比如硬件故障,软件故障,网络问题等,导致部分节点进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机器需要感知到这种变化,然后根据这种变化做出对应的决策。
比如我们是一个分布式存储系统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。
再比如一个分布式的 SOA 架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如Alibaba开源的SOA框架Dubbo就采用了Zookeeper作为服务发现的底层机制)。还有常用的Kafka 队列就采用了Zookeeper作为Cosnumer的上下线管理。
三、纸上得来总觉浅,zookeeper实战
3.1、使用docker安装zookeeper最新版
为啥使用docker安装呢?因为我个人觉得学习一门技术主要是要掌握它的原理、架构、以及具体的使用,而不是纠结于安装配置。(其实是因为懒。。。。)
好,docker不管在任何系统下安装任何东西步骤都一样:
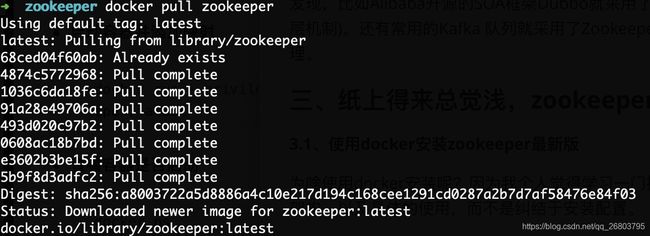
3.1.1、下载zookeeper镜像
docker pull zookeeper
3.1.2、启动容器并暴露2181端口
docker run --privileged=true -d --name zookeeper --publish 2181:2181 -d zookeeper:latest
![]()
3.1.3、查看容器状态
docker ps

可以看到,我这个zookeeper已经连续启动19个小时了(这篇文章比较费时间)。
3.1.4、一起来玩一些基本命令操作
-
以bin/bash进入到容器中
docker exec -it 60d /bin/bash -
以本地2181客户端连接zk,进行命令行界面
./zkCli.sh -server 127.0.0.1:2181 -
以bin/bash进入到容器中
docker exec -it 60d /bin/bash -
启动和关闭zookeeper(默认容器开启后是启动的)
#启动zookeeper服务 ./zkServer.sh start #关闭zookeeper服务 ./zkServer.sh stop #查看zookeeper运行状态 ./zkServer.sh status -
以本地2181客户端连接zk,进行命令行界面
./zkCli.sh -server 127.0.0.1:2181 -
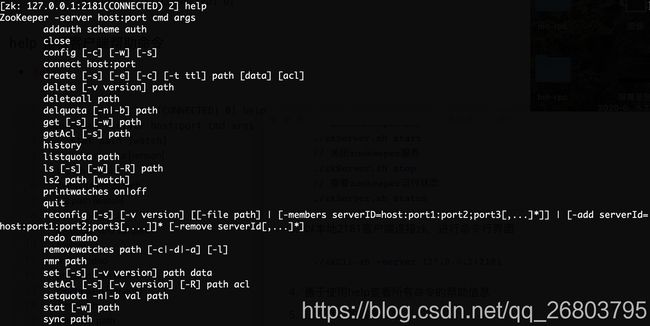
善于使用help查看所有命令的帮助信息
-
通过上面的help命令,我们已经知道了常用命令有哪些,下面让我们实战一下基本的常用操作
-
ls 查看,create 新增,get 获取节点数据
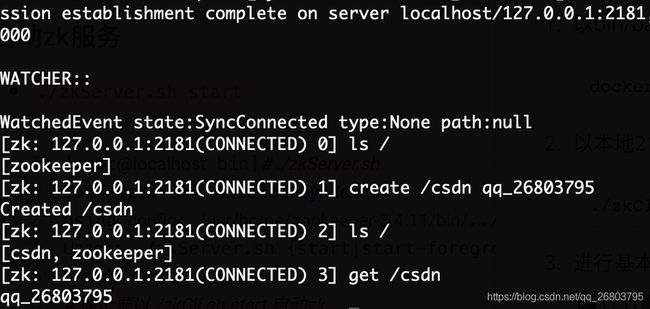
上图命令解析如下:# 查看根下有哪些znode节点(可以理解为目录) ls / # 在根下新增一个名为csdn的节点,并赋予数据qq_26803795(我的csdn号) # 注意:create 后面可以跟参数 create [-s] [-e] path data acl # -s 代表sequence,也就是创建顺序节点,可以自动累加 # -e 代表创建临时节点 create /csdn qq_26803795 # 再次查看根下有哪些znode节点 ls / # 获取csdn节点的数据信息 get /csdn -
stat 获取节点的更新信息,ls2 是ls和stat两个命令的整合(但是请注意,ls2命令已经不建议使用,官方在新版zookeeper建议使用ls -s 来替代ls2)
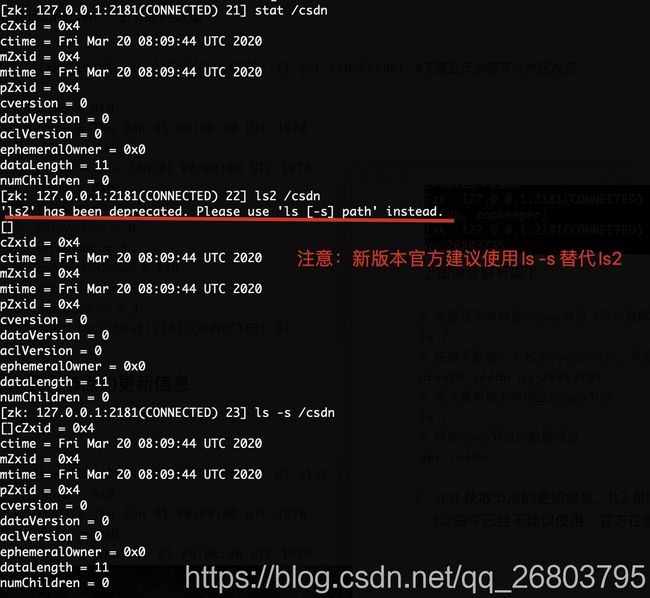
-
set修改节点
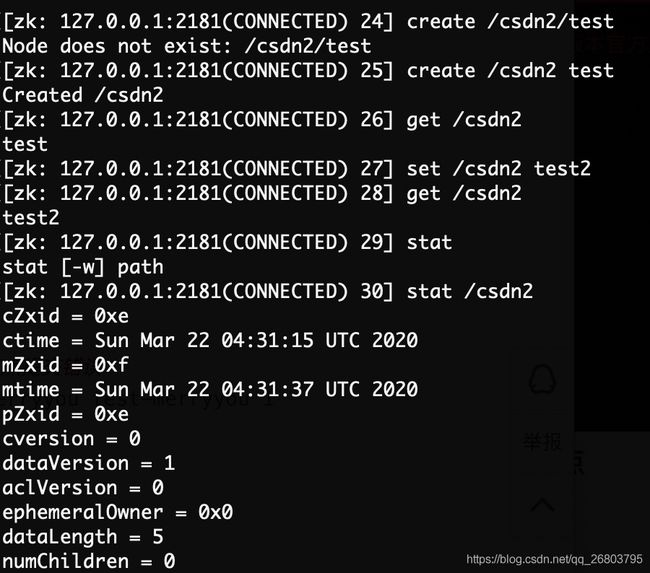
首先上图是新建了一个csdn2的节点并赋值test,随后使用了set对这个节点的值进行了更改,当然这个操作也可以伴随着dataVersion使用。 -
delete 删除节点
如下图,我们把csdn2节点删除掉:

-
3.2、使用idea配置zookeeper plugin
强大的idea提供了一个zookeeper的插件,可以用来连接zookeeper及查看内容。
- windows:左上角File------>Settings------>Plugins
- Mac:左上角Intellij IDEA------>Preserences------>Plugins
在plugin里输入zoo,然后选择第二个zoolytic并点击install进行安装(第一个zookeeper在新版idea里已经不能用了,已踩坑。。。。),如下图:
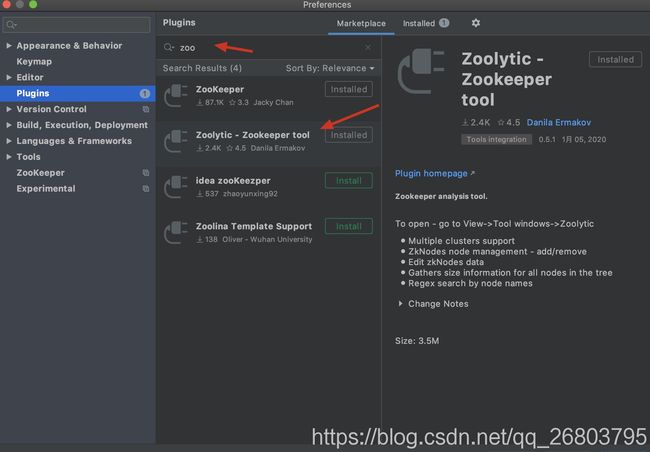
安装后重启idea
然后在点击右上角zoolytic,打开后,点击➕号,然后在弹框中输入localhost:2181,最后点击ok,如下图:
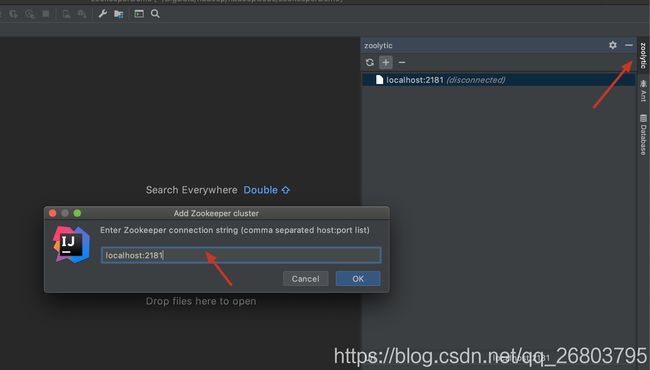
在列表里点击刚才的localhost:2181,展开后,点击connect,如下图:
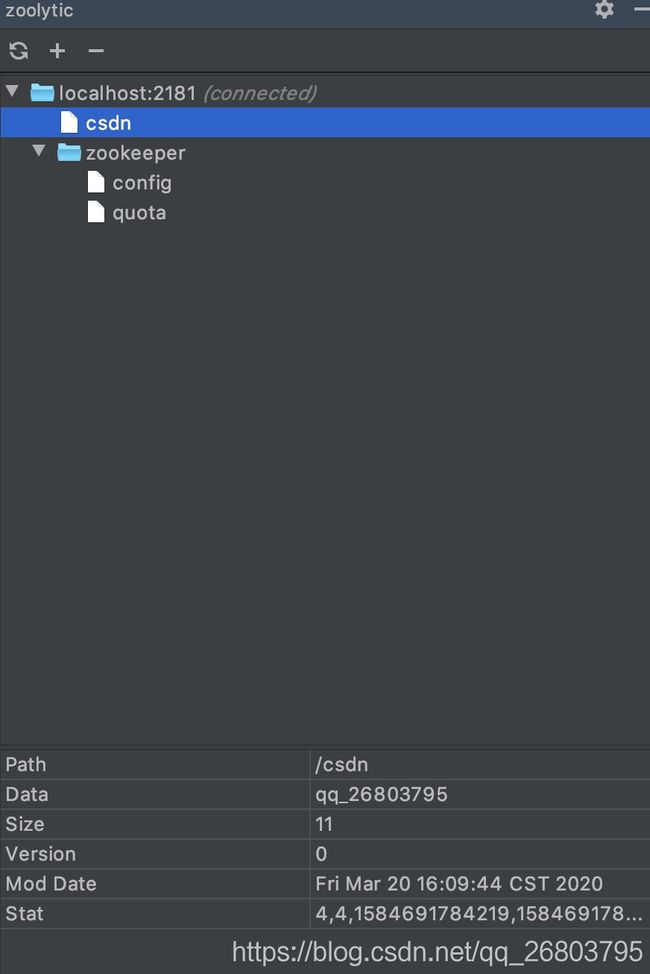
然后就会出现咱们刚才新增的csdn节点,并且这个节点上的数据qq_26803795(这是我的csdn ID)也会出现,如下图:
感兴趣的可以好好的把玩一番。
3.3、Talk is cheap ,Show me the code
只会这些命令行或者利用插件可视化操作显然是不够的,所以接下来就是掉头发的时间了。。。。
首先zookeeper提供了3种常用的客户端api,分别是:原生zookeeper(官方,较底层,不推荐使用)、Apache Curator(最完美,推荐大家使用)以及开源的zkClient,这些客户端的优缺点对比,待会看下代码就清楚了。
3.3.1、首先把三种客户端的maven依赖搞进来
下面是我的pom.xml文件内容:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>zookeeperDemoTestartifactId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.5.7version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>2.9.0version>
dependency>
<dependency>
<groupId>com.101tecgroupId>
<artifactId>zkclientartifactId>
<version>0.9version>
dependency>
dependencies>
project>
3.3.2、 原生zookeeper基本操作demo
首先zookeeper官方提供的原生api比较偏底层,zookeeper类对象除了需要zookeeper服务端连接IP:端口,还必须要提供一个watcher对象(监听器)。watcher是一个接口,当服务器znode节点花发生变化就会以事件的形式通知watcher对象。所以Watcher常用来监听节点,当节点发生变化时客户端就会监听到。
zookeeper类提供的对节点进行增删改查的主要方法介绍如下:
- create:用于创建节点,可以指定节点路径、节点数据、节点的访问权限、节点类型
- delete:删除节点,每个节点都有一个版本,删除时可指定删除的版本,类似乐观锁。设置-1,则就直接删除节点。
- exists:节点存不存在,若存在返回节点Stat信息,否则返回null
- getChildren:获取子节点
- getData/setData:获取节点数据
- getACL/setACL:获取节点访问权限列表,每个节点都可以设置访问权限,指定只有特定的客户端才能访问和操作节点。
下面写一个demo测试一下:
import org.apache.zookeeper.*;
import java.io.IOException;
public class ZookeeperDemo {
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
//连接zookeeper并且注册监听器
ZooKeeper zk = new ZooKeeper("127.0.0.1:2181", 3000, new Watcher() {
public void process(WatchedEvent watchedEvent) {
System.out.println(watchedEvent.toString());
}
});
System.out.println("OK!");
// 创建一个目录节点
/**
* CreateMode:
* PERSISTENT (持续的,相对于EPHEMERAL,不会随着client的断开而消失)
* PERSISTENT_SEQUENTIAL(持久的且带顺序的)
* EPHEMERAL (短暂的,生命周期依赖于client session)
* EPHEMERAL_SEQUENTIAL (短暂的,带顺序的)
* 节点访问权限说明:
* 节点访问权限由List确定,但是有几个便捷的静态属性可以选择:
* Ids.CREATOR_ALL_ACL:只有创建节点的客户端才有所有权限\
* Ids.OPEN_ACL_UNSAFE:这是一个完全开放的权限,所有客户端都有权限
* Ids.READ_ACL_UNSAFE:所有客户端只有读取的
*/
zk.create("/zookeeperDemo", "RopleData".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 创建一个子目录节点
zk.create("/zookeeperDemo/type1", "RopleData/type1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println(new String(zk.getData("/zookeeperDemo", false, null)));
// 取出子目录节点列表
System.out.println(zk.getChildren("/zookeeperDemo", true));
// 创建另外一个子目录节点
zk.create("/zookeeperDemo/type2", "RopleData/type2".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println(zk.getChildren("/zookeeperDemo", true));
// 修改子目录节点type1的数据
zk.setData("/zookeeperDemo/type1", "RopleData/type3".getBytes(), -1);
byte[] datas = zk.getData("/zookeeperDemo/type1", true, null);
String str = new String(datas, "utf-8");
System.out.println(str);
// 删除整个子目录 -1代表version版本号,-1是删除所有版本
// zk.delete("/zookeeperDemo/type1", -1);
// zk.delete("/zookeeperDemo/type2", -1);
// zk.delete("/zookeeperDemo", -1);
// System.out.println(str);
Thread.sleep(10000);
zk.close();
System.out.println("OK");
}
}
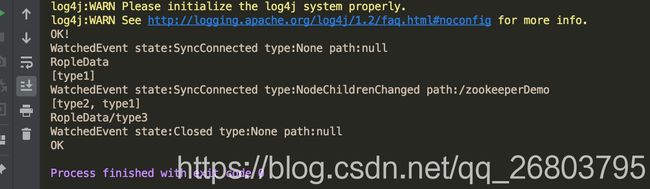
运行结果为:
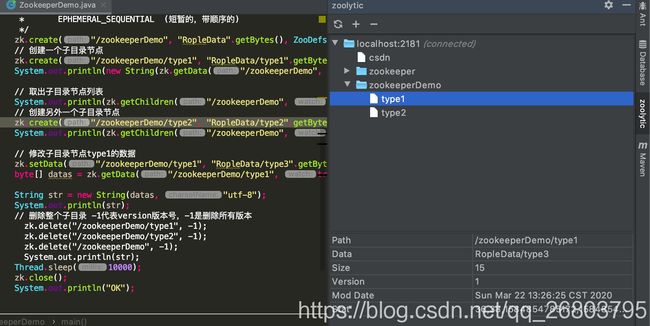
然后我们通过zoolytic可视化查看节点数据信息:
3.3.3、开源的zkClinet基本操作demo
zkClient提供了许多封装好的api方法,操作简便直观,下面我们举个简单的例子:
import org.I0Itec.zkclient.ZkClient;
import org.apache.zookeeper.CreateMode;
public class ZKclientDemo {
public static void main(String[] args) throws Exception {
ZkClient zkClient = new ZkClient("127.0.0.1:2181");//建立连接
zkClient.create("/zkClientDemo", "RopleData", CreateMode.PERSISTENT);//创建目录并写入数据
// 获取节点数据并输出
String data = zkClient.readData("/zkClientDemo");
System.out.println(data);
//zkClient.delete("/zkClientDemo");//删除目录
//zkClient.deleteRecursive("/zkClientDemo");//递归删除节目录
}
}
运行结果:
RopleData
然后查看zoolytic:
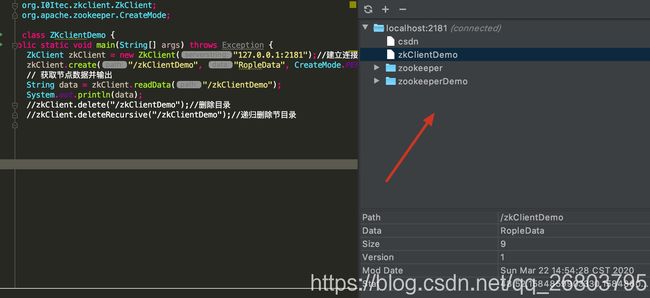
3.3.4、Apache Curator基本操作demo
最后介绍一下最方便的curator的基本操作,想深入掌握的同学可以去apache curator的官网深入研究:Apache Curator的官方文档。
首先介绍curator的几个组成部分:
- Client: 是ZooKeeper客户端的一个替代品, 提供了一些底层处理和相关的工具方法
- Framework: 用来简化ZooKeeper高级功能的使用, 并增加了一些新的功能, 比如管理到ZooKeeper集群的连接, 重试处理
- Recipes: 实现了通用ZooKeeper的recipe, 该组件建立在Framework的基础之上
- Utilities:各种ZooKeeper的工具类
- Errors: 异常处理, 连接, 恢复等
- Extensions: recipe扩展
了解了这些理论其实也没什么用(容易忘),还是自己多操作一下体会的更深:
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.api.CuratorWatcher;
import org.apache.curator.retry.RetryNTimes;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.ZooDefs;
import java.util.List;
public class CuratorDemo {
public static void main(String[] args) throws Exception {
CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181", new RetryNTimes(10, 2000));
client.start();// 连接zookeeper服务器
// 获取子节点,并进行监控
List<String> children = client.getChildren().usingWatcher(new CuratorWatcher() {
public void process(WatchedEvent event) throws Exception {
System.out.println("监控: " + event);
}
}).forPath("/");
System.out.println(children);
// 创建节点
String result = client.create().withMode(CreateMode.PERSISTENT).withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE).forPath("/curatorDemo", "RopleData".getBytes());
System.out.println(result);
// 设置节点数据
client.setData().forPath("/curatorDemo", "NewRopleData".getBytes());
// 删除节点
//System.out.println(client.checkExists().forPath("/curatorDemo"));
// client.delete().withVersion(-1).forPath("/curatorDemo");
// System.out.println(client.checkExists().forPath("/curatorDemo"));
client.close();
System.out.println("OK!");
}
}
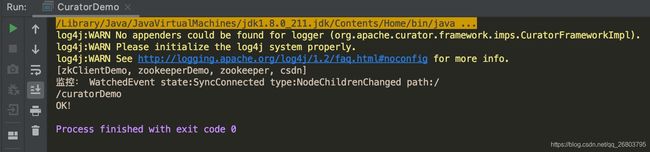
运行结果:
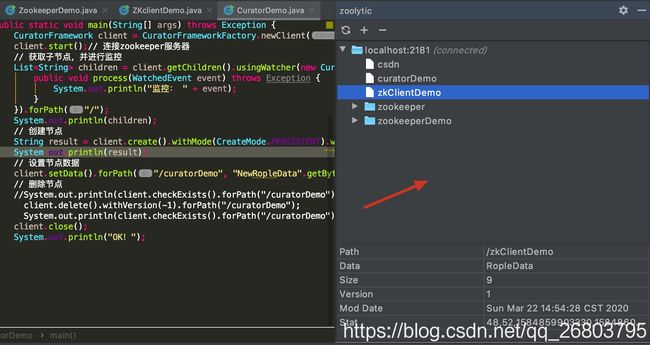
我们再次使用zoolytic查看结果:
所有代码已上传到我的github,感兴趣的可以的下载查看:RopleData
四、补充一点相关面试题
-
zookeeper底层算法是Fast Paxos算法,它的前身Paxos算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,后来Fast Paxos进行了一些优化,通过选举产生一个leader (领导者),只有leader才能提交proposer;
-
zookeeper选举机制采用半数机制,当整个集群中有某台服务器节点获得了超过半数的投票,那它就会成为leader:
半数机制:2n+1
在实际生产中根据集群规模安装zookeeper台数经验如下:(左为集群规模,右为zookeeper规模)
10 台服务器:3 台zookeeper
20 台服务器:5 台zookeeper
100 台服务器:11 台zookeeper
-
zookeeper规模并不是越多越好,因为当zookeeper规模太多时,较长的选举时间反而会影响性能。