hadoop2.6.5完全分布式搭建(HA)
集群部署(在完全分布式搭建完成后进行的局部修改)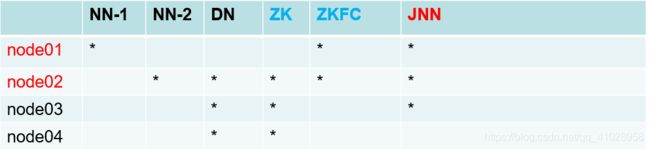
搭建zookeeper集群
解压
[root@node02 ~]# tar -zxvf zookeeper-3.4.6.tar.gz
[root@node02 ~]# mv zookeeper-3.4.6 /opt/hadoop/配置环境变量 (node02,node03,nodeo4都需要配置环境变量)
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_HOME=/opt/hadoop/hadoop-2.6.5
export ZOOKEEPER_HOME=/opt/hadoop/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
![]()
重命名
[root@node02 conf]# pwd
/opt/hadoop/zookeeper-3.4.6/conf
[root@node02 conf]# cp zoo_sample.cfg zoo.cfg[root@node02 conf]# vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/var/hadoop/zk
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=192.168.106.22:2888:3888
server.2=192.168.106.23:2888:3888
server.3=192.168.106.24:2888:3888
创建目录追加ID
[root@node02 conf]# mkdir -p /var/hadoop/zk
[root@node02 conf]# echo 1 > /var/hadoop/zk/myid
分发zookeeper包给node03,node04
[root@node02 hadoop]# scp -r ./zookeeper-3.4.6/ node03:/opt/hadoop/
[root@node02 hadoop]# scp -r ./zookeeper-3.4.6/ node04:/opt/hadoop/
在node03,node04创建目录,追加id
[root@node03 hadoop]# mkdir -p /var/hadoop/zk
[root@node03 hadoop]# echo 2 > /var/hadoop/zk/myid
[root@node04 ~]# mkdir -p /var/hadoop/zk
[root@node04 ~]# echo 3 > /var/hadoop/zk/myid
开启zookeeper集群
[root@node02 hadoop]# zkServer.sh start
[root@node03 hadoop]# zkServer.sh start
[root@node04 hadoop]# zkServer.sh start
配置HDSF
[root@node01 hadoop]# vi hdfs-site.xml
dfs.replication
2
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
node01:8020
dfs.namenode.rpc-address.mycluster.nn2
node02:8020
dfs.namenode.http-address.mycluster.nn1
node01:50070
dfs.namenode.http-address.mycluster.nn2
node02:50070
dfs.namenode.shared.edits.dir
qjournal://node01:8485;node02:8485;node03:8485/mycluster
dfs.journalnode.edits.dir
/var/hadoop/ha/jn
dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
dfs.ha.automatic-failover.enabled
true
[root@node01 hadoop]# vi core-site.xml
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/var/hadoop/ha
ha.zookeeper.quorum
node02:2181,node03:2181,node04:2181
分发配置文件

ZKFC使用密钥(node01,node02相互通信)
[root@node02 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
[root@node02 ~]# cd .ssh
[root@node02 .ssh]# ll
total 20
-rw-r--r-- 1 root root 601 Jan 8 22:25 authorized_keys
-rw------- 1 root root 668 Jan 9 01:02 id_dsa
-rw-r--r-- 1 root root 601 Jan 9 01:02 id_dsa.pub
-rw-r--r-- 1 root root 1197 Jan 9 00:33 known_hosts
-rw-r--r-- 1 root root 601 Jan 8 22:25 node01.pub
[root@node02 .ssh]# cat id_dsa.pub >> authorized_keys
[root@node02 .ssh]# ssh node02
[root@node02 ~]# exit
logout
Connection to node02 closed.
[root@node02 .ssh]# scp id_dsa.pub node01:/root/.ssh/node02.pub
root@node01's password:
id_dsa.pub 100% 601 0.6KB/s 00:00
[root@node01 .ssh]# ll
-rw-r--r-- 1 root root 1202 Jan 9 01:04 authorized_keys
-rw------- 1 root root 668 Jan 8 19:23 id_dsa
-rw-r--r-- 1 root root 601 Jan 8 19:23 id_dsa.pub
-rw-r--r-- 1 root root 2003 Jan 8 22:30 known_hosts
-rw-r--r-- 1 root root 601 Jan 9 01:04 node02.pub
[root@node01 .ssh]# cat node02.pub >> authorized_keys
[root@node02 .ssh]# ssh node01
Last login: Tue Jan 8 22:54:27 2019 from 192.168.106.1
[root@node01 ~]# exit


开启journalnode
[root@node01 ~]# hadoop-daemon.sh start journalnode
[root@node02 ~]# hadoop-daemon.sh start journalnode
[root@node03 ~]# hadoop-daemon.sh start journalnode格式化
![]()

启动namenode
[root@node01 ~]# hadoop-daemon.sh start namenode
[root@node02 ~]# hdfs namenode -bootstrapStandby
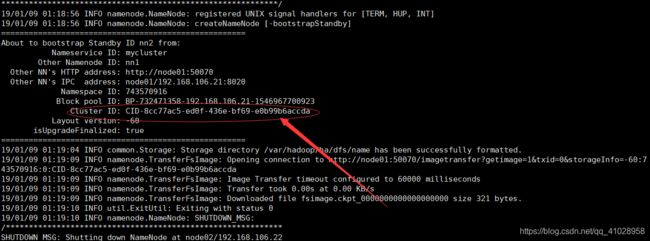
格式化ZK
![]()


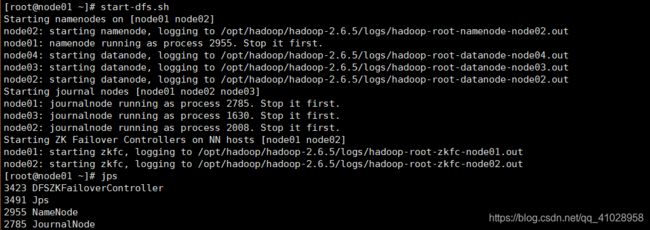
开启集群
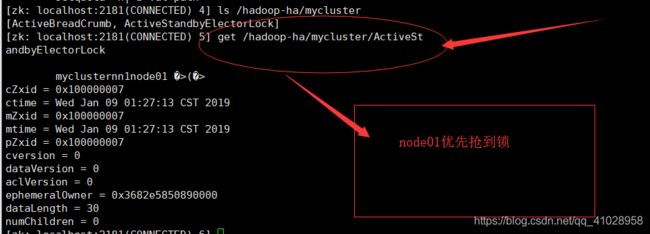
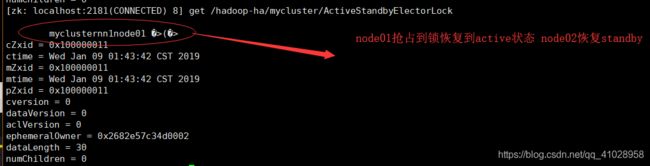
查看zookeeper目录树中的信息(锁的相关信息)
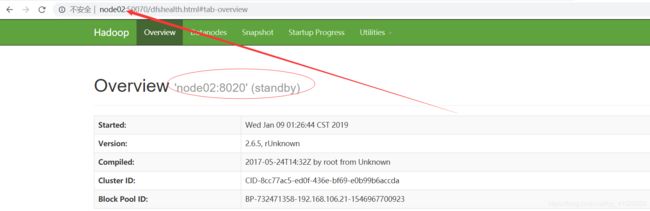
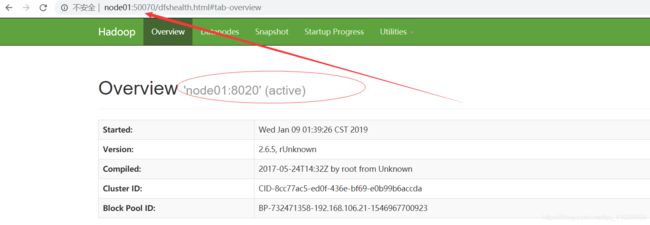
通过web页面进行访问


模拟HA操作(name和zkfc分别挂了进行模拟操作)
先杀死namenode

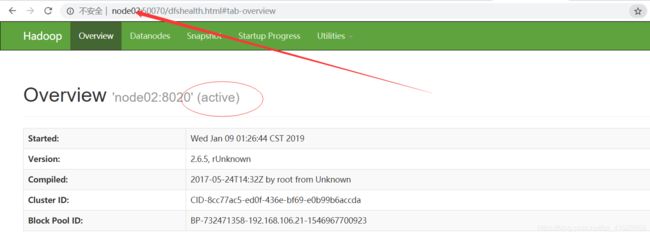

把namenode进行恢复重启

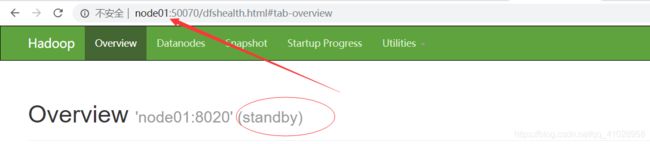
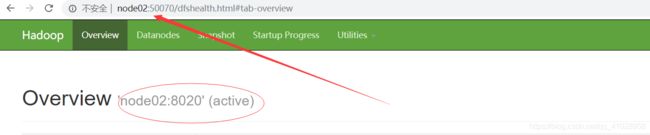

zkfc挂掉

重新开启ZKFC



ZKFC原理:(进行监控)
谁被杀死了对应节点就会被删掉 触发事件 进行(状态)切换