五分钟让你搞懂Nginx负载均衡原理及四种负载均衡算法
前言
今天这篇文章介绍了负载均衡的原理以及对应的四种负载均衡算法,当然还有对应的指令及实战,欢迎品尝。有不同意见的朋友可以评论区留言!
负载均衡
所谓负载均衡,就是 Nginx 把请求均匀的分摊给上游的应用服务器,这样即使某一个服务器宕机也不会影响请求的处理,或者当应用服务器扛不住了,可以随时进行扩容。

Nginx 在 AKF 可扩展立方体上的应用

- 在 x 轴上,可以通过横向扩展应用服务器集群,Nginx 基于 Round-Robin 或者 Least-Connected 算法分发请求。但是横向扩展并不能解决所有问题,当数据量大的情况下,无论扩展多少台服务,单台服务器数据量依然很大。
- 在 y 轴上,可以基于 URL 进行不同功能的分发。需要对 Nginx 基于 URL 进行 location 的配置,成本较高。
- 在 z 轴上可以基于用户信息进行扩展。例如将用户 IP 地址或者其他信息映射到某个特定的服务或者集群上去。
这就是 Nginx 的负载均衡功能,它的主要目的就是为了增强服务的处理能力和容灾能力。
反向代理
反向代理和负载均衡在某种程度上是密不可分的。
Nginx 支持多种协议的反向代理。四层的反向代理比较简单,无论是 UDP 还是 TCP 的流量过来,转发到上游的依然是 UDP 或 TCP 的流量。
而到了应用层时,就不太相同了,因为 HTTP 的 Header 中包含了大量的业务信息,需要根据 HTTP 的头部转换成不同的协议。
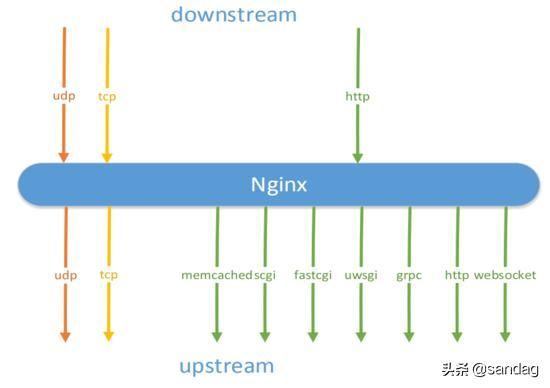
反向代理与缓存
缓存这个问题分为两类,一类是时间缓存,一类是空间缓存。
- 时间缓存是指,当用户请求一个页面的时候,Nginx 发现没有缓存,就会到后端服务器去取,在返回给用户响应的同时还会缓存一份,这样当下一个用户去请求的时候就会直接用缓存作为响应而不会再去请求上游的服务器。
- 空间缓存这种用的比较少,主要是指当用户发来请求的时候,Nginx 可以提前去上游服务器获取一些响应的内容,这个后面可以看到是怎么用的。
upstream 与 server 指令
指令name 表示负载均衡集群的名字,而 {} 内指定了一系列的服务器server 后跟服务器地址,地址后还可以加一些参数 parameters
Syntax: upstream name { ... }
Default: —
Context: http
Syntax: server address [parameters];
Default: —
Context: upstream - 功能:指定一组上游服务器地址,地址可以是域名、IP 地址或者 Unix Socket 地址。可以在域名或者 IP 地址后加端口,如果不加端口,那么默认使用 80 端口。
- 通用参数:server 后可以添加的参数backup:指定当前 server 为备份服务,仅当非备份 server 不可用时,请求才会转发到该 server表示某台服务已经下线,不再服务
负载均衡算法
加权 Round-Robin 负载均衡算法
Round-Robin(rr) 负载均衡算法发给上游服务器的请求是轮询发送的,相当于所有上游服务器根据顺序依次处理发来的请求。
有些情况下上游服务器性能不同,比如 4C8G 和 8C16G 的服务器都有,那么这时候就可以对服务器设置一些权重,让性能好的承担更多的请求。
功能在加权轮询的方式访问 server 指令指定的上游服务集成在 Nginx 的 upstream 框架中,无法移除
指令weight:服务访问的权重,默认是 1max_conns:server 的最大并发连接数,仅作用于单 worker 进程。默认是 0,表示没有限制max_fails:在 fail_timeout 时间段内,最大的失败次数。当达到最大失败时,会在 fail_timeout 秒内这台 server 不允许再次被选择fail_timeout:单位是秒,默认 10 秒,可以指定一段时间内最大失败次数 max_fails 以及到达 max_fails 之后该 server 不能访问的时间
对上游服务使用 keepalive 长连接
Nginx 与上游服务一般是在内网中的,所以开启 keepalive 后效果后更明显。
- 功能:通过复用连接,降低 Nginx 与上游服务器建立、关闭连接的消耗,提升吞吐量的同时降低时延
- 模块: ngx_http_upstream_keepalive_module 默认编译进 Nginx,通过 --without-http_upstream_keepalive_module 移除
对上游服务器的 HTTP 头部设定
Syntax: keepalive connections;
Default: —
Context: upstream
# 1.15.3 非稳定版本新增命令
Syntax: keepalive_requests number;
Default: keepalive_requests 100;
Context: upstream
Syntax: keepalive_timeout timeout;
Default: keepalive_timeout 60s;
Context: upstream
keepalive connections; 指定上游服务域名解析的 resolver 指令
当使用域名访问上游服务时,可以指定一个 DNS 解析的地址,还可以设置超时等,这个时候就要用到 resolver 指令。
Syntax: resolver address ... [valid=time] [ipv6=on|off];
Default: —
Context: http, server, location
Syntax: resolver_timeout time;
Default: resolver_timeout 30s;
Context: http, server, location 实战
下面我起了两个 Nginx 的进程,一个作为上游服务器,监听 8011 和 8012 端口,另一个作为反向代理向上游服务器发请求。
上游服务器的配置如下,当请求是到达 8011 端口就返回 8011 server response. ,当请求到达 8012 端口返回 8012 server response. 。
server {
listen 8011;
default_type text/plain;
return 200 '8011 server response.\n';
}
server {
listen 8012;
default_type text/plain;
# client_body_in_single_buffer on;
return 200 '8012 server response.\n';
} 作为反向代理的 Nginx 服务器配置是这个样子的:
这里面 8011 端口和 8012 端口的区别在于 8011 端口设置了权重和对应的参数。
upstream rrups {
server 127.0.0.1:8011 weight=2 max_conns=2 max_fails=2 fail_timeout=5;
server 127.0.0.1:8012;
keepalive 32;
}
server {
server_name rrups.ziyang.com;
error_log myerror.log info;
location /{
proxy_pass http://rrups;
proxy_http_version 1.1;
proxy_set_header Connection "";
} 两个 Nginx 都配置好之后,来测试一下:
➜ nginx curl rrups.ziyang.com
8011 server response.
➜ nginx curl rrups.ziyang.com
8011 server response.
➜ nginx curl rrups.ziyang.com
8012 server response. 由于 8011 端口的权重设置的是 2,所以根据 rr 算法,每次都是先两个连接负载到 8011 端口上然后是 8012 端口。
这一节讲了 rr 负载均衡算法,rr 算法是所有负载均衡算法的基础,在其他负载均衡算法失效的情况下,Nginx 也会使用 rr 算法进行负载均衡。
负载均衡哈希算法,ip_hash 与 hash 模块
rr 轮询算法没有办法保证请求由某一台指定的服务器去处理,只能轮询处理请求,在 AKF 立方体中只能在 x 轴方向上进行水平扩展。如果基于 z 轴扩展,就可以采用哈希算法保证某一类请求只由特定的服务器处理。
- 功能:以客户端的 IP 地址作为 hash 算法的关键字,映射到特定的上游服务器中对 IPv4 地址使用前 3 个字节作为关键字,对 IPv6 则使用完整地址可以使用 rr 算法的参数可以基于 realip 模块修改用于执行算法的 IP 地址
- 模块: ngx_http_upstream_ip_hash_module ,通过 --without-http_upstream_ip_hash_module 禁用模块
指令的话比较简单,就是 ip_hash 出现在 upstream 上下文中。
Syntax: ip_hash;
Default: —
Context: upstream
这里面不得不提到的一个模块就是 realip 模块,哈希算法是根据 remote_addr 这个变量的值来进行哈希的,这个变量已经出现了好多次了,可见是多么常用的一个变量。不熟悉的还是到前面Nginx 的 11 个阶段 重新复习一下。
还有另外一个模块 upstream_hash 模块,这个模块可以基于任意的关键字实现 hash 算法的复杂均衡。
基于任意关键字实现 hash 算法的负载均衡:upstream_hash 模块
- 功能:通过指定关键字作为 hash key,基于 hash 算法映射到特定的上游服务器中关键字可以含有变量、字符串可以使用 rr 算法的参数
- 模块: ngx_http_upstream_hash_module ,通过 --without-http_upstream_ip_hash_module 禁用模块
指令的话就是 hash 指令,后面可以跟关键字作为 key。
Syntax: hash key [consistent];
Default: —
Context: upstream 实战
配置文件如下所示:
log_format varups '$upstream_addr $upstream_connect_time $upstream_header_time $upstream_response_time '
'$upstream_response_length $upstream_bytes_received '
'$upstream_status $upstream_http_server $upstream_cache_status';
upstream iphashups {
ip_hash;
#hash user_$arg_username;
server 127.0.0.1:8011 weight=2 max_conns=2 max_fails=2 fail_timeout=5;
server 127.0.0.1:8012 weight=1;
}
server {
set_real_ip_from 127.0.0.1;
real_ip_recursive on;
real_ip_header X-Forwarded-For;
server_name iphash.ziyang.com;
listen 80;
error_log myerror.log info;
access_log logs/upstream_access.log varups;
location /{
proxy_pass http://iphashups;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
} 实际验证一下,会发现不同的 ip 地址实际上是会被不同的上游服务器处理的,如果是同一个 ip 地址,那么只会被一个上游服务器处理。
➜ nginx curl -H 'X-Forwarded-For: 10.200.20.20' iphash.ziyang.com
8012 server response.
➜ nginx curl -H 'X-Forwarded-For: 1.200.20.20' iphash.ziyang.com
8011 server response. 基于 IP 或者基于自定义 key 的 hash 算法有一个严重的问题,那就是当上游服务器挂掉的话,Nginx 依然会向这台服务器发请求,这是因为,如果负载的不同的服务器上去,可能会得到异常的响应,同时还可能导致大量的路由变更。下面的一致性哈希可以解决这个问题。
一致性哈希算法:hash 模块
刚才说了基于 IP 的哈希算法存在一个问题,那就是当有一个上游服务器宕机或者扩容的时候,会引发大量的路由变更,进而引发连锁反应,导致大量缓存失效等问题。那么为什么会造成这种情况呢?
假设我们基于 key 来做 hash,现在有 5 台上游服务器,如果基于最简单的 hash 算法对 key 取模,会将 key 和 server 一一对应起来。
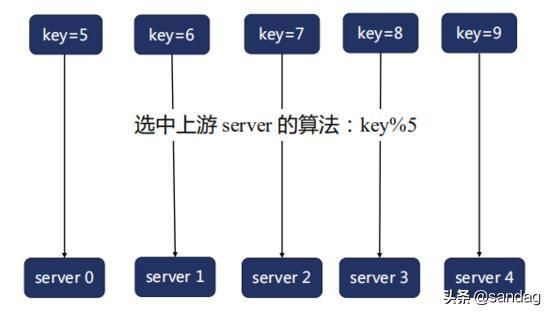
当有一台服务器宕机的时候,就需要重新对 key 进行 hash,最后会发现所有的对应关系全都失效了,从而会引发缓存大范围失效。
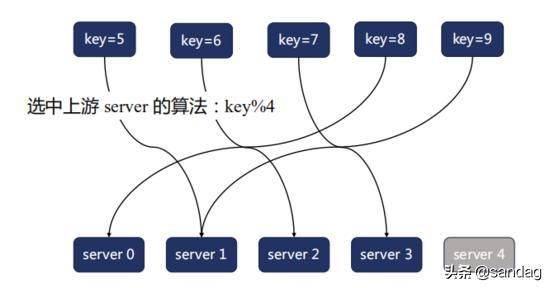
而一致性 hash 算法则可以解决这个问题。
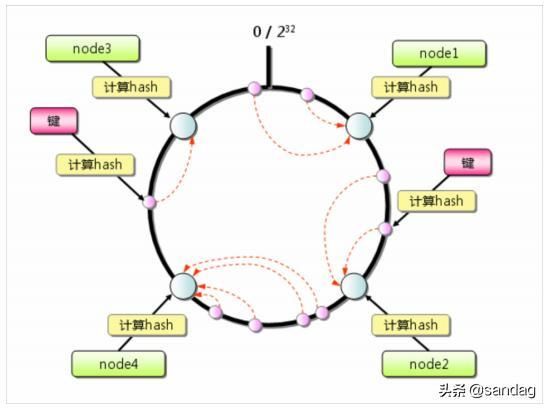
一致性哈希算法的原理是,将一个环分成了 2^32 个区间范围,四个节点将这个环划分成为了四个区间,每个区间的请求都由对应的节点去处理。来看看当扩容的时候会发生什么。

假设这时候发现 node4 负载过高,因此决定再添加一个节点进去分担压力,那么影响的也只是这个节点之后的请求,可能会缓存失效,而其他的三个节点是不会有任何影响的。
这就是一致性 hash 算法的原理,一致性 hash 算法使用也很简单,只需要将上一节指令中的参数打开即可:
Syntax: hash key [consistent];
Default: —
Context: upstream 这里只需要指明 consistent 参数即可。
最少连接数算法
再来看一个最少连接数算法。这个算法顾名思义,它会优先选择连接最少的上游服务器,是由 upstream_least_conn 模块提供的。
- 功能:从所有上游服务器中,找出当前并发连接数最少的一个,将请求转发到它如果出现多个最少连接服务器的连接数都是一样的,使用 rr 算法
- 模块: ngx_http_upstream_least_conn_module ,通过 --without-http_upstream_ip_hash_module 禁用模块
指令的用法也很简单,直接在 upstream 模块中开启 least_conn 指令即可。
Syntax: least_conn;
Default: —
Context: upstream 负载均衡策略对所有 worker 进程生效:upstream_zone 模块
上面说的所有的负载均衡算法对于 worker 进程来说都是独立的,每个 worker 进程之间并不互通,这样在很多时候并不是我们期望的。
我们期望的应该是负载均衡算法对所有的 worker 进程生效。
- 功能:分配出共享内存,将其他 upstream 模块定义的负载均衡策略数据、运行时每个上游服务器的状态数据存放在共享内存上,以对所 Nginx worker 进程生效
- 模块: ngx_http_upstream_zone_module ,通过 --without-http_upstream_ip_hash_module 禁用模块
一个指令,指定 zone 的名字以及对应的大小:
Syntax: zone name [size];
Default: —
Context: upstream 除此之外,各个负载均衡模块之间是要遵循一定的顺序的:
ngx_module_t *ngx_modules[] = {
… …
&ngx_http_upstream_hash_module,
&ngx_http_upstream_ip_hash_module,
&ngx_http_upstream_least_conn_module,
&ngx_http_upstream_random_module,
&ngx_http_upstream_keepalive_module,
&ngx_http_upstream_zone_module,
… …
}; 注意,这个模块的顺序是从上到下执行的,而不是我们前面过滤模块的从下到上。
可以看到,zone 模块在最后,也就是说,上面各个算法定义的参数和配置,最终 zone 模块会把这些配置放到共享内存里面生效。
这一节介绍了负载均衡的原理以及四种负载均衡算法,也可以说是三种,就是轮询、哈希、最少连接数算法。每一种算法都有各自的应用场景,rr 算法是最基础的负载均衡算法,在某些情况下其他算法失效的时候,会退化为 rr 算法。
upstream 提供的变量
先来介绍一组不含缓存的变量。
- upstream_addr上游服务器的 IP 地址,格式为可读的字符串,例如 127.0.0.1:8012
- upstream_connect_time与上游服务建立连接消耗的时间,单位为秒,精确到毫秒
- upstream_header_time:这个接收时间是会影响到 Nginx 的性能的,因为只有接收了 Header 才能决定下一步如何处理接收上游服务发回响应中 HTTP 头部所消耗的时间,单位为秒,精确到毫秒
- upstream_response_time接收完整的上游服务响应所消耗的时间,单位为秒,精确到毫秒
- upstream_http_头部从上游服务返回的响应头部的值
- upstream_bytes_received从上游服务接收到的响应长度,单位为字节
- upstream_response_length从上游服务返回的响应包体长度,单位为字节
- upstream_status上游服务返回的 HTTP 响应状态码。如果未连接上,该变量值为 502
- upstream_cookie_名称从上游服务发回的响应头 Set-Cookie 中取出的 cookie 值
- upstream_trailer_名称从上游服务的响应尾部取到的值
来看一下刚才的实战中我们的例子。
在刚才的负载均衡实战中有一条日志的配置:
log_format varups '$upstream_addr $upstream_connect_time $upstream_header_time $upstream_response_time '
'$upstream_response_length $upstream_bytes_received '
'$upstream_status $upstream_http_server $upstream_cache_status'; 这条配置用到了我们上面提到的很多变量,对应输出的实际日志长这个样子:
127.0.0.1:8012 0.001 0.001 0.001 22 170 200 nginx/1.17.8 - 大家可以对照日志格式看下分别代表什么意思,这里我就不细说了。
好了,今天这篇文章跟大家介绍了什么是负载均衡,Nginx 主要是通过 upstream 模块来提供对应的功能的,又介绍了负载均衡的四种算法,最后介绍了 upstream 中提供的变量。
面试造火箭,工作拧螺丝,希望对你有所帮助
多多转发,让更多人收益!!!