请使用arraymap代替hashmap
先说结论吧。
在Android上建议使用ArrayMap代替hashmap.
在一般的使用场景下,它可以在不影响读写效率的情况下,节省大约30%的内存空间。

就是想加张图,没别的意思。
why?往下看:
首先,我们要明白:
hashmap是Java util包下的类.
ArrayMap是google 在Android平台上作出优化后的类。
很多人可能会觉得对ArrayMap陌生,但是其实不然,在Android 源码中大量地使用了arraymap进行内存中的数据储存和管理。
举个例子 intent 传值:

intent传值
乍一看,这里是没有arraymap的,别着急往下看。

bundle本质就是一个arraymap
那为什么Google使用Arraymap代替hashmap呢?我们使用它的时候有什么好处呢?
上结果图:
先是执行速度对比:
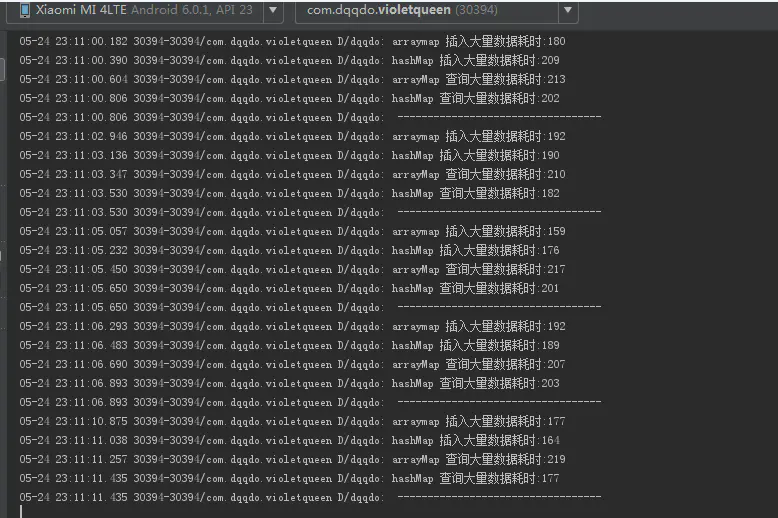
操作大量数据的情况(五万条)
少量数据效果对比:

操作少量数据(500条)
看上去好像并没有什么差异,反而在操作大量数据时,hashmap查询会快一些呢。
看看内存占用的对比:
储存大量数据(五万条)的情况:
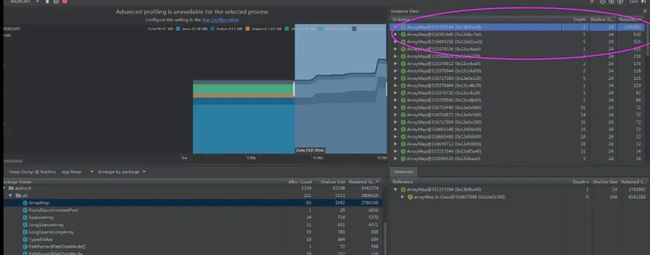
arraymap
arraymap占用了约等于 278KB的内存空间。
hashmap呢:
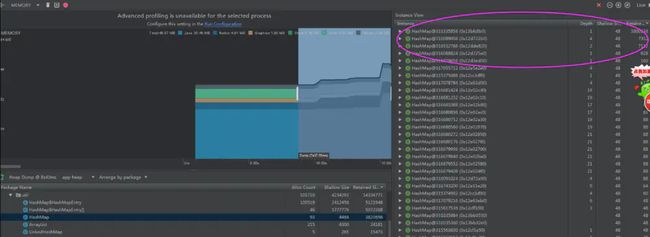
hashmap储存大量数据
hashmap 占用了380KB.多了36%的内存占用。
那么少量数据(500条)的情况呢:

hashmap少量数据
hashmap 储存500条数据占用了约6.3KB内容。
ArrayMap呢:

arraymap储存少量数据
arraymap储存500条数据仅占用了约4.7KB内存。
hashmap多占用了34%的内存空间。
来总结一下。也就是说在Android平台上存放数万条数据的情况下。
二者读写速度类似,但是ArrayMap比hashmap减少30%的内存消耗。
这对于经常内存空间紧张。经常OOM的Android应用来说是一个不少的内存开支。
那为什么ArrayMap会比HashMap有这样的效果呢?它又有什么缺点呢?
直接上代码(我手边的Android源码是25.对应jdk的源码应该是1.7)。
首先来看我们的老朋友HashMap的put方法:

put函数
put方法的最终会调用putval函数。这是hashmap数据组织和储存的主要逻辑所在:

putval函数实现
上图中,我们可以看到putVal函数各部分的代码的具体意思。
重点看扩容部分和下标计算部分的算法就可以了:
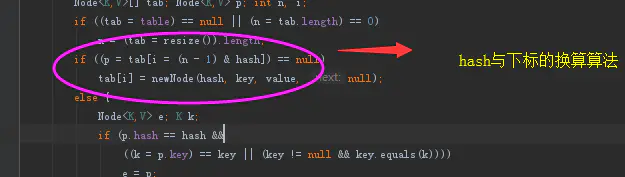
下标算法
hashmap的下标算法,是直接计算当前长度与对象的hash进行按位与运算。

hashmap的扩容机制
hashmap的扩容机制,网上有很多的文章有讲解。就是按照扩容因子,对其数组进行扩容操作。
总之,根据对hashmap的代码分析,我们可以得出结论,hashmap是这样储存数据的:
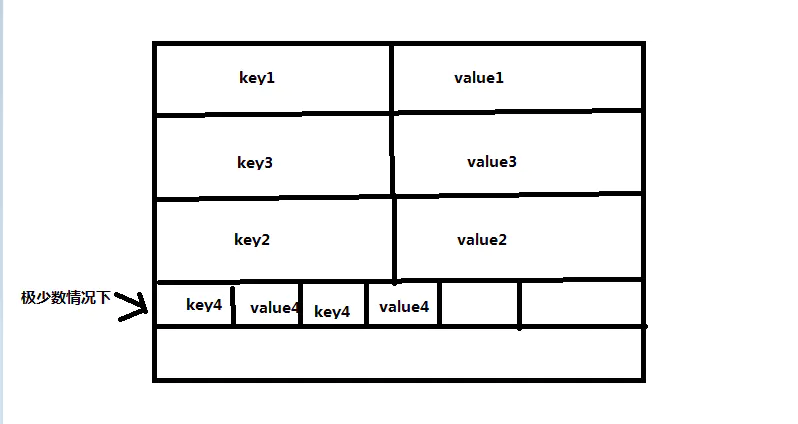
hashmap数据储存格式
扩容机制是一直扩大直到interger.MAX.
接下来是ArrayMap:
首先是put函数
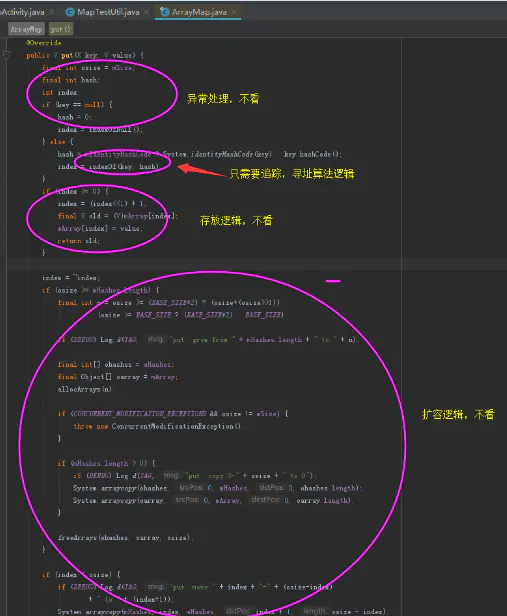
ArrayMap 的put函数
先来看put的注释描述,其实和hashmap是一样的。
这两百行的代码,跳过其他部分,直接看结尾重点部分,我们就能直到他的数据结构样式了。
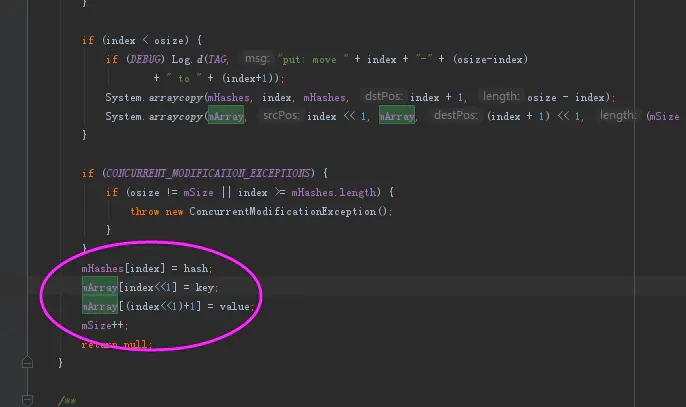
数据储存部分
原来他存放了两个数组。一个存放的是hash,另外一个存放的是真正的数值。并且是按照下标进行对照,并没有用键值对的形式。
翻译成图是这样的:
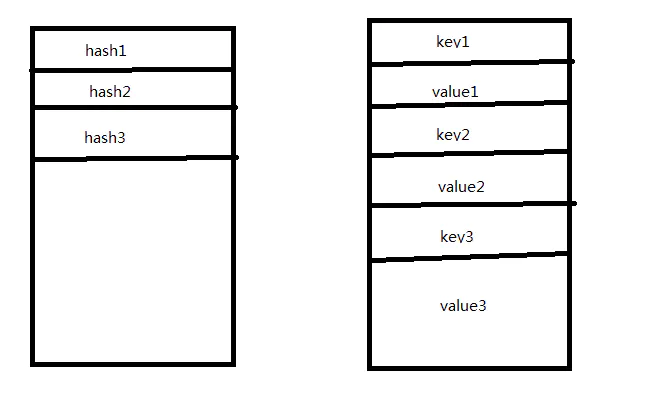
ArrayMap数据储存示意
虽然看懂了他的结构,但还是不知道为什么会节省内存啊。
直接进入下标计算和扩容机制部分。
下标计算:

下标计算1
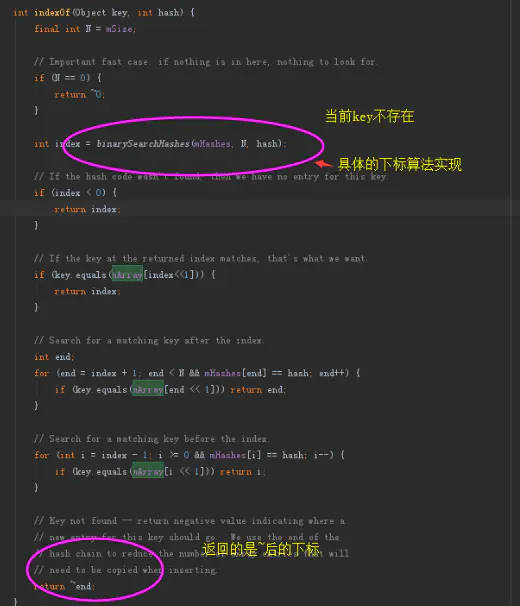
下标计算2
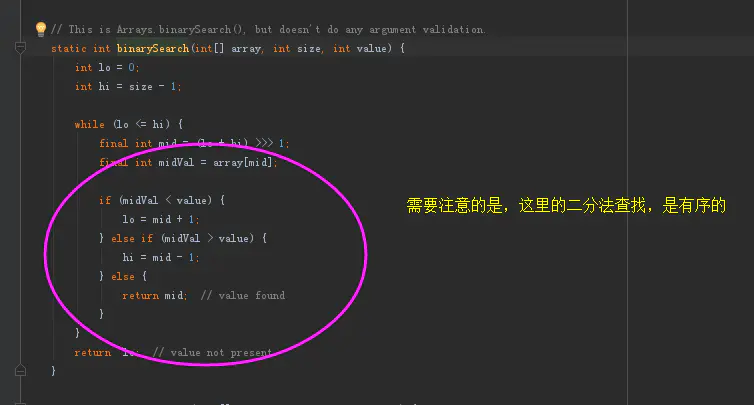
下标计算3
我们可以看到arraymap的数组储存是有序的,根据二分法进行定位的。
还有扩容机制,这里是添加时的扩容代码:
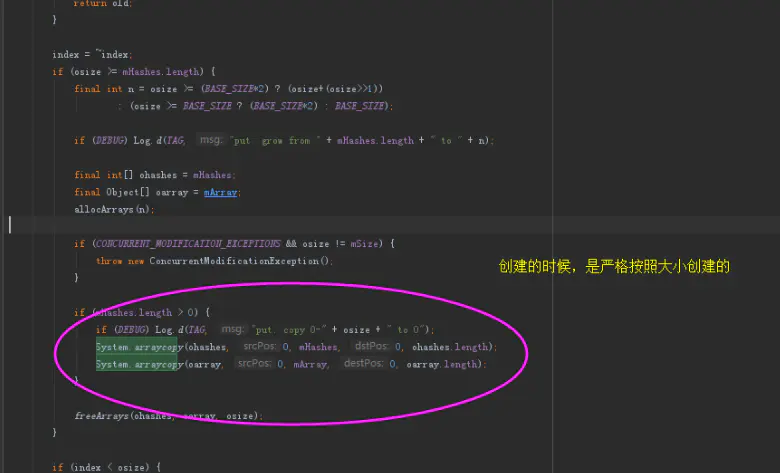
添加元素时扩容
删除元素的扩容代码:
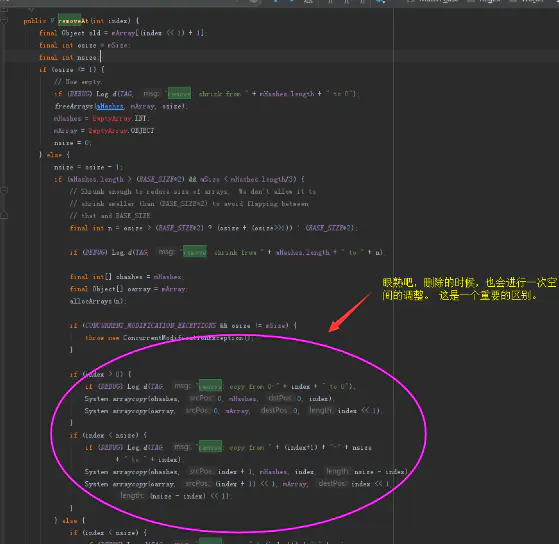
删除元素的扩容代码
看到了。在ArrayMap的元素扩容是时刻变化的。也就是说会随时根据内容动态调整整体的大小。
这也是一种用时间换取内存空间的优化思路。
总结一下:
ArrayMap的二分法查找和实时扩容机制,实现了一个有序的HashMap.并且可以在Android平台实现内存的节省。
劣势是在ArrayMap整体集合数据发生改变时,会影响到元素操作的效率。
理论上来说,在大数据量的情况下,更频繁的数据条数大幅度变化下,效率会变得更低。
但是在我的实现过程中,发现其速度在数万条数据的情况下,相差无几。
其实一般来说,我们不会在Android移动设备的内存中储存数万条数据,这也是为什么Google在Android的源码中大量使用ArrayMap的原因。
毕竟他只是一个手机,放过它吧。
综上所述,请使用arraymap代替hashmap。
over.