如何在本地调试你的 Spark Job
生产环境的 Spark Job 都是跑在集群上的,毕竟 Spark 为大数据而生,海量的数据处理必须依靠集群。但是在开发Spark的的时候,不可避免我们要在本地进行一些开发和测试工作,所以如何在本地用好Spark也十分重要,下面给大家分享一些经验。
首先你需要在本机上安装好了Java,Scala和Spark,并配置好了环境变量。详情请参考官方文档或其他教程。
spark-shell
本地运行Spark最直接的方式就是在命令行里面运行spark-shell,成功后你将看到如下信息:
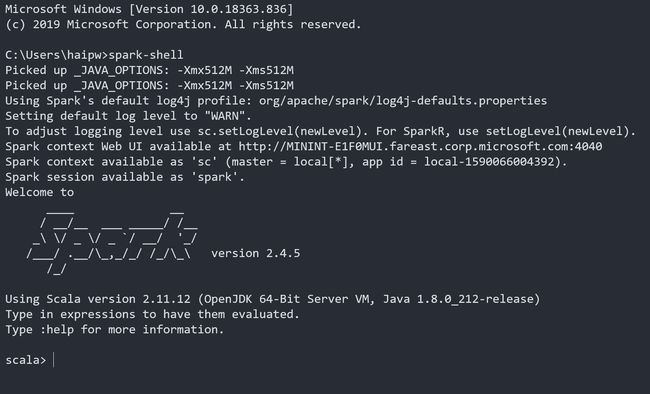
首先可以仔细阅读一下命令行的提示信息,
Picked up _JAVA_OPTIONS: -Xmx512M -Xms512M // _JAVA_OPTIONS是我在系统环境变量里面设置的值
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties // 告诉你log4j使用配置
Setting default log level to "WARN". // log级别
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). // 如何调整log级别
Spark context Web UI available at http://localhost:4040 // 本地访问Web UI的地方,很重要
Spark context available as 'sc' (master = local[*], app id = local-1590066004392). // master配置和 sc变量
Spark session available as 'spark'. // spark变量可以发现必要的信息都已经给我们提示好了,不过不知道哪里养成的坏习惯,程序的提示信息我通常都是跳过不看的,其实这样很不好,希望你没有这种坏习惯。
我们再仔细看一下 master = local[*] 这个配置,它告诉Spark在运行中可以使用多少个核,详细如下:
- local: 所有计算都运行在一个线程当中,没有任何并行计算。
- local[n]: 指定使用n个线程来运行计算。
- local[*]: 这种模式直接帮你按照cpu最多cores来设置线程数了。
你可以在这个命令行像使用python解释器一样写scala代码,可以及时看到程序的运行结果,这种模式通常在最初学习spark的时候使用,或者你想要验证一些临时、简短的spark代码,可以使用这种方式。
Spark Web UI
在你使用Spark 期间,可以通过 http://localhost:4040 来访问Web UI. 这是Spark提供的非常强大的一个工具,它可以看到运行过程中的丰富细节,网上有很多资料可以参考,这里不详细介绍。Spark Web UI
值得一提的是,Web UI 只在你SparkSession活跃期间可以访问,当你的job完成时这个地址就关闭了。当你打开一个spark-shell的时候,你的spark session会一直活跃,所以可以随时访问Web UI;当你关闭命令行的时候就不可以了。 当然你也可以通过修改配置保存这些信息,可以让你在程序退出后依然有办法从Web UI查看,但操作起来有点复杂,并且一般用的频率小,就不推荐了。
Jupyter Notebook
比spark-shell更好的一种方式是使用Notebook,Notebook。 首先你可以在本机安装Anaconda,安装完之后自带Jupyter Notebook,但是它默认只支持python 的kernel,也就是说只能写python,为了能写spark job(实际上是Scala脚本)需要再安装一些插件,插件其实很多,我找到了一种非常简便的方法,推荐给大家:
spylon-kernel
按照上面的教程安装完之后,你打开Notebook,再new 下面可以看到一个新的kernel选项
新建之后就可以写spark job了。
显然Notebook比命令行的方式好的多,不但可以执行代码,还可以修改、保存、分享,本地调试一些小的程序时候或者演示、验证一些新功能的时候首选这种方式。
第一次启动scala解释器的时候时间会比较久,请耐心等待。查看你的notebook命令行输出,是否忘了配置 SPARK_HOME 环境变量?
成功运行之后你将看到如下信息:
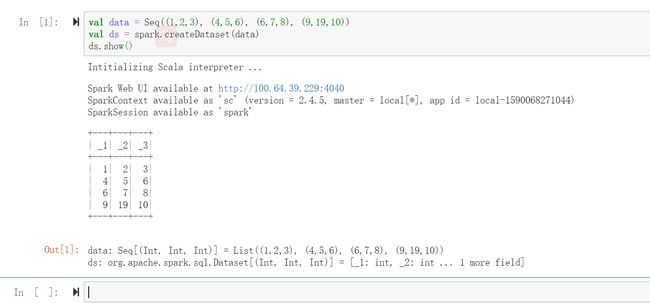
同样,在你的Notebook运行期间你也可以到 http://localhost:4040 页面查看Spark Web UI.
IDEA
当然,你也可以在IDEA 中写代码并测试,这个更接近生产环境的工作,一般最后都要使用它写好完整的代码,编译并打包为jar. IDEA的介绍请参考 IDEA中运行Java/Scala/Spark程序.
写代码的过程不再做介绍,在IDEA里运行的时候同样需要指定master为本机,你有两种方式可以使用:一是在程序的代码里直接设置,另外一种是在VM参数中添加。建议选择后者。
Run -> Edit Configurations -> VM Options: -Dspark.master=local[6]另外你还可以增加一个命令行参数,例如: --local, 这样你可以在脚本中方便地输出一些只有你在本地想看的信息。
// 检查命令行参数,赋值给local变量,方便测试一些本地信息
if(arg.startsWith("--local"))
{
local = true
}最后,当你在IDEA里面运行Spark Job的时候,运行结束之后Web UI的端口会自动关闭,所以如果你想要在程序运行完的一段时间内还可以看到这些信息(通常都是需要的),你需要在程序结束的位置加上如下语句:
if(local)
{
System.in.read
spark.stop()
}如果你喜欢我的文章,欢迎到我的个人网站关注我,非常感谢!