【python课程学习2-1】——库、数据类型、三元运算、进制、字符串操作
@开始第二周课程的学习,将会对所学知识进行整理和总结,这是第一部分。
具体内容包括:库、python数据类型、bytes数据类型、字符串常用操作
一、模块部分(库)
1.1 python标准库和第三方库
1、python的标准库是随着pyhon安装的时候默认自带的库。(标准库一般存储在Lib 路径下)
2、python的第三方库,需要下载后安装到python的安装目录下,不同的第三方库安装及使用方法不同。(一般存储在site-packages路径下 )
3、它们调用方式是一样的,都需要用import语句调用。
简单的说,一个是默认自带不需要下载安装的库,一个是需要下载安装的库。它们的调用方式是一样的。
1.2 sys模块
目前只讲两个方法:
~sys.path 打印环境变量,在Python中打印的是绝对路径,在cmd路径下是相对路径
~sys.argv[ ] 其实就是一个列表,里边的项为用户输入的参数,关键就是要明白这参数是从程序外部输入的,而非代码本身的什么地方,要想看到它的效果就应该程序保存了,从外部来运行程序并给出参数。
1.3 os模块
os.path 模块主要用于获取文件的属性。
import os
#执行命令,不保存结果(也就是说只把结果打印在屏幕上了,并没有数据可存到变量中)
cmd_res = os.system("dir")
#此命令可以实现上述功能,但是需要在使用read()函数读取内容
cmd_res = os.popen("dir").read()
print("____>",cmd_res)
#在当前目录下创建一个目录
os.mkdir("new_dir")
无论在写自动化脚本还是做测试os模块都是一个重量级的模块。

1.4 自己创建模块导入
需注意:导入的模块(也就是自己写的.py)运行时,先会在当前目录下寻找是否存在,如果找不到的话,会在环境路径下寻找(即sys.path这些路径下),如果还找不到就会报错,提示找不到该模块。所以解决的办法就是把该文件放到其中一个路径下。
1.5 pyc是什么
pyc文件存的是:预编译后的字节码文件,非机器码


二、数据类型

注意:长整型(long) pyhon3中已经不会用了,主要是存储位数的不同
值得注意的是:
1、Python中的变量都是指针,因此是没有类型限制的,且指针的内存空间大小是与类型无关的,其内存空间只是保存了所指向数据的内存地址。
2、值类型是不可变的(immutable),这种不可变是指该值类型的变量指向的空间所存储的地址是不变的,而非内容不变,具体详情连接如下:
python数据类型总结
2.1 int(整型)

2.2 bool(布尔值)
~真或假
~1或0
2.3 字符串
(1)拼接字符串
使用“+”可以对多个字符串进行拼接,语法格式: str1 + str2
需要注意的是字符串不允许直接与其他类型进行拼接
上面这种情况我们可以将其他类型转换为字符串再进行拼
(2)计算字符串的长度
在Python中使用len()函数来计算字符串的长度
>>> str1 = "hello"
>>> len(str1)
5
>>> str2 = "你好"
>>> len(str2)
2
>>> str3 = "1111"
>>> len(str3)
4
在默认情况下,len函数在计算字符串的长度时,无论是数字,字母还是多字节的汉字都认为是一个字符。
为什么说是默认情况下呢,因为在实际开发中,可能因为我们采取的编码不同,字符串实际所占的字节数也不同。
~UTF-8编码,汉字占3个字节
~GBK或者GB2312,汉字占2个字节
这时我们可以通过使用encode()方法进行编码后再进行获取长度。
>>> str1 = "你好"
>>> len(str1)
2
>>> len(str1.encode('gbk'))
4
>>> len(str1.encode('utf-8'))
6
(3)截取字符串
语法格式: string[start : end : step]
string:表示要截取的字符串
start:表示要截取的第一个字符的索引(包括该字符),如果不指定,则默认为0
end:表示要截取的最后一个字符的索引(不包括该字符),如果不指定则默认为字符串的长度。
step:表示切片的步长,如果省略,则默认为1,当省略该步长时,最后一个冒号也可以省略。
注意默认情况下按空格分割
>>> str1 = "i am a good boy!"
>>> str1.split() #采用默认分割符进行分割
['i', 'am', 'a', 'good', 'boy!']
>>> str1.split(" ") #采用空格进行分割
['i', 'am', 'a', 'good', 'boy!']
>>> str1.split(" ", 3) #采用空格进行分割,并且只分割前3个
['i', 'am', 'a', 'good boy!']
(4)检索字符串
python中字符串的查找方法
1、count()方法
语法格式 : str.count(sub[, start[, end]])
作用:用于检索指定字符串在另一个字符串中出现的次数,如果检索的字符串不存在则返回0,否则返回出现的次数。
str:表示原字符串
sub:表示要检索的子字符串
start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索
end:可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾
>>> str1 = "hello world"
>>> print(str1.count('o'))
2、find()方法
语法格式 : str.find(sub[, start[, end]])
作用:检索是否包含指定的字符串,如果检索的字符串不存在则返回-1,否则返回首次出现该字符串时的索引。
>>> str1 = "hello world!"
>>> str1.find('wo')
6
#首次出现该字符串时的索引
3、index()方法
语法格式 : str.index(sub[, start[, end]])
作用:和find方法类似,也用于检索是否包含指定的字符串,使用index方法,当指定的字符串不存在时会抛异常。
>>> str1 = "hello world!"
>>> str1.index('w')
6
>>> str1.index('m')
Traceback (most recent call last):
File "" , line 1, in <module>
str1.index('m')
ValueError: substring not found
>>> str1.find('m')
-1
注意:find()方法中如果字符不存在提示-1
index()方法中是给出异常提示,报错。
4、startswith()方法
语法格式 : str.startswith(prefix[, start[, end]])
作用:检索字符串是否以指定的字符串开头,如果是则返回true,否则返回false。
>>> str1 = "hello world!"
>>> str1.startswith('hello')
True
>>> str1.startswith('hi')
False
注意:是指定的字符串开头,不是指定的单个字符开头,
语句的措辞是有差别的,请注意下!
5、endswith()方法
语法格式 : str.endswith(prefix[, start[, end]])
作用:检索字符串是否以指定的字符串结尾,如果是则返回true,否则返回false。
>>> str1 = "hello world!"
>>> str1.endswith('world!')
True
>>> str1.endswith('haha')
False
2.4 三元运算
result = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假:result = 值2
2.5 进制
~二进制(Binary)
~八进制(Octal)
~十进制(Decimal)
~十六进制(Hexadecimal)后缀是H,l例如:BH;前缀是0x 例如:0x53
python内置函数实现进制转换
bin()、oct()、int()、hex()
进制的小故事:偶然等红绿灯发现有的红灯信号计时是按照16进制显示的,有几次一直看不懂,知道是十六进制,但是没看懂是怎么变化的,后来仔细观察(等了好几个红绿灯,就为了观察下怎么计数的)后面才发现是这样的,左边位数显示的是十六进制,右面是十进制表示的。
例如:B1:代表111秒 A8:代表108秒,想出来的这种计时的人真是太聪明了。
2.6 bytes类型
在Python2中bytes和字符型是一样的,但是在Python3中最重要的新特性要算是对文本和二进制数据作了更为清晰的区分。**文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。视频等有用到二进制的数据。**不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
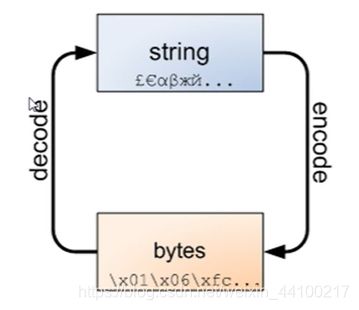
字符串可以编码成字节包,而字节包可解码成字符串。
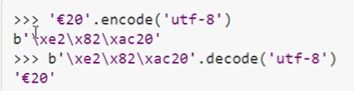
字符串是以字符为单位进行处理的,bytes类型是以字节为单位处理的。
bytes数据类型在所有的操作和使用甚至内置方法上和字符串数据类型基本一样,也是不可变的序列对象。
bytes对象只负责以二进制字节序列的形式记录所需记录的对象,至于该对象到底表示什么(比如到底是什么字符)则由相应的编码格式解码所决定。Python3中,bytes通常用于网络数据传输、二进制图片和文件的保存等等。可以通过调用bytes()生成bytes实例,其值形式为 b’xxxxx’,其中 ‘xxxxx’ 为一至多个转义的十六进制字符串(单个 x 的形式为:\x12,其中\x为小写的十六进制转义字符,12为二位十六进制数)组成的序列,每个十六进制数代表一个字节(八位二进制数,取值范围0-255),对于同一个字符串如果采用不同的编码方式生成bytes对象,就会形成不同的值.