spark+python+ubuntu环境配置
1.ubuntu使用虚拟机,即使出错也不会影响其他。
2.python在ubuntu已经自带,但是要重新更新为python3,并且默认使用python3.谷歌一下有相关教程。java得安装一下。
提高python3优先级
直接执行这两个命令即可:
sudo update-alternatives --install /usr/bin/python python /usr/bin/python2 100
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150

java环境安装:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
包含以下几大类:
SE(J2SE),standard edition,标准版,是我们通常用的一个版本,从JDK 5.0开始,改名为Java SE。
EE(J2EE),enterprise edition,企业版,使用这种JDK开发J2EE应用程序,从JDK 5.0开始,改名为Java EE。
ME(J2ME),micro edition,主要用于移动设备、嵌入式设备上的java应用程序,从JDK 5.0开始,改名为Java ME。
没有JDK的话,无法编译Java程序,如果想只运行Java程序,要确保已安装相应的JRE。
1、在/usr/lib下新建一个文件夹sudo mkdir /usr/lib/jdk
![]()
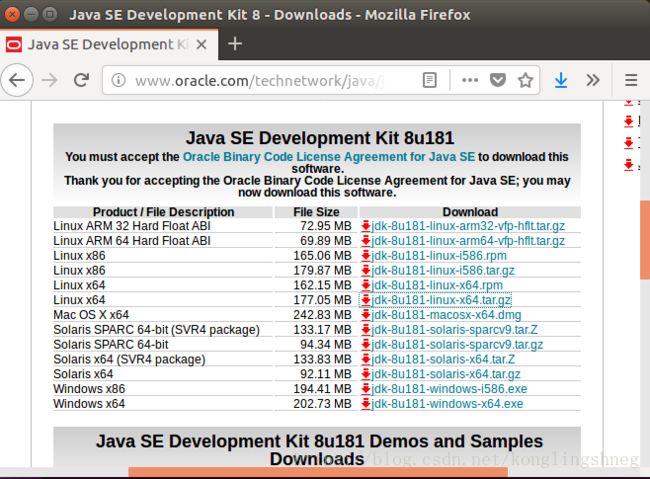
3、系统默认下载到download文件夹(找到copy一下地址),cd 到下载文件文件夹
![]()
4、解压缩到我们新建的文件夹 sudo tar -zxvf jdk-8u181-linux-x64.tar.gz -C /usr/lib/jdk
![]()
5、配置PATH路径,让jdk命令在任何路径下都能够直接执行, gedit, vim都可以。
这儿有一篇介绍环境变量不错的文章 https://www.cnblogs.com/jpfss/p/6560703.htmlsudo gedit /etc/profile
在配置文件后加上
# java
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH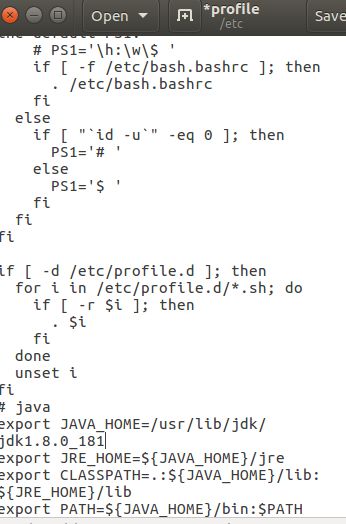
6、重新载入/etc/profile配置文件 source /etc/proflie
![]()
7、运行java -version查看java是否安装成功
出现如下结果说明安装成功

注意编辑profile时,最好找到etc/profile这个文件,拉到终端内,然后前边加上sudo gedit,不然会出错。
安装spark
1、官网下载地址 http://spark.apache.org/downloads.html
![]()

2、为spark新建一个文件夹sudo mkdir /usr/lib/spark

3、找到下载文件目录,并cd到该目录下

4、将下载文件安装到新建文件夹下sudo tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz -C /usr/lib/spark

5、配置spark
cd /usr/lib/spark/spark-2.3.1-bin-hadoop2.7/conf/
sudo cp spark-env.sh.template spark-env.sh
sudo gedit spark-env.sh 在最后加上
JAVA_HOME=/usr/lib/jdk/jdk1.8.0_181
SPARK_WORKER_MEMORY=4g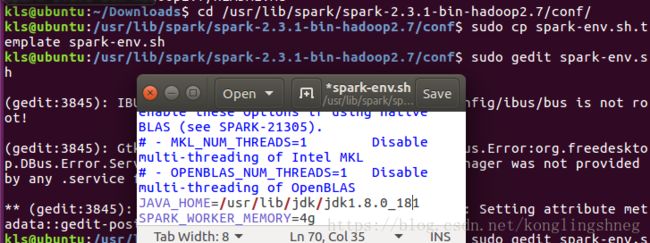
6、然后我们需要配置PATH路径,让jdk命令在任何路径下都能够直接执行 sudo gedit /etc/profile
没有安装gedit的可以 vi vim都行
在配置文件后加上
#spark
export SPARK_HOME=/usr/lib/spark/spark-2.3.1-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:$PATH
7、重新载入/etc/profile配置文件 source /etc/proflie
![]()
8、运行 pyspark 查看spark是否安装成功
出现如下结果说明安装成功
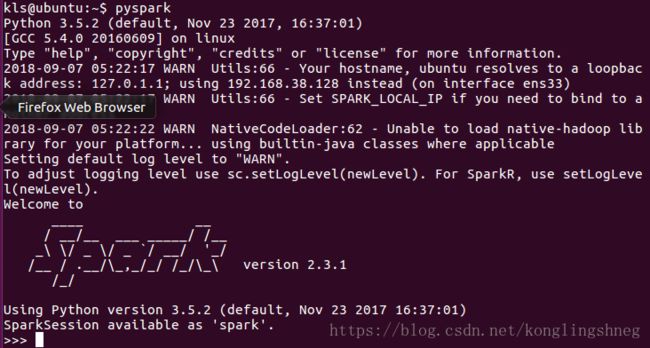
如果不成功 ,cd ~/.bashrc里面加一句source /etc/profile重启即可。还是不成功说明上上一部和上一部没成功
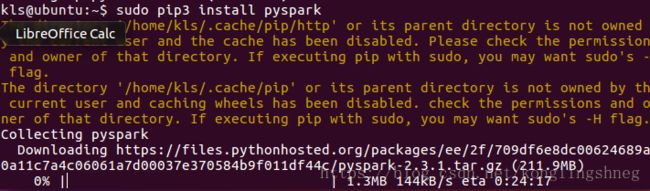
安装pyspark
sudo pip3 install pyspark(python2改为python3还需安装pip3)
如果出现错误运行sudo pip3 install --no-cache-dir pyspark

打开python运行
from pyspark.sql import SparkSession
spark = SparkSession.builder.master('local').appName('test').getOrCreate()
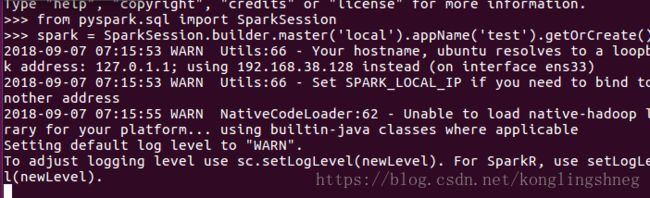
运行顺利说明安装成功
接下来就可以使用了,当然还可以配置一下anaconda,jupyternotebook,Spyder之类的IDE进行Python开发。这个深度学习环境配置案例很多,网上搜一搜即可。