机器学习实战02:Kaggle - House Price Prediction Top 4%
一、模块导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import os
warnings.filterwarnings('ignore')
%matplotlib inline
plt.style.use('ggplot')
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import RobustScaler, StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.pipeline import Pipeline, make_pipeline
from scipy.stats import skew
from sklearn.decomposition import PCA, KernelPCA
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score, GridSearchCV, KFold
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, ExtraTreesRegressor
from sklearn.svm import SVR, LinearSVR
from sklearn.linear_model import ElasticNet, SGDRegressor, BayesianRidge
from sklearn.kernel_ridge import KernelRidge
from xgboost import XGBRegressor
二、数据读取
pd.set_option('max_colwidth',300) # 显示最大列长度(字符)
pd.set_option('display.width',300) # 横向最多显示的字符数
pd.set_option('display.max_columns',500) # 显示的最大列数
pd.set_option('display.max_rows',1000) # 显示的最大行数
# 数据读取
os.getcwd()
os.chdir('C:/Users/Anqi/00 Mechine learning/Kaggle 2_House Price Prediction/House_Data')
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
三、简单可视化
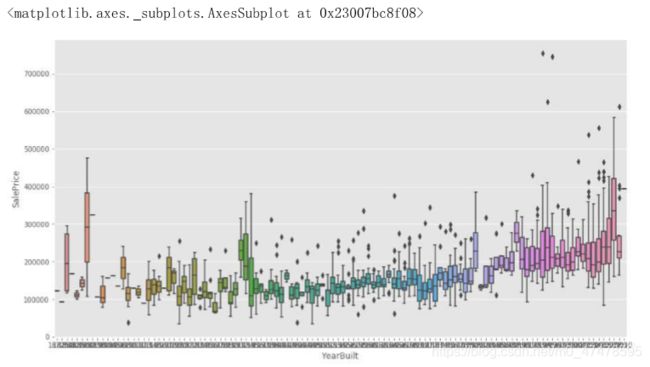
# 根据经验,房屋建造年份、地面住房面积与售卖价格密切相关
# 下面将这两项可视化
plt.figure(figsize=(15,8))
sns.boxplot(train.YearBuilt, train.SalePrice)
plt.figure(figsize=(12,6))
plt.scatter(x=train.GrLivArea, y=train.SalePrice)
plt.xlabel("GrLivArea", fontsize=15)
plt.ylabel("SalePrice", fontsize=15)
plt.ylim(0,800000)
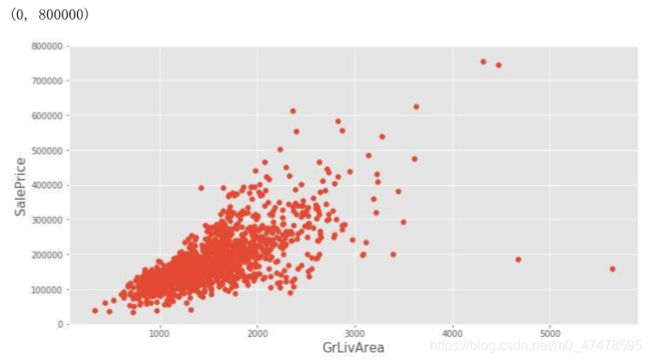
# 去除异常值
train.drop(train[(train["GrLivArea"]>4000)&(train["SalePrice"]<300000)].index,inplace=True)
combined_train_test=pd.concat([train,test], ignore_index=True)
combined_train_test.drop(['Id'],axis=1, inplace=True)
combined_train_test.shape
[Out] (2917, 80)
四、数据清洗、缺失值填充
missing_data = combined_train_test.isnull().sum()
missing_data[missing_data>0].sort_values(ascending=False)
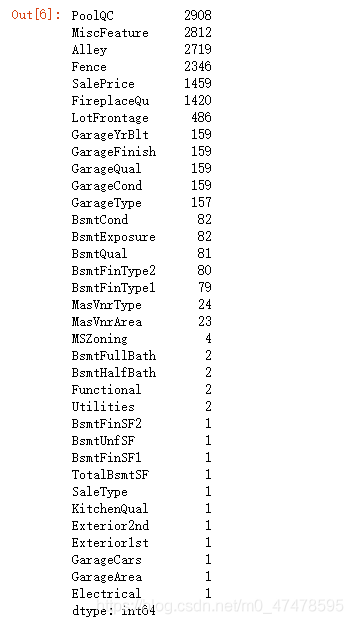
缺失值过大的特征可能会影响最终模型的准确性,因此将缺失值超过500的特征舍弃
4.1 LotFrontage 缺失值填充
# LotFrontage 街道特征与邻居(周边居住环境)相关性大,并且 LotFrontage为离散型数据,
# 因此将 LotFrontage划分区间并结合Neighborhood进行分组,而后使用中位数进行填充
combined_train_test['LotAreaCut'] = pd.qcut(combined_train_test.LotArea,10)
combined_train_test['LotFrontage']= combined_train_test.groupby(['LotAreaCut','Neighborhood'])['LotFrontage'].transform(lambda x: x.fillna(x.median()))
# 由于部分 LotFrontage 第一步填充操作后,在同组内(同区间同邻居)无对应的中位数值,皆缺失
# 可按照 LotFrontage 各区间的中位数再次进行缺失值填充
#Since some combinations of LotArea and Neighborhood are not available, so we just LotAreaCut alone.
combined_train_test['LotFrontage']=combined_train_test.groupby(['LotAreaCut'])['LotFrontage'].transform(lambda x: x.fillna(x.median()))
4.2 其他缺失值填充
# 可按 0 值进行填充的特征:
cols=["MasVnrArea", "BsmtUnfSF", "TotalBsmtSF", "GarageCars", "BsmtFinSF2", "BsmtFinSF1", "GarageArea"]
for col in cols:
combined_train_test[col].fillna(0, inplace=True)
# 可按 None 进行填充的特征:
cols1 = ["PoolQC" , "MiscFeature", "Alley", "Fence", "FireplaceQu", "GarageQual", "GarageCond", "GarageFinish", "GarageYrBlt", "GarageType", "BsmtExposure", "BsmtCond", "BsmtQual", "BsmtFinType2", "BsmtFinType1", "MasVnrType"]
for col in cols1:
combined_train_test[col].fillna("None", inplace=True)
# 可按众数进行填充的特征:
cols2 = ["MSZoning", "BsmtFullBath", "BsmtHalfBath", "Utilities", "Functional", "Electrical", "KitchenQual", "SaleType","Exterior1st", "Exterior2nd"]
for col in cols2:
combined_train_test[col].fillna(combined_train_test[col].mode()[0], inplace=True)
# 检查样本中的缺失值状态
combined_train_test.isnull().sum()[combined_train_test.isnull().sum()>0]
五、特征工程处理
5.1 分类型特征处理
# step 1:将数值型特征转化为字符型
NumStr = ["MSSubClass","BsmtFullBath","BsmtHalfBath","HalfBath","BedroomAbvGr","KitchenAbvGr","MoSold","YrSold","YearBuilt","YearRemodAdd","LowQualFinSF","GarageYrBlt"]
for col in NumStr:
combined_train_test[col]=combined_train_test[col].astype(str)
# step 2:挨个处理各分类型特征(根据平均数、中位数、计数,将各分类型特征可视化,并根据结果进一步分类)
fig = plt.figure(figsize=(15,18))
# MSSubClass
plt.subplot(421)
v_MSSC = combined_train_test.groupby(['MSSubClass'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_MSSC.index,v_MSSC['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_MSSC.index,v_MSSC['SalePrice']['median'],label='median',color='blue')
plt.plot(v_MSSC.index,v_MSSC['SalePrice']['count']*1000,label='count*1000',color='green')
plt.title('MSSubClass')
plt.legend(loc='upper right')
# BsmtFullBath
plt.subplot(422)
v_BFB = combined_train_test.groupby(['BsmtFullBath'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_BFB.index,v_BFB['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_BFB.index,v_BFB['SalePrice']['median'],label='median',color='blue')
plt.plot(v_BFB.index,v_BFB['SalePrice']['count']*200,label='count*200',color='green')
plt.title('BsmtFullBath')
plt.legend(loc='upper right')
# BsmtHalfBath
plt.subplot(423)
v_BHB = combined_train_test.groupby(['BsmtHalfBath'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_BHB.index,v_BHB['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_BHB.index,v_BHB['SalePrice']['median'],label='median',color='blue')
plt.plot(v_BHB.index,v_BHB['SalePrice']['count']*200,label='count*200',color='green')
plt.title('BsmtHalfBath')
plt.legend(loc='upper right')
# HalfBath
plt.subplot(424)
v_HB = combined_train_test.groupby(['HalfBath'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_HB.index,v_HB['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_HB.index,v_HB['SalePrice']['median'],label='median',color='blue')
plt.plot(v_HB.index,v_HB['SalePrice']['count']*200,label='count*200',color='green')
plt.title('HalfBath')
plt.legend(loc='upper right')
# BedroomAbvGr
plt.subplot(425)
v_BAG = combined_train_test.groupby(['BedroomAbvGr'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_BAG.index,v_BAG['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_BAG.index,v_BAG['SalePrice']['median'],label='median',color='blue')
plt.plot(v_BAG.index,v_BAG['SalePrice']['count']*200,label='count*200',color='green')
plt.title('BedroomAbvGr')
plt.legend(loc='upper right')
# KitchenAbvGr
plt.subplot(426)
v_KAG = combined_train_test.groupby(['KitchenAbvGr'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_KAG.index,v_KAG['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_KAG.index,v_KAG['SalePrice']['median'],label='median',color='blue')
plt.plot(v_KAG.index,v_KAG['SalePrice']['count']*200,label='count*200',color='green')
plt.title('KitchenAbvGr')
plt.legend(loc='upper right')
# MoSold
plt.subplot(427)
v_MS = combined_train_test.groupby(['MoSold'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_MS.index,v_MS['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_MS.index,v_MS['SalePrice']['median'],label='median',color='blue')
plt.plot(v_MS.index,v_MS['SalePrice']['count']*200,label='count*200',color='green')
plt.title('MoSold')
plt.legend(loc='upper right')
# YrSold
plt.subplot(428)
v_YS = combined_train_test.groupby(['YrSold'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_YS.index,v_YS['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_YS.index,v_YS['SalePrice']['median'],label='median',color='blue')
plt.plot(v_YS.index,v_YS['SalePrice']['count']*200,label='count*200',color='green')
plt.title('YrSold')
plt.legend(loc='upper right')
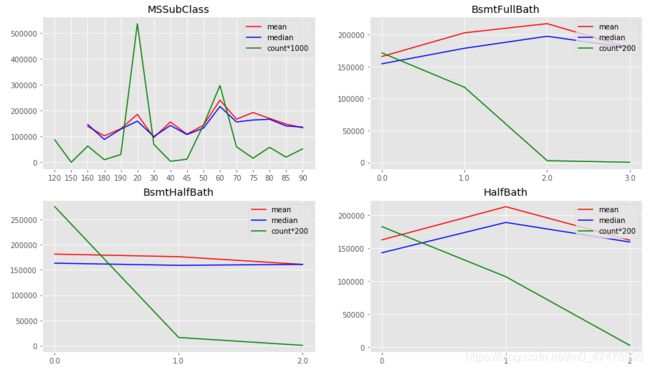
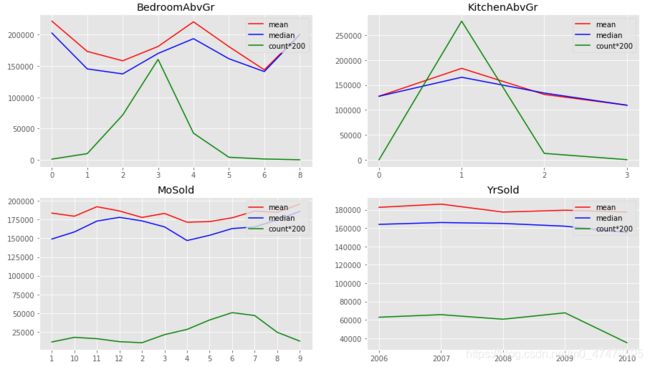
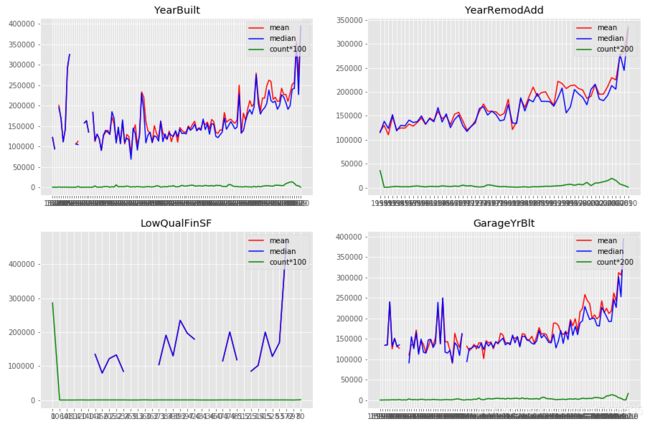
fig = plt.figure(figsize=(15,10))
# YearBuilt
plt.subplot(221)
v_YB = combined_train_test.groupby(['YearBuilt'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_YB.index,v_YB['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_YB.index,v_YB['SalePrice']['median'],label='median',color='blue')
plt.plot(v_YB.index,v_YB['SalePrice']['count']*200,label='count*100',color='green')
plt.title('YearBuilt')
plt.legend(loc='upper right')
# YearRemodAdd
plt.subplot(222)
v_YRB = combined_train_test.groupby(['YearRemodAdd'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_YRB.index,v_YRB['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_YRB.index,v_YRB['SalePrice']['median'],label='median',color='blue')
plt.plot(v_YRB.index,v_YRB['SalePrice']['count']*200,label='count*200',color='green')
plt.title('YearRemodAdd')
plt.legend(loc='upper right')
# LowQualFinSF
plt.subplot(223)
v_LQFS = combined_train_test.groupby(['LowQualFinSF'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_LQFS.index,v_LQFS['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_LQFS.index,v_LQFS['SalePrice']['median'],label='median',color='blue')
plt.plot(v_LQFS.index,v_LQFS['SalePrice']['count']*200,label='count*100',color='green')
plt.title('LowQualFinSF')
plt.legend(loc='upper right')
# GarageYrBlt
plt.subplot(224)
v_GYB = combined_train_test.groupby(['GarageYrBlt'])[['SalePrice']].agg(['mean','median','count'])
plt.plot(v_GYB.index,v_GYB['SalePrice']['mean'],label='mean',color='red')
plt.plot(v_GYB.index,v_GYB['SalePrice']['median'],label='median',color='blue')
plt.plot(v_GYB.index,v_GYB['SalePrice']['count']*200,label='count*200',color='green')
plt.title('GarageYrBlt')
plt.legend(loc='upper right')
cols = combined_train_test.columns
ls = []
for col in cols:
ls.append([col,len(combined_train_test[col].unique()),type(combined_train_test[col][0])])
A = pd.DataFrame(data=ls,columns=['columns','uniq_nums','dtypes'])
# 定义函数
def map_values():
combined_train_test["oMSSubClass"] = combined_train_test.MSSubClass.map({'180':1,
'30':2, '45':2,
'190':3, '50':3, '90':3,
'85':4, '40':4, '160':4,
'70':5, '20':5, '75':5, '80':5, '150':5,
'120': 6, '60':6})
combined_train_test["oMSZoning"] = combined_train_test.MSZoning.map({'C (all)':1, 'RH':2, 'RM':2, 'RL':3, 'FV':4})
combined_train_test["oNeighborhood"] = combined_train_test.Neighborhood.map({'MeadowV':1,
'IDOTRR':2, 'BrDale':2,
'OldTown':3, 'Edwards':3, 'BrkSide':3,
'Sawyer':4, 'Blueste':4, 'SWISU':4, 'NAmes':4,
'NPkVill':5, 'Mitchel':5,
'SawyerW':6, 'Gilbert':6, 'NWAmes':6,
'Blmngtn':7, 'CollgCr':7, 'ClearCr':7, 'Crawfor':7,
'Veenker':8, 'Somerst':8, 'Timber':8,
'StoneBr':9,
'NoRidge':10, 'NridgHt':10})
combined_train_test["oCondition1"] = combined_train_test.Condition1.map({'Artery':1,
'Feedr':2, 'RRAe':2,
'Norm':3, 'RRAn':3,
'PosN':4, 'RRNe':4,
'PosA':5 ,'RRNn':5})
combined_train_test["oBldgType"] = combined_train_test.BldgType.map({'2fmCon':1, 'Duplex':1, 'Twnhs':1, '1Fam':2, 'TwnhsE':2})
combined_train_test["oHouseStyle"] = combined_train_test.HouseStyle.map({'1.5Unf':1,
'1.5Fin':2, '2.5Unf':2, 'SFoyer':2,
'1Story':3, 'SLvl':3,
'2Story':4, '2.5Fin':4})
combined_train_test["oExterior1st"] = combined_train_test.Exterior1st.map({'BrkComm':1,
'AsphShn':2, 'CBlock':2, 'AsbShng':2,
'WdShing':3, 'Wd Sdng':3, 'MetalSd':3, 'Stucco':3, 'HdBoard':3,
'BrkFace':4, 'Plywood':4,
'VinylSd':5,
'CemntBd':6,
'Stone':7, 'ImStucc':7})
combined_train_test["oMasVnrType"] = combined_train_test.MasVnrType.map({'BrkCmn':1, 'None':1, 'BrkFace':2, 'Stone':3})
combined_train_test["oExterQual"] = combined_train_test.ExterQual.map({'Fa':1, 'TA':2, 'Gd':3, 'Ex':4})
combined_train_test["oFoundation"] = combined_train_test.Foundation.map({'Slab':1,
'BrkTil':2, 'CBlock':2, 'Stone':2,
'Wood':3, 'PConc':4})
combined_train_test["oBsmtQual"] = combined_train_test.BsmtQual.map({'Fa':2, 'None':1, 'TA':3, 'Gd':4, 'Ex':5})
combined_train_test["oBsmtExposure"] = combined_train_test.BsmtExposure.map({'None':1, 'No':2, 'Av':3, 'Mn':3, 'Gd':4})
combined_train_test["oHeating"] = combined_train_test.Heating.map({'Floor':1, 'Grav':1, 'Wall':2, 'OthW':3, 'GasW':4, 'GasA':5})
combined_train_test["oHeatingQC"] = combined_train_test.HeatingQC.map({'Po':1, 'Fa':2, 'TA':3, 'Gd':4, 'Ex':5})
combined_train_test["oKitchenQual"] = combined_train_test.KitchenQual.map({'Fa':1, 'TA':2, 'Gd':3, 'Ex':4})
combined_train_test["oFunctional"] = combined_train_test.Functional.map({'Maj2':1, 'Maj1':2, 'Min1':2, 'Min2':2, 'Mod':2, 'Sev':2, 'Typ':3})
combined_train_test["oFireplaceQu"] = combined_train_test.FireplaceQu.map({'None':1, 'Po':1, 'Fa':2, 'TA':3, 'Gd':4, 'Ex':5})
combined_train_test["oGarageType"] = combined_train_test.GarageType.map({'CarPort':1, 'None':1,
'Detchd':2,
'2Types':3, 'Basment':3,
'Attchd':4, 'BuiltIn':5})
combined_train_test["oGarageFinish"] = combined_train_test.GarageFinish.map({'None':1, 'Unf':2, 'RFn':3, 'Fin':4})
combined_train_test["oPavedDrive"] = combined_train_test.PavedDrive.map({'N':1, 'P':2, 'Y':3})
combined_train_test["oSaleType"] = combined_train_test.SaleType.map({'COD':1, 'ConLD':1, 'ConLI':1, 'ConLw':1, 'Oth':1, 'WD':1,
'CWD':2, 'Con':3, 'New':3})
combined_train_test["oSaleCondition"] = combined_train_test.SaleCondition.map({'AdjLand':1, 'Abnorml':2, 'Alloca':2, 'Family':2, 'Normal':3, 'Partial':4})
return "Done!"
# 特征处理
[In] map_values()
[Out] 'Done!'
# 去除两个不需要的特征
combined_train_test.drop("LotAreaCut",axis=1,inplace=True)
combined_train_test.drop(['SalePrice'],axis=1,inplace=True)
5.2 Pipeline
创建一个pipeline,方便将不同特征进行结合处理,并将三个与年份有关的特征进行 Label Encoding。
class labelenc(BaseEstimator, TransformerMixin):
def __init__(self):
pass
def fit(self,X,y=None):
return self
def transform(self,X):
lab=LabelEncoder()
X["YearBuilt"] = lab.fit_transform(X["YearBuilt"])
X["YearRemodAdd"] = lab.fit_transform(X["YearRemodAdd"])
X["GarageYrBlt"] = lab.fit_transform(X["GarageYrBlt"])
return X
class skew_dummies(BaseEstimator, TransformerMixin):
def __init__(self,skew=0.5):
self.skew = skew # 设置偏度阈值
def fit(self,X,y=None):
return self
def transform(self,X):
X_numeric=X.select_dtypes(exclude=["object"]) # 挑选出目标类型的列,这里挑出所有数值类型的数据,返回的是一个DataFrame
skewness = X_numeric.apply(lambda x: skew(x)) # apply方法在lambda运算时传入的都是series,计算出每个特征下的偏度,返回一个Series
skewness_features = skewness[abs(skewness) >= self.skew].index
X[skewness_features] = np.log1p(X[skewness_features]) # 进行正态分布化
X = pd.get_dummies(X) # 对整个X数据集进行One Hot编码
return X
# 编译管道
pipe = Pipeline([
('labenc', labelenc()),
('skew_dummies', skew_dummies(skew=1)),
])
# 复制原始数据以待后续使用
combined_train_test2 = combined_train_test.copy()
data_pipe = pipe.fit_transform(combined_train_test2)
scaler = RobustScaler()
# 分离train 与 test 的 X 值并进行管道处理
n_train=train.shape[0]
X = data_pipe[:n_train]
test_X = data_pipe[n_train:]
y= train.SalePrice
X_scaled = scaler.fit(X).transform(X)
y_log = np.log(train.SalePrice)
test_X_scaled = scaler.transform(test_X)
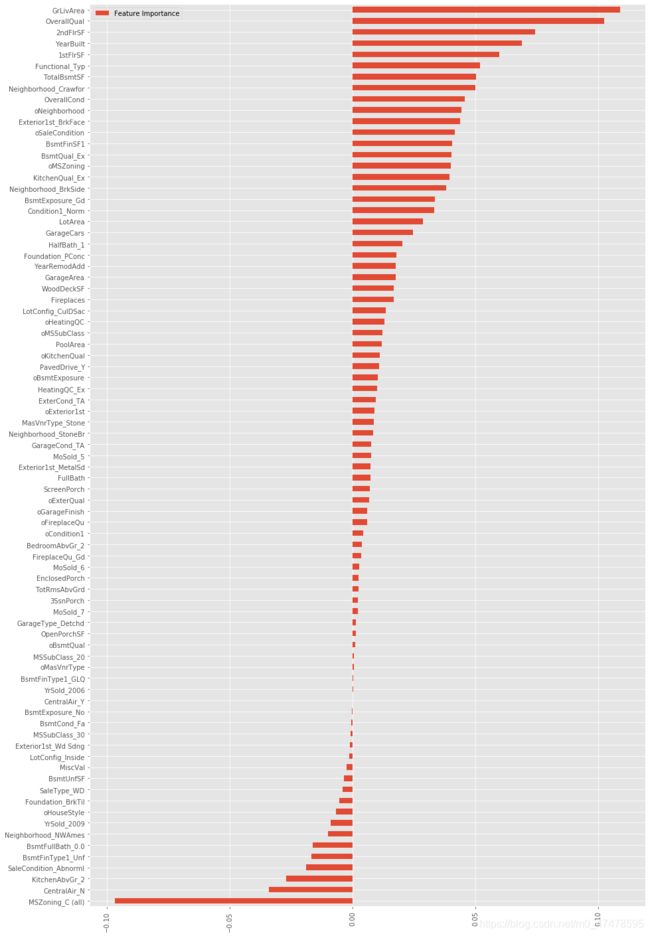
5.3 Feature Selection
lasso=Lasso(alpha=0.001)
lasso.fit(X_scaled,y_log)
# 正则化的回归模型 Lasso 回归 & Ridge 回归:
# 1. 所有参数绝对值之和,即L1范数,对应的回归方法叫做Lasso回归,L1是基于特征选择的方式,有多种求解方法,更加具有鲁棒性;
# 2. 所有参数的平方和,即L2范数,对应的回归方法叫做Ridge回归,岭回归。L2鲁棒性稍差,只有一种求解方式,而且不是基于特征选择的方式。
[Out] Lasso(alpha=0.001, copy_X=True, fit_intercept=True, max_iter=1000,
normalize=False, positive=False, precompute=False, random_state=None,
selection='cyclic', tol=0.0001, warm_start=False)
FI_lasso = pd.DataFrame({"Feature Importance":lasso.coef_}, index=data_pipe.columns)
FI_lasso[FI_lasso["Feature Importance"]!=0].sort_values("Feature Importance").plot(kind="barh",figsize=(15,25))
plt.xticks(rotation=90)
plt.show()
class add_feature(BaseEstimator, TransformerMixin):
def __init__(self,additional=1):
self.additional = additional
def fit(self,X,y=None):
return self
def transform(self,X):
if self.additional==1:
X["TotalHouse"] = X["TotalBsmtSF"] + X["1stFlrSF"] + X["2ndFlrSF"]
X["TotalArea"] = X["TotalBsmtSF"] + X["1stFlrSF"] + X["2ndFlrSF"] + X["GarageArea"]
else:
X["TotalHouse"] = X["TotalBsmtSF"] + X["1stFlrSF"] + X["2ndFlrSF"]
X["TotalArea"] = X["TotalBsmtSF"] + X["1stFlrSF"] + X["2ndFlrSF"] + X["GarageArea"]
X["+_TotalHouse_OverallQual"] = X["TotalHouse"] * X["OverallQual"]
X["+_GrLivArea_OverallQual"] = X["GrLivArea"] * X["OverallQual"]
X["+_oMSZoning_TotalHouse"] = X["oMSZoning"] * X["TotalHouse"]
X["+_oMSZoning_OverallQual"] = X["oMSZoning"] + X["OverallQual"]
X["+_oMSZoning_YearBuilt"] = X["oMSZoning"] + X["YearBuilt"]
X["+_oNeighborhood_TotalHouse"] = X["oNeighborhood"] * X["TotalHouse"]
X["+_oNeighborhood_OverallQual"] = X["oNeighborhood"] + X["OverallQual"]
X["+_oNeighborhood_YearBuilt"] = X["oNeighborhood"] + X["YearBuilt"]
X["+_BsmtFinSF1_OverallQual"] = X["BsmtFinSF1"] * X["OverallQual"]
X["-_oFunctional_TotalHouse"] = X["oFunctional"] * X["TotalHouse"]
X["-_oFunctional_OverallQual"] = X["oFunctional"] + X["OverallQual"]
X["-_LotArea_OverallQual"] = X["LotArea"] * X["OverallQual"]
X["-_TotalHouse_LotArea"] = X["TotalHouse"] + X["LotArea"]
X["-_oCondition1_TotalHouse"] = X["oCondition1"] * X["TotalHouse"]
X["-_oCondition1_OverallQual"] = X["oCondition1"] + X["OverallQual"]
X["Bsmt"] = X["BsmtFinSF1"] + X["BsmtFinSF2"] + X["BsmtUnfSF"]
X["Rooms"] = X["FullBath"]+X["TotRmsAbvGrd"]
X["PorchArea"] = X["OpenPorchSF"]+X["EnclosedPorch"]+X["3SsnPorch"]+X["ScreenPorch"]
X["TotalPlace"] = X["TotalBsmtSF"] + X["1stFlrSF"] + X["2ndFlrSF"] + X["GarageArea"] + X["OpenPorchSF"]+X["EnclosedPorch"]+X["3SsnPorch"]+X["ScreenPorch"]
return X
pipe = Pipeline([
('labenc', labelenc()),
('add_feature', add_feature(additional=2)),
('skew_dummies', skew_dummies(skew=1)),
])
5.4 PCA降维
combined_pipe = pipe.fit_transform(combined_train_test)
n_train=train.shape[0]
X = combined_pipe[:n_train]
test_X = combined_pipe[n_train:]
y= train.SalePrice
X_scaled = scaler.fit(X).transform(X)
y_log = np.log(train.SalePrice)
test_X_scaled = scaler.transform(test_X)
pca = PCA(n_components=410) # PCA算法中所要保留的主成分个数n,也即保留下来的特征个数n
X_scaled=pca.fit_transform(X_scaled)
test_X_scaled = pca.transform(test_X_scaled)
六、建模预测
def rmse_cv(model,X,y):
rmse = np.sqrt(-cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=5))
return rmse
models = [LinearRegression(),Ridge(),Lasso(alpha=0.01,max_iter=10000),RandomForestRegressor(),GradientBoostingRegressor(),SVR(),LinearSVR(),
ElasticNet(alpha=0.001,max_iter=10000),SGDRegressor(max_iter=1000,tol=1e-3),BayesianRidge(),KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5),
ExtraTreesRegressor(),XGBRegressor()]
names = ["LR", "Ridge", "Lasso", "RF", "GBR", "SVR", "LinSVR", "Ela","SGD","Bay","Ker","Extra","Xgb"]
for name, model in zip(names, models):
score = rmse_cv(model, X_scaled, y_log)
print("{}: {:.6f}, {:.4f}".format(name,score.mean(),score.std()))
LR: 657056741.178154, 456438248.6861
Ridge: 0.117596, 0.0091
Lasso: 0.121474, 0.0060
RF: 0.132595, 0.0065
GBR: 0.123860, 0.0072
SVR: 0.136997, 0.0122
LinSVR: 0.120965, 0.0098
Ela: 0.111113, 0.0059
SGD: 0.152374, 0.0141
Bay: 0.110576, 0.0060
Ker: 0.109276, 0.0055
Extra: 0.130409, 0.0056
Xgb: 0.139108, 0.0041
class grid():
def __init__(self,model):
self.model = model
def grid_get(self,X,y,param_grid):
grid_search = GridSearchCV(self.model,param_grid,cv=5, scoring="neg_mean_squared_error")
grid_search.fit(X,y)
print(grid_search.best_params_, np.sqrt(-grid_search.best_score_))
grid_search.cv_results_['mean_test_score'] = np.sqrt(-grid_search.cv_results_['mean_test_score'])
print(pd.DataFrame(grid_search.cv_results_)[['params','mean_test_score','std_test_score']])
grid(Lasso()).grid_get(X_scaled,y_log,{'alpha': [0.0004,0.0005,0.0007,0.0006,0.0009,0.0008],'max_iter':[10000]})
{‘alpha’: 0.0005, ‘max_iter’: 10000} 0.1112904354603362
params mean_test_score std_test_score
0 {‘alpha’: 0.0004, ‘max_iter’: 10000} 0.111457 0.001392
1 {‘alpha’: 0.0005, ‘max_iter’: 10000} 0.111290 0.001339
2 {‘alpha’: 0.0007, ‘max_iter’: 10000} 0.111532 0.001284
3 {‘alpha’: 0.0006, ‘max_iter’: 10000} 0.111353 0.001315
4 {‘alpha’: 0.0009, ‘max_iter’: 10000} 0.111910 0.001205
5 {‘alpha’: 0.0008, ‘max_iter’: 10000} 0.111700 0.001229
grid(Ridge()).grid_get(X_scaled,y_log,{'alpha':[35,40,45,50,55,60,65,70,80,90]})
{‘alpha’: 60} 0.11019645396734908
params mean_test_score std_test_score
0 {‘alpha’: 35} 0.110369 0.001268
1 {‘alpha’: 40} 0.110300 0.001249
2 {‘alpha’: 45} 0.110252 0.001234
3 {‘alpha’: 50} 0.110221 0.001222
4 {‘alpha’: 55} 0.110204 0.001213
5 {‘alpha’: 60} 0.110196 0.001204
6 {‘alpha’: 65} 0.110198 0.001198
7 {‘alpha’: 70} 0.110207 0.001192
8 {‘alpha’: 80} 0.110242 0.001184
9 {‘alpha’: 90} 0.110295 0.001177
grid(SVR()).grid_get(X_scaled,y_log,{'C':[11,12,13,14,15],'kernel':["rbf"],"gamma":[0.0003,0.0004],"epsilon":[0.008,0.009]})
{‘C’: 13, ‘epsilon’: 0.009, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.10822437796234463
params mean_test_score std_test_score
0 {‘C’: 11, ‘epsilon’: 0.008, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108653 0.001553
1 {‘C’: 11, ‘epsilon’: 0.008, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108305 0.001608
2 {‘C’: 11, ‘epsilon’: 0.009, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108642 0.001555
3 {‘C’: 11, ‘epsilon’: 0.009, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108289 0.001607
4 {‘C’: 12, ‘epsilon’: 0.008, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108596 0.001577
5 {‘C’: 12, ‘epsilon’: 0.008, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108272 0.001617
6 {‘C’: 12, ‘epsilon’: 0.009, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108579 0.001578
7 {‘C’: 12, ‘epsilon’: 0.009, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108241 0.001620
8 {‘C’: 13, ‘epsilon’: 0.008, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108554 0.001601
9 {‘C’: 13, ‘epsilon’: 0.008, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108240 0.001615
10 {‘C’: 13, ‘epsilon’: 0.009, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108548 0.001602
11 {‘C’: 13, ‘epsilon’: 0.009, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108224 0.001621
12 {‘C’: 14, ‘epsilon’: 0.008, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108490 0.001617
13 {‘C’: 14, ‘epsilon’: 0.008, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108235 0.001611
14 {‘C’: 14, ‘epsilon’: 0.009, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108474 0.001617
15 {‘C’: 14, ‘epsilon’: 0.009, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108232 0.001621
16 {‘C’: 15, ‘epsilon’: 0.008, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108467 0.001628
17 {‘C’: 15, ‘epsilon’: 0.008, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108241 0.001608
18 {‘C’: 15, ‘epsilon’: 0.009, ‘gamma’: 0.0003, ‘kernel’: ‘rbf’} 0.108436 0.001632
19 {‘C’: 15, ‘epsilon’: 0.009, ‘gamma’: 0.0004, ‘kernel’: ‘rbf’} 0.108244 0.001617
param_grid={'alpha':[0.2,0.3,0.4,0.5], 'kernel':["polynomial"], 'degree':[3],'coef0':[0.8,1,1.2]}
grid(KernelRidge()).grid_get(X_scaled,y_log,param_grid)
{‘alpha’: 0.2, ‘coef0’: 0.8, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.10826401034858327
params mean_test_score std_test_score
0 {‘alpha’: 0.2, ‘coef0’: 0.8, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108264 0.001209
1 {‘alpha’: 0.2, ‘coef0’: 1, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108503 0.001243
2 {‘alpha’: 0.2, ‘coef0’: 1.2, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108937 0.001286
3 {‘alpha’: 0.3, ‘coef0’: 0.8, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108394 0.001188
4 {‘alpha’: 0.3, ‘coef0’: 1, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108273 0.001210
5 {‘alpha’: 0.3, ‘coef0’: 1.2, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108500 0.001245
6 {‘alpha’: 0.4, ‘coef0’: 0.8, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108756 0.001181
7 {‘alpha’: 0.4, ‘coef0’: 1, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108294 0.001191
8 {‘alpha’: 0.4, ‘coef0’: 1.2, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108357 0.001219
9 {‘alpha’: 0.5, ‘coef0’: 0.8, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.109236 0.001180
10 {‘alpha’: 0.5, ‘coef0’: 1, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108424 0.001180
11 {‘alpha’: 0.5, ‘coef0’: 1.2, ‘degree’: 3, ‘kernel’: ‘polynomial’} 0.108339 0.001201
grid(ElasticNet()).grid_get(X_scaled,y_log,{'alpha':[0.0005,0.0008,0.004,0.005],'l1_ratio':[0.08,0.1,0.3,0.5,0.7],'max_iter':[10000]})
{‘alpha’: 0.005, ‘l1_ratio’: 0.08, ‘max_iter’: 10000} 0.11116534330224491
params mean_test_score std_test_score
0 {‘alpha’: 0.0005, ‘l1_ratio’: 0.08, ‘max_iter’: 10000} 0.116542 0.002025
1 {‘alpha’: 0.0005, ‘l1_ratio’: 0.1, ‘max_iter’: 10000} 0.116015 0.002007
2 {‘alpha’: 0.0005, ‘l1_ratio’: 0.3, ‘max_iter’: 10000} 0.113110 0.001819
3 {‘alpha’: 0.0005, ‘l1_ratio’: 0.5, ‘max_iter’: 10000} 0.112092 0.001596
4 {‘alpha’: 0.0005, ‘l1_ratio’: 0.7, ‘max_iter’: 10000} 0.111618 0.001435
5 {‘alpha’: 0.0008, ‘l1_ratio’: 0.08, ‘max_iter’: 10000} 0.114753 0.001937
6 {‘alpha’: 0.0008, ‘l1_ratio’: 0.1, ‘max_iter’: 10000} 0.114242 0.001904
7 {‘alpha’: 0.0008, ‘l1_ratio’: 0.3, ‘max_iter’: 10000} 0.112055 0.001596
8 {‘alpha’: 0.0008, ‘l1_ratio’: 0.5, ‘max_iter’: 10000} 0.111410 0.001384
9 {‘alpha’: 0.0008, ‘l1_ratio’: 0.7, ‘max_iter’: 10000} 0.111313 0.001324
10 {‘alpha’: 0.004, ‘l1_ratio’: 0.08, ‘max_iter’: 10000} 0.111272 0.001382
11 {‘alpha’: 0.004, ‘l1_ratio’: 0.1, ‘max_iter’: 10000} 0.111203 0.001326
12 {‘alpha’: 0.004, ‘l1_ratio’: 0.3, ‘max_iter’: 10000} 0.112478 0.001159
13 {‘alpha’: 0.004, ‘l1_ratio’: 0.5, ‘max_iter’: 10000} 0.113872 0.001184
14 {‘alpha’: 0.004, ‘l1_ratio’: 0.7, ‘max_iter’: 10000} 0.115214 0.001241
15 {‘alpha’: 0.005, ‘l1_ratio’: 0.08, ‘max_iter’: 10000} 0.111165 0.001312
16 {‘alpha’: 0.005, ‘l1_ratio’: 0.1, ‘max_iter’: 10000} 0.111186 0.001277
17 {‘alpha’: 0.005, ‘l1_ratio’: 0.3, ‘max_iter’: 10000} 0.112979 0.001158
18 {‘alpha’: 0.005, ‘l1_ratio’: 0.5, ‘max_iter’: 10000} 0.114729 0.001214
19 {‘alpha’: 0.005, ‘l1_ratio’: 0.7, ‘max_iter’: 10000} 0.116230 0.001247
class AverageWeight(BaseEstimator, RegressorMixin):
def __init__(self,mod,weight):
self.mod = mod
self.weight = weight
def fit(self,X,y):
self.models_ = [clone(x) for x in self.mod]
for model in self.models_:
model.fit(X,y)
return self
def predict(self,X):
w = list()
pred = np.array([model.predict(X) for model in self.models_])
# for every data point, single model prediction times weight, then add them together
for data in range(pred.shape[1]):
single = [pred[model,data]*weight for model,weight in zip(range(pred.shape[0]),self.weight)]
w.append(np.sum(single))
return w
lasso = Lasso(alpha=0.0005,max_iter=10000)
ridge = Ridge(alpha=60)
svr = SVR(gamma= 0.0004,kernel='rbf',C=13,epsilon=0.009)
ker = KernelRidge(alpha=0.2 ,kernel='polynomial',degree=3 , coef0=0.8)
ela = ElasticNet(alpha=0.005,l1_ratio=0.08,max_iter=10000)
bay = BayesianRidge()
# 权重赋值
w1 = 0.02
w2 = 0.2
w3 = 0.25
w4 = 0.3
w5 = 0.03
w6 = 0.2
weight_avg = AverageWeight(mod = [lasso,ridge,svr,ker,ela,bay],weight=[w1,w2,w3,w4,w5,w6])
rmse_cv(weight_avg,X_scaled,y_log), rmse_cv(weight_avg,X_scaled,y_log).mean()
[Out] (array([0.10424901, 0.10955877, 0.11835667, 0.10016304, 0.10609544]),
0.10768458422996707)
weight_avg = AverageWeight(mod = [svr,ker],weight=[0.5,0.5])
rmse_cv(weight_avg,X_scaled,y_log), rmse_cv(weight_avg,X_scaled,y_log).mean()
[Out] (array([0.10273174, 0.1093225 , 0.11762506, 0.09857604, 0.10516214]),
0.10668349587194885)
class stacking(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self,mod,meta_model):
self.mod = mod
self.meta_model = meta_model
self.kf = KFold(n_splits=5, random_state=42, shuffle=True)
def fit(self,X,y):
self.saved_model = [list() for i in self.mod]
oof_train = np.zeros((X.shape[0], len(self.mod)))
for i,model in enumerate(self.mod):
for train_index, val_index in self.kf.split(X,y):
renew_model = clone(model)
renew_model.fit(X[train_index], y[train_index])
self.saved_model[i].append(renew_model)
oof_train[val_index,i] = renew_model.predict(X[val_index])
self.meta_model.fit(oof_train,y)
return self
def predict(self,X):
whole_test = np.column_stack([np.column_stack(model.predict(X) for model in single_model).mean(axis=1)
for single_model in self.saved_model])
return self.meta_model.predict(whole_test)
def get_oof(self,X,y,test_X):
oof = np.zeros((X.shape[0],len(self.mod)))
test_single = np.zeros((test_X.shape[0],5))
test_mean = np.zeros((test_X.shape[0],len(self.mod)))
for i,model in enumerate(self.mod):
for j, (train_index,val_index) in enumerate(self.kf.split(X,y)):
clone_model = clone(model)
clone_model.fit(X[train_index],y[train_index])
oof[val_index,i] = clone_model.predict(X[val_index])
test_single[:,j] = clone_model.predict(test_X)
test_mean[:,i] = test_single.mean(axis=1)
return oof, test_mean
a = SimpleImputer().fit_transform(X_scaled)
b = SimpleImputer().fit_transform(y_log.values.reshape(-1,1)).ravel()
stack_model = stacking(mod=[lasso,ridge,svr,ker,ela,bay],meta_model=ker)
print(rmse_cv(stack_model,a,b))
print(rmse_cv(stack_model,a,b).mean())
[Out] [0.1032947 0.10976335 0.11720464 0.09831134 0.10430456]
0.1065757181808159
X_train_stack, X_test_stack = stack_model.get_oof(a,b,test_X_scaled)
X_train_add = np.hstack((a,X_train_stack))
X_test_add = np.hstack((test_X_scaled,X_test_stack))
print(rmse_cv(stack_model,X_train_add,b))
print(rmse_cv(stack_model,X_train_add,b).mean())
[Out] [0.098731 0.10513196 0.11222577 0.09394461 0.0991052 ]
0.1018277071784219
七、提交
# 最终模型
stack_model = stacking(mod=[lasso,ridge,svr,ker,ela,bay],meta_model=ker)
stack_model.fit(a,b)
[Out] stacking(meta_model=KernelRidge(alpha=0.2, coef0=0.8, degree=3, gamma=None,
kernel=‘polynomial’, kernel_params=None),
mod=[Lasso(alpha=0.0005, copy_X=True, fit_intercept=True,
max_iter=10000, normalize=False, positive=False,
precompute=False, random_state=None, selection=‘cyclic’,
tol=0.0001, warm_start=False),
Ridge(alpha=60, copy_X=True, fit_intercept=True, max_iter…
l1_ratio=0.08, max_iter=10000, normalize=False,
positive=False, precompute=False, random_state=None,
selection=‘cyclic’, tol=0.0001, warm_start=False),
BayesianRidge(alpha_1=1e-06, alpha_2=1e-06, alpha_init=None,
compute_score=False, copy_X=True,
fit_intercept=True, lambda_1=1e-06, lambda_2=1e-06,
lambda_init=None, n_iter=300, normalize=False,
tol=0.001, verbose=False)])
pred = np.exp(stack_model.predict(test_X_scaled))
result=pd.DataFrame({'Id':test.Id, 'SalePrice':pred})
result.to_csv("submission.csv",index=False)