基于感知哈希和kd树索引的图像搜索引擎
基于感知哈希和kd树索引的图像搜索引擎
研究背景
随着移动社交的普及,对多媒体如图像,视频,音频等的需求更加普遍和个性,作为社交类app之一的来往也不例外,用户每天产生的大量图片,短片等,运营人员不论是出于审核原因还是普通的图像搜索目的都使得有必要提供一个针对全来往的图像,视频等的搜索查询功能。
图像搜索的第一步便是提取图像特征,图像特征的提取方式依赖应用场景的不同相差很大,因为实际的图像不仅有编码的不同,颜色等视觉特征不同,更重要的是图像可能会遭受到各种各样的变换如亮度改变,直方图矫正,图像旋转,剪切,拼接等几何变换,导致图像特征提取和搜索难度加大。
目前对于图像特征提取分为颜色特征,纹理特征,形状特征等,这些特征又分为全局特征和局部特征,前者对整幅图像用一个特征向量表示,后者如SIFT等将图像提取若干特征向量。接下来困扰图像搜索的难题是特征匹配。因为图像提取的特征基本都是高维特征,维度少则几十,多则上百,对特征的匹配不是简单地相等匹配而是向量距离匹配,要求向量匹配不仅支持最近邻查询还要支持范围查询,这些使得面对大规模数据集查询时面临极大困难,目前的通用搜索。虽然针对上面两个基本问题,大量的解决方案提出,但是使用场景不同,算法复杂度不同使得没有通用的解决方案,只有结合具体场景的特定方式,目前百度和google都推出自己的以图搜图功能,于是来往即使不能超越也不能落后太远。
本文针对以上问题,设计一套自己的针对图像的搜索系统。
图像特征提取
一张图片就是一个二维信号,它包含了不同频率的成分。如下图所示,亮度变化小的区域是低频成分,它描述大范围的信息。而亮度变化剧烈的区域(比如物体的边缘)就是高频的成分,它描述具体的细节。或者说高频可以提供图片详细的信息,而低频可以提供一个框架。于是能否提取这样一种表示图像轮廓的特征来表示图像呢?下面将引进Neal Krawetz博士的”感知哈希算法",他的工作原理是将每张图片生成一个"指纹"(fingerprint)字符串,然后比较不同图片的指纹。结果越接近,就说明图片越相似。算法很简单,其过程描述如下:
1. 缩小尺寸。
将图片缩小到8x8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。
2. 简化色彩。
将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
3. 计算平均值。
计算所有64个像素的灰度平均值。
4. 第四步,比较像素的灰度。
将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
5. 计算哈希值。
将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。
得到指纹以后,就可以对比不同的图片,看看64位中有多少位是不一样的。在理论上,这等同于计算"汉明距离"(Hammingdistance)。如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。这种算法的优点是简单快速,不受图片大小缩放的影响,缺点是图片的内容不能有大的改动,如剪切等。
实际应用中,往往采用更强大的pHash算法.唯一不同的是将上述算法的3和4换成如下:
(3)计算DCT:计算图片的DCT变换,得到32*32的DCT系数矩阵。
(4)缩小DCT:虽然DCT的结果是32*32大小的矩阵,但我们只要保留左上角的8*8的矩阵,这部分呈现了图片中的最低频率。
特征匹配查询
感知哈希实际是一个长度为64位的向量,通常向量的查询需要依据距离函数来搜索与该向量距离在给定范围内的其他向量或者查找与给定向量距离最近的K个向量,前者称为范围查询,后者称为K近邻查询。在大数据集比如图片数量级在千万甚至上亿时候,通常的全量匹配无法进行,为此本文利用k-d树的方式将所有特征划分为N个区间,搜索时候,根据查询向量计算其落的区间,然后在区间中进一步搜索,剔除距离过大的向量,保留距离在一定限度范围内的向量。
k-d tree是英文K-dimensiontree的缩写,是对数据点在k维空间中划分的一种数据结构。实质上,K-d树是一颗满二叉树,只不过数据点只存放在叶子节点,非叶子节点只存储当前划分维度和当前维度的分列值以及当前节点的左右节点。
通常划分节点需要保证节点划分的区分性和k-d树结构的平衡性。给定数据集,通常的做法是统计它们在每个维上的方差,挑选出方差中的最大值,对应的维就是划分域的值。数据方差最大表明沿该维度数据点分散得比较开,这个方向上进行数据分割可以获得最好的分辨率;然后再将所有样本点按其第分列维的值进行排序,位于正中间的那个数据点选为分裂结点的分列域。
Kd-Tree的构建算法可描述如下:
(1) 在K维数据集合中选择具有最大方差的维度k,然后在该维度上选择中值m为pivot对该数据集合进行划分,得到两个子集合;同时创建一个树结点node,用于存储;
(2)对两个子集合重复(1)步骤的过程,直至所有子集合都不能再划分为止;如果某个子集合不能再划分时,则将该子集合中的数据保存到叶子结点(leaf node)。
实际中,为保证k-d树的查询效率必须限制树的高度,因为当向量维度大于一定值的时候,比如100,查询效率急剧下降。此外针对大规模数据集统计每个维度的方差和中间值将是个巨大费时的任务,考虑到图像感知特征的特殊性,将64位整数表示成长度为16的16进制字符串,每个维度的字符范围在0~9a~f之间,于是每个维度的划分值可简单的设定为中间值8,划分维度考虑到固定哈希值的长度,这里维度值设为0~16之间的随机值。K-d树每层用同样的维度划分。
Java实现的高度为level的k-d树建立如下:
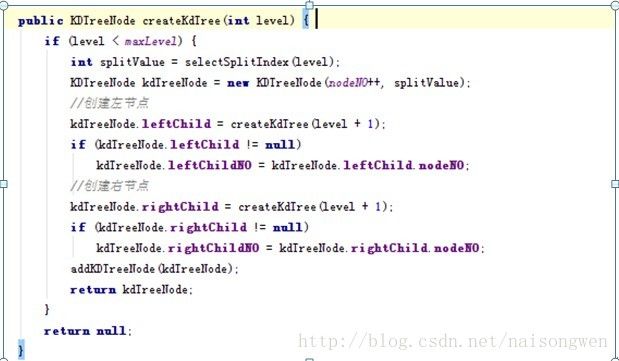

例如给定二维数据集合:(2,3),(5,4), (9,6), (4,7), (8,1), (7,2),利用上述算法构建一棵Kd-tree。左图是Kd-tree对应二维数据集合的一个空间划分,右图是构建的一棵Kd-tree。
因为叶子节点只存放数据,非叶子节点只存放搜索路径信息,这里level设为17,于是数据集被划分为128k个区间,数据在每个区间的存放方式可以自由设定,如果每个区间存放128k个图像id(比如缓存tair),则该k-d树可以索引的数据库规模为16G,轻松应对可以预见的数据集规模。
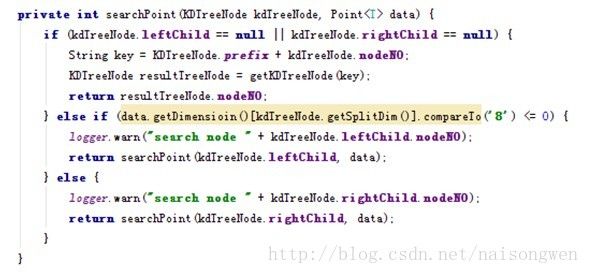
k-d树的搜索
同k-d树的创建过程一样,首先通过比较待查询节点和k-d树中分裂节点的分裂维的值,如果小于或等于分裂节点的分裂维的值,就进入左子树分支,否则就进入右子树分支搜索,直到叶子结点,也就是与待查询点处于同一个子空间的叶子结点;然后再回溯搜索路径,并判断搜索路径上的结点的其他子结点空间中是否可能有距离查询点更近的数据点,如果有可能,则需要跳到其他子结点空间中去搜索(将其他子结点加入到搜索路径)。重复这个过程直到根节点。
k-d树的搜索代价大多在找到叶子节点时候的回溯找到其他未搜索的分支,关于k-d树的回溯优化方式,这里不赘述。
根据查询图像特征值,查询相似图像的区间算法如下:
1. 王志瑞,闫彩良图像特征提取方法的综述. 吉首大学学报(自然科学版)2011 VOL.32 NO.5
2. 徐庆 ,杨 维维 ,陈生潭 基于 内容的图像检索技术 计 算 机 技 术 与 发 展
2.2008 VOL.18 NO.1
3. David G. Lowe,"Distinctive image features from scale-invariant keypoints," InternationalJournal of Computer Vision, 60, 2 (2004), pp. 91-110
4. http://www.hackerfactor.com/blog/index.php?/archives/432-Looks-Like-It.html
5. http://phash.org/docs/pubs/thesis_zauner.pdf
6. An intoductory tutorial on kd-trees AndrewW.Moore