面试总结4 tcp断开与连接的过程、数据结构是什么怎么存放数据、排序算法适用场景、post请求乱码的解决过程、ArrayList怎样让其线程安全、Ithings,聚乐商城项目、Mysql瓶颈和什么有关
总内容
tcp断开与连接的过程(三次握手与四次分手)
数据结构是什么,怎么存放数据。
常见的排序算法?排序算法适用场景?
说一下post请求乱码的解决过程
ArrayList是线程不安全的嘛?怎样让其线程安全
Hashmap怎么保证键唯一?
Rabbitmap的适用场景(高并发的解决数据、生产者与消费者(异步调用)、限流、解耦)?
比如Hashmap不安全,怎样让他安全?自己的理解?
设计模式中自己最常用的是哪几种设计模式?
反射中的几种方式能得到字节码对象?
Ithings项目
聚乐商城项目
zuul是怎样实现限流的
数据库索引怎样创建?作用?有几种
购物车后端是怎样处理高并发的?
Spring Cloud的组件?有哪几种负载均衡的方式
ioc怎么注入?有哪几种注入方式?
数据库用户表的id是怎么生成的?
UUId会重复吗?
Mysql瓶颈和什么有关
Rabbitmq怎么保证消息的稳定性? Rabbitmq 怎么避免消息丢失?
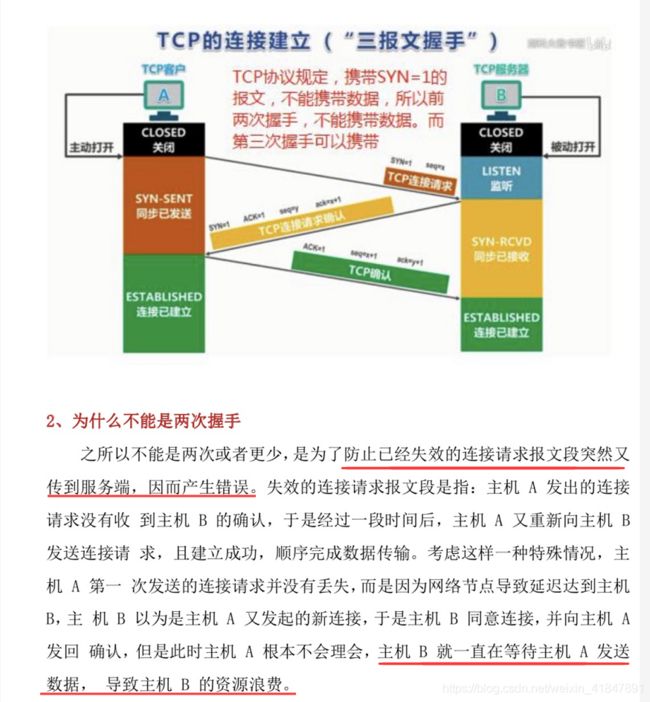
1 tcp断开与连接的过程(三次握手与四次分手)

2数据结构是什么,怎么存放数据。
数据结构是数据结构是计算机存储、组织数据的方式,相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成.
数据结构有逻辑上的数据结构和物理上的数据结构之分。逻辑上的数据结构反映成分数据之间的逻辑关系,
而物理上的数据结构反映成分数据在计算机内部的存储安排。数据结构是数据存在的形式。
数据的逻辑结构分为线性结构和非线性结构。
常用的线性结构有:线性表,栈,队列,双队列,数组,串。
常见的非线性结构有:二维数组,多维数组,广义表,树(二叉树等),图,堆。
存放数据的存储方式有顺序存储方法、链接存储方法、索引存储方法和散列存储方法这四种。
1、顺序存储方式:顺序存储方式就是在一块连续的存储区域一个接着一个的存放数据,
把逻辑上相连的结点存储在物理位置上相邻的存储单元里,结点间的逻辑关系由存储单元的邻接挂安息来体现。
顺序存储方式也称为顺序存储结构,一般采用数组或者结构数组来描述
2、链接存储方法:它比较灵活,其不要求逻辑上相邻的结点在物理位置上相邻,
结点间的逻辑关系由附加的引用字段表示。一个结点的引用字段往往指导下一个结点的存放位置
3、索引存储方法:除建立存储结点信息外,还建立附加的索引表来标识结点的地址
4、散列存储方法:就是根据结点的关键字直接计算出该结点的存储地址3常见的排序算法?排序算法适用场景?
1、 冒泡排序:适用场景:适用于n较小的情况
2、 选择排序:适用场景:适用于n较小的情况。运行时间和输入无关
3、直接插入排序:适用场景:当数据已经基本有序时,采用插入排序可以有效减少数据交换和数据移动次数,进
而提升排序效率,数据量小时使用。并且大部分已经被排序。
4、快速排序:适用场景:是最快的通用排序算法,大多数使用情况下,是最佳选择。
5、归并排序:适用场景:如果需要稳定,空间不是很重要,就选择归并排序4说一下post请求乱码的解决过程
1 springMVC已经提供了轮子给我们使用,在web.xml添加post乱码filter
在web.xml中加入:
CharacterEncodingFilter
org.springframework.web.filter.CharacterEncodingFilter
encoding
utf-8
CharacterEncodingFilter
/*
2 requesrt.setCharacterEncoding("utf-8") 请求
response.setContentType("text/html;charset=UTF-8"); 响应
3 在tomcat的配置文件 apache-tomcat-7.0.70/conf/server.xml中
5 ArrayList是线程不安全的嘛?怎样让其线程安全
1 重写或按需求编写自己的方法,这些方法要写成synchronized里面,在这些 synchronized的方法中调用
ArrayList的方法。
2 使用synchronized关键字
假如你创建的代码如下:List data=new ArrayList();
那么为了解决这个线程安全问题你可以这么使用Collections.synchronizedList(),如:
List data=Collections.synchronizedList(new ArrayList());
其他的都没变,使用的方法也几乎与ArrayList一样, 6Hashmap怎么保证键唯一?
重写hashcode和equals方法7Rabbitmap的适用场景(高并发的解决数据、生产者与消费者(异步调用)、限流、解耦)?
1 解决高并发数据
2 生产者和消费者(异步调用)
3 限流
4 解耦 消息是无关平台和语言的8比如Hashmap不安全,怎样让他安全?自己的理解?
1、通过Collections.synchronizedMap()返回一个新的Map,这个新的map就是线程安全的.
这里返回的并不是HashMap,而是一个Map的实现.
2、重新改写了HashMap,具体的可以查看java.util.concurrent.ConcurrentHashMap. 这个方法比方法一有了很大的改进.9设计模式中自己最常用的是哪几种设计模式?
1 单例模式
2 工厂模式
3 观察者模式10反射中的几种方式能得到字节码对象?

11Ithings项目
这个项目有两部分组成,一个是网关,一个是ithings云平台。将传感器数据传输到网关,网关对这些数据进行处理,比如统一为json格式。
然后将这些数据上传到ithings云平台。接着ithings云平台对这些数据进行统一的管理,这样的可以对这些数据进行统一的挖掘。
这个网关已经在汉江投入使用了,主要测的是汉江的水情。
同时后来有家公司和我老师合作,主要测甲烷,我们对这些气体做一个阈值的测定。当气体超过这些阈值的时候,进行报警。
对开关进行反向控制,就可以关闭开关,这样就能及时预警,不会让气体含量超标。
其中传感器中集成mysql,采集到的数据存入mysql,每10秒采集一次,采集到后传入云平台,其中传感器中的mysql有自动删除功能,
数据量到达一定程度就自动删除了。然后我负责就是连接云平台,从云平台下载数据,然后通过页面个性化展示给用户,
通过java的一个jfreechat这个插件可以个性化展示,比如柱状图,饼图,折线图,可以看出变化规律和分析发展趋势
12聚乐商城项目
1、基于springCloud框架,包含商品模块,商品详情模块,搜素模块,购物车模块
里面用到了不少新的技术,比如zuul作为网关,主要起路由的作用,也起到请求限流的作用。
用nginx解决了一个域名的问题,比如没有解决域名问题的话,要在浏览器访问某个服务的话,需要输入ip和端口号,
nginx解决域名问题,主要是反向代理,他默认的端口号是80,这样的话在浏览器输入地址的话,默认跳转到80端口,
这样正好被nginx监听到,然后在ngingx里面做一个配置,location_proxy后面接一个ip和端口号,
这样就能直接跳转到代理的服务上面,
用eraka注册微服务,将各种微服务注册进eraka,如有要拉取服务的话,直接从eraka里面直接调用,这样很方便,便于治理。
2、数据库那部分,用户没有登录的时候,将数据存储到localstore里面,将localstore充当一个购物车。主要用localstore而不用cookie,
因为cookie大小有限制,每个大小为4KB,每个浏览器最多有20个,如果在购物车里面加入大量商品的话,不太合适。
还有一个就是每次请求的时候都需要携带一个cookies,这样很占用带宽。
localstore是一个本地存储,是一个持久化存储,除非你手动删除他,不然他不会消失。当用户登录以后,我存储在reids数据库,
这里用redis而不用mysql,是因为关系型数据库写的性能是不好的,redis是基于内存的,写的性能很高的,
还有一个是购物车里面的数据怎么样同步的一个问题。比如mysql里面的数据商品下架了,或者商品的价格变了,
怎么样同时将redis也就是购物车里面的数据也变化,他们之间的通信用的是rabbitmq来进行相互通信。12 zuul是怎样实现限流的

13数据库索引怎样创建?作用?有几种
1、创建索引
CREATE INDEX index_Name ON table(username(length));//普通索引
创建表的时候直接指定:
CREATE TABLE table(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [index_Name] (username(length)) //普通索引
);
ALTER TABLE table ADD INDEX index_Name (name) //普通索引
ALTER TABLE table ADD UNIQUE (name) //联合索引
ALTER TABLE table ADD PRIMARY KEY (name) //主键索引
2 查看索引
show index from table;
show keys from table;
3删除索引:
DROP INDEX index_Name ON table
ALTER TABLE table DROP INDEX index_Name
ALTER TABLE table DROP PRIMARY KEY
作用就是帮助高效查找数据,有普通索引,联合索引,主键索引,聚合索引14购物车后端是怎样处理高并发的?
高并发的处理:
① 配置多个Linux外部服务器,Nginx反向代理。
② 增加缓存服务器,将数据放入内存里面,增加读取速度。
③ 搭建Redis集群。
④ 做数据分离(建立历史表,用的技术是Quartz(每天定时定点的执行任务))。
⑤ 优化成一个存储过程,只调用一次数据库,从而缩短数据库的访问时间。
分层
后台主要有两块,一块是数据库,一块的业务块
数据库层使用的优化手段
1.分库分表。但是在做设计的时候最好考虑到在不停机的状态下可以对库表进行扩容。
2.sql的优化。查询时指定列名,使用索引,用between代替in......
业务层优化
1.在分布式事务中,有一个有名的cap(一致性,可用性,分区容忍性)理论,事实告诉我们很难三
个特都满足,一般业界用的最多就是使用mq来保证事务的最终一直性(可以有延迟,但是最终正确
结果用户还是可以看到的)解决分布式事务也很强劲。代码设计中如果可以不要锁最好就不使用,
如果要使用也优先考虑重入锁,乐观锁。
2.控制请求
有可能访问量就是很大,而你的服务最多只能承受住1000万的访问量,其他请求你可以用队列做延
时等待处理(最好考虑到时效性),也可以抛弃请求。如果有用户恶意刷流量,可以通过代码限制
ip访问量,也可以通过nginx限控。
3.服务宕机
服务有的时候并不是100%可靠的,这是需要做服务的熔断处理。服务在一定的时间端内发送的请求
都不能响应,那么应该从服务器集群中将这个服务设置到为未可完全使用状态。通过定时机制向集
群发送自身的健康状况,如果过一段时间服务好了,那它可以从集群中分一部分流量响应,响应正
常的话,使它重新加入集群变为可用状态。如果过一段时间服务还是没有好,集群就将它彻底从服
务中删除
4.响应速度
在高并发的访问中,接口的响应速度需要尽可能的快。从两个方面来谈谈这个问题:
4.1.jvm层
尽量不要触发full gc,这个过程耗时非常严重,同时young gc的时间也需要尽可能的短,超过1s
就要找找耗时点。
4.2.代码层
使用缓存服务(本地缓存,redis...),使用异步方式(线程池...)调用。
4.3.系统层
集群....
15Spring Cloud的组件?有哪几种负载均衡的方式
Eureka、Ribbon、Hystrix、Zuul、Config
1 轮训
2 随机
3 iphash
4 智能路由
5 加权16 ioc怎么注入?有哪几种注入方式?
见前面的ioc的博客17数据库用户表的id是怎么生成的?

18 UUId会重复吗?
会
“重复是肯定会重复的,32位的UUID,经过16^32+1次生成后,必然会产生至少一次重复,当然,不追求这个必然,
偶然产生一次重复需要的平均次数比这个少得多。”
但是基本不影响咱们的正常使用,基本不会遇到19 Mysql瓶颈和什么有关
mysql的一个优化和瓶颈分析,就是在现有的资源上“读”&“写”之间的再平衡
MySQL数据库优化可以在多个不同的层级进行,常见的有sql优化,配置参数优化,数据库架构优化等这几方面
1、这个sql优化,就是来看有那个sql拖慢了程序运行,或者造成了内存等方面的困扰。找到它并且修改它。因为程序运行之初,
谁都不知道哪里的sql会出现问题。所以我们不妨借助一些检测工具或者命令来查看,其中explain这个就厉害了
2、配置参数就是通过工具或者show global status 的各个计数器的值来分析出当前瓶颈所在,
再结合一些简单的系统层面的监控工具如top iostat 就能明确瓶颈。完事就是平衡“读”&“写”之间的关系了。
根据瓶颈所在,不断地调整各个参数的值,最终达到一个完整的平衡。
3、数据库架构的优化了。这个,范围就大了,在下也不敢多言,只能说最终的无非就是集群,20 Rabbitmq怎么保证消息的稳定性? Rabbitmq 怎么避免消息丢失?
1 保证消息的稳定性:
提供了事务的功能。
通过将 channel 设置为 confirm(确认)模式。
2 避免消息丢失
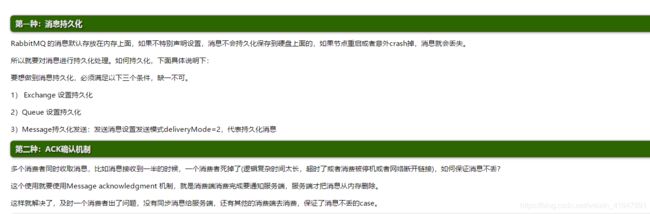
消息持久化
ACK确认机制
设置集群镜像模式
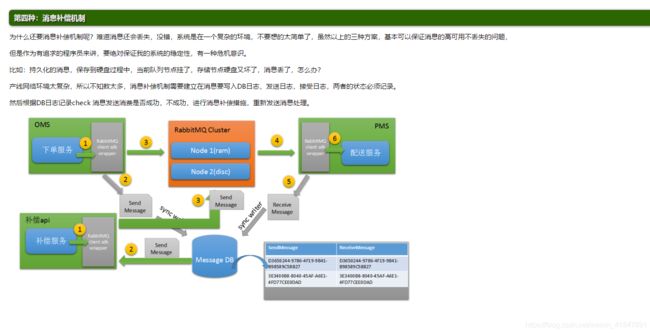
消息补偿机制