面试总结2 jvm里面会什么会有程序计数器、常用的垃圾回收算法gc、mybatis与jdbc的区别、union和union all的区别、zookeeper与eureka的区别、
总内容
jvm里面会什么会有程序计数器
常用的垃圾回收算法gc
mybatis与jdbc的区别
union和union all的区别
zookeeper与eureka的区别
读写锁与可重入锁的(Reentrantlock)与不可重入锁的区别
负载均衡的算法
动态代理具体代码
数据库联合索引(a,b)
concourthashmap能代替hashtable吗?
谈谈事务中的redo-log和undo-log日志的作用
内存模型和内存屏障(volatile变量的内存可见性保证原理基于内存屏障)
锁的底层-操作系统方面的实现
锁的实现
servlet与filter的区别
Servlet2.0与3.0与4.0的区别?
java四种元注解
mysql默认隔离级别是可重复读,修改count字段+1,多个线程会有问题吗?
19 Aop里面cglib能代替动态代理吗?
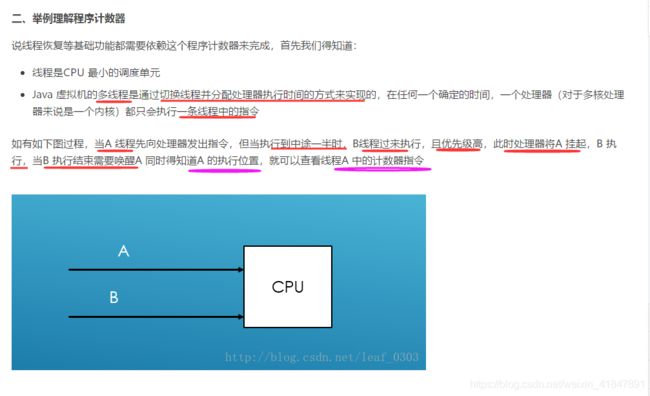
1 jvm里面会什么会有程序计数器
特 点
如果线程正在执行的是Java 方法,则这个计数器记录的是正在执行的虚拟机字节码指令地址
如果正在执行的是Native 方法,则这个技术器值为空(Undefined)
此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域
为什么执行Native方法为空呢?
java中有两种方法:java方法和本地方法。java方法是有java语言编写,编译成字节码,
存储在class文件中的。本地方法是有其它语言(比如C,C++,或者是会变语言)编写的,
编译成和处理器相关的机器代码。由上我们知道计数器记录的字节码指令地址,但是native 本地
(如:System.currentTimeMillis()/ public static native long currentTimeMillis();)
方法是大多是通过C实现并未编译成需要执行的字节码指令所以在计数器中当然是空(undefined).


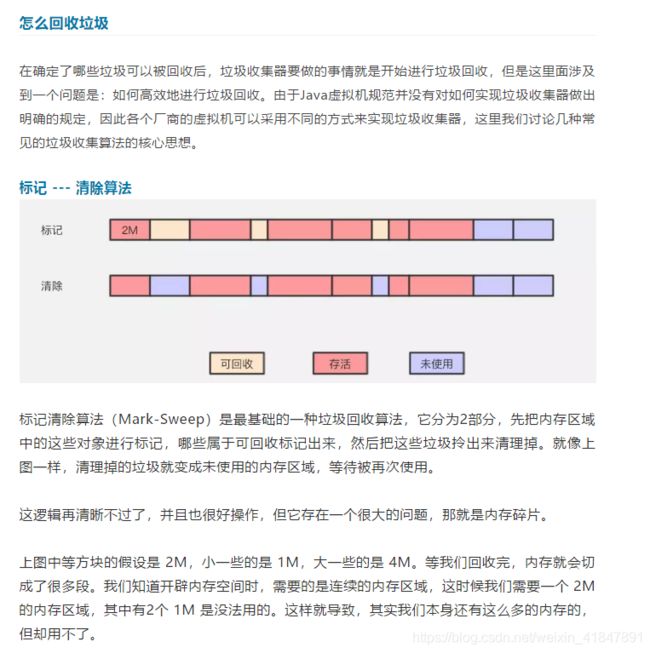
2 常用的垃圾回收算法gc



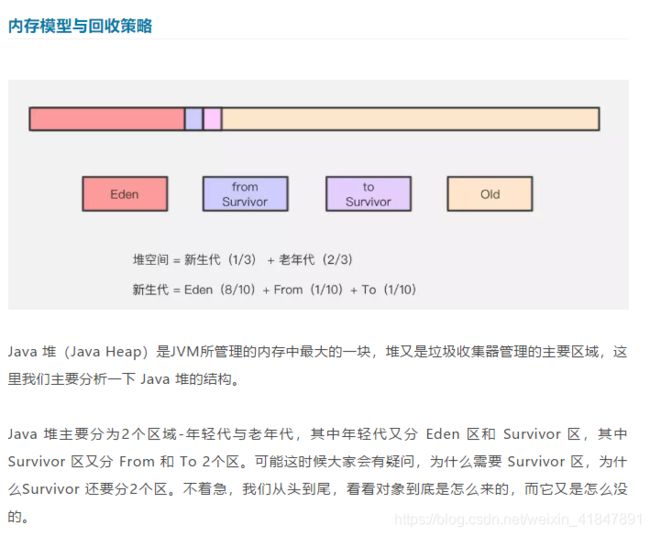



3 mybatis与jdbc的区别


JDBC是Java提供的一个操作数据库的API;
MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架。
MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装。
MyBatis可以使用简单的XML或注解用于配置和原始映射,
将接口和Java的POJO(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录。MyBatis是对JDBC的封装。相对于JDBC,MyBatis有以下优点
1 SQL统一管理,对数据库进行存取操作
我们使用JDBC对数据库进行操作时,SQL查询语句分布在各个Java类中,这样可读性差,不利于维护,
当我们修改Java类中的SQL语句时要重新进行编译。
Mybatis可以把SQL语句放在配置文件中统一进行管理,以后修改配置文件,也不需要重新就行编译部署。
2 生成动态SQL语句
我们在查询中可能需要根据一些属性进行组合查询,比如我们进行商品查询,
我们可以根据商品名称进行查询,也可以根据发货地进行查询,或者两者组合查询。
如果使用JDBC进行查询,这样就需要写多条SQL语句。
Mybatis可以在配置文件中通过使用
4 union和union all的区别

5 zookeeper与eureka的区别

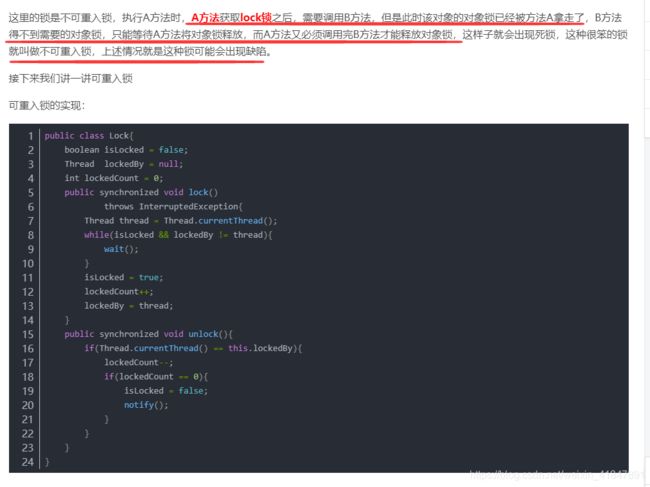
6 读写锁与可重入锁的(Reentrantlock)与不可重入锁的区别
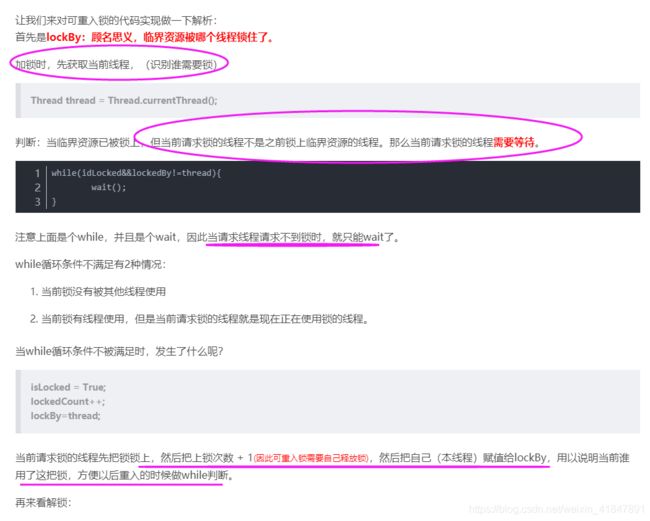
重入锁:
就如同在饭堂打饭,你在窗口排着队。排到你的时候,突然路人A让你顺带着打个饭吧,
然后你就打了两份饭,这时候你还没离开窗口,又有路人B让你打一份汤,于是你又额外打了一份汤。
即:可重入锁,也叫做递归锁,指的是同一线程 外层函数获得锁之后 ,内层递归函数仍然有获取该锁的代码
,但不受影响
顾名思义,就是支持重进入的锁,它表示该锁能够支持一个线程对资源的重复加锁。重进入是指任意线程在获取到锁之后能够再次获取该锁而不会被锁阻塞,该特性的实现需要解决以下两个问题。
1、线程再次获取锁。锁需要去识别获取锁的线程是否为当前占据锁的线程,如果是,则再次成功获取。
2、锁的最终释放。线程重复n次获取了锁,随后在第n次释放该锁后,其他线程能够获取到该锁。锁的最终释放要求锁对于获取进行计数自增,计数表示当前锁被重复获取的次数,而锁被释放时,计数自减,当计数等于0时表示锁已经成功释放。
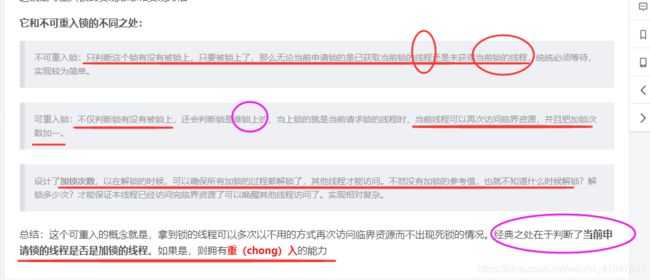
不可重入锁(自旋锁):
在另一个菜式比较好吃且热门的窗口,可不是这样的,在这里你在窗口,只能点一个菜(进入一次临界区)
,点完后,你想要再点别的菜,只能重新排一次队(虽然可以插队,当然我们可以引入服务员队伍管理机制:
private Lock windows = new ReentrantLock(true);,
指定该锁是公平的。
读写锁:
然而餐次的人流量一大,老板发现经常排起很长的队伍,厨师却都闲着没事干。
老板拍脑子一想,这样不行啊,所以稍微改进了一下点餐方式。所有人都可以扫二维码用H页进行点餐,
只要这个菜不是正在做(写锁),那么就可以随便点。即:
假设你的程序中涉及到对一些共享资源的读和写操作,且写操作没有读操作那么频繁。在没有写操作的时候,
两个线程同时读一个资源没有任何问题,
所以应该允许多个线程能在同时读取共享资源。但是如果有一个线程想去写这些共享资源,就不应该再有其它线程对该资源进行读或写




7 负载均衡的算法
IP哈希
url哈希
轮询
随机
权重
智能路由(比如有的服务器的响应时间短,就给他多分配一点任务,让它多做一些)
8 动态代理具体代码
import javase.LiuDeHua;
import javase.Person;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
/**
* @ClassName: LiuDeHuaProxy
* @Description: 这个代理类负责生成刘德华的代理人
* @author: 孤傲苍狼
* @date: 2014-9-14 下午9:50:02
*/
Person是接口 LiuDeHua是接口的实现类
public class LiuDeHuaProxy {
//设计一个类变量记住代理类要代理的目标对象
private Person ldh = new LiuDeHua();
/**
* 设计一个方法生成代理对象
*
* @return 某个对象的代理对象
* @Method: getProxy
* @Description: 这个方法返回刘德华的代理对象:Person person = LiuDeHuaProxy.getProxy();//得到一个代理对象
*/
public Person getProxy() {
//使用Proxy.newProxyInstance(ClassLoader loader, Class[] interfaces, InvocationHandler h)返回某个对象的代理对象
return (Person) Proxy.newProxyInstance(LiuDeHuaProxy.class
.getClassLoader(), ldh.getClass().getInterfaces(),
new InvocationHandler() {
/**
* InvocationHandler接口只定义了一个invoke方法,因此对于这样的接口,我们不用单独去定义一个类来实现该接口,
* 而是直接使用一个匿名内部类来实现该接口,new InvocationHandler() {}就是针对InvocationHandler接口的匿名实现类
35 */
/**
* 在invoke方法编码指定返回的代理对象干的工作
* proxy : 把代理对象自己传递进来
* method:把代理对象当前调用的方法传递进来
* args:把方法参数传递进来
*
* 当调用代理对象的person.sing("冰雨");或者 person.dance("江南style");方法时,
* 实际上执行的都是invoke方法里面的代码,
* 因此我们可以在invoke方法中使用method.getName()就可以知道当前调用的是代理对象的哪个方法
*/
@Override
public Object invoke(Object proxy, Method method,
Object[] args) throws Throwable {
//如果调用的是代理对象的sing方法
if (method.getName().equals("sing")) {
System.out.println("我是他的经纪人,要找他唱歌得先给十万块钱!!");
//已经给钱了,经纪人自己不会唱歌,就只能找刘德华去唱歌!9 数据库联合索引(a,b)
索引为(a,b,c)
如果只用了b ,或者只用了c,肯定是不成功的
如果用了(b,c)也是不成功的。
必须要用到a才能成功
(a,c),(a,b),(a,b,c)才能成功,必须要用到第一个字段a
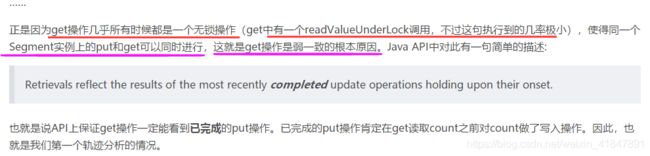
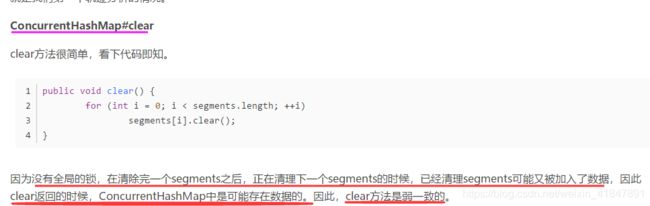
10 concourthashmap能代替hashtable吗?





11 谈谈事务中的redo-log和undo-log日志的作用

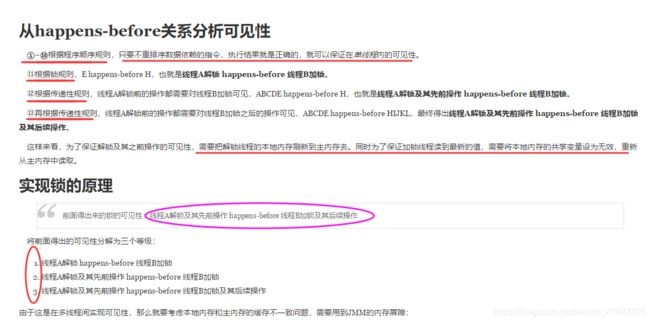
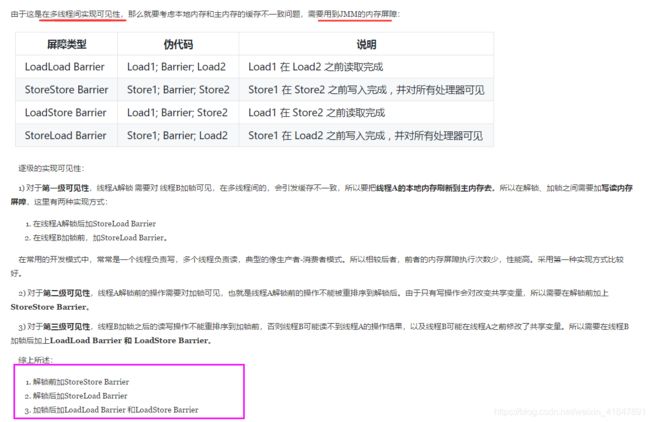
12 内存模型和内存屏障(volatile变量的内存可见性保证原理基于内存屏障)
内存模型是JVM用来区别线程栈和堆的内存方式,每个线程在运行的时候,
所操作的数据存储空间有两个,一个是主内存,一个是工作内存
主内存其实就是jvm中堆,工作内存就是线程的栈,
每次的数据操作,都是从主内存中把数据读到工作内存中,然后在工作内存中进行各种处理,
如果进行了修改,会把数据回写到主内存,然后其他线程又进行同样的操作,就这样数据在工作内存和主内存,
不断拷贝与刷新,在高并发下,就出现了数据不一致的问题,导致了多线程的不安全性;整个操作过程还牵涉到CPU,高速缓存等概念

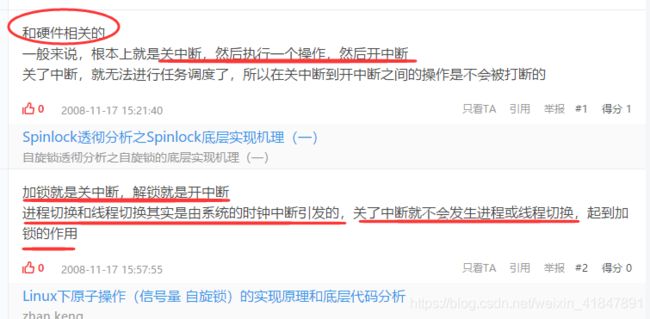
13 锁的底层-操作系统方面的实现
14 锁的实现


15 servlet与filter的区别
个人理解:
个人理解的servlet生命周期 :默认第一次访问时 创建servlet对象 调用intn()方法初始化 ,
每次访问都调用serves()服务 处理请求给与响应 ,关闭服务器时调用destroy()销毁servlet对象。
个人理解的filter生命周期当服务器启动时 创建filter对象 调用intn()方法初始化,
每次请求都调用dofilter()方法处理 关闭服务器时调用destroy()方法销毁对象
终上,个人理解 :servlet是处理请求给与响应的 filter主要是为servlet服务的 
16 Servlet2.0与3.0与4.0的区别?
servlet2规范:
servlet2.5特性介绍:支持annotations。
1.项目目录必须要有WEB-INF、web.xml等文件夹和文件。
2.在web.xml中配置servlet、filter、listener,以web.xml为java web项目的统一入口
servlet3规范:
1.项目中可以不需要WEB-INF、web.xml等文件夹和文件,在没有web.xml文件的情况下,
通过注解实现servlet、filter、listener的声明,例如:@WebServlet,@WebListener,@WebFilter,当使用注解时,容器自动进行扫描。
2.关于一些异步请求的改动:异步处理支持:servlet线程不再需要一直阻塞,直到业务处理完毕才再输出响应,
最后才结束该servlet线程,在接收到请求后,servlet可以将耗时的操作委派给另一个线程去完成,自己在不生成响应的情况下返回至容器。
servlet3之前,一个普通servlet的主要工作流程大致如下:首先,servlet接受到请求以后,可能需要对请求携带的数据进行一些预处理,
接着,调用业务接口的某些方法,以完成业务处理。最后,根据处理的结果提交响应,servlet线程结束。其中业务处理通常是非常耗时的,
主要体现在数据库操作以及跨网络调用等,在此过程中servlet线程一直处于阻塞状态,直到业务方法执行完毕。对于并发较大的应用,
这有可能造成性能瓶颈。servlet3针对这个问题提供了异步处理支持,Servlet请求将请求转交给另一个线程去执行业务逻辑,
线程本身返回至容器,此时servlet还没有生成响应数据。异步线程处理完业务以后,可以直接生成响应结果或者转交给其它servlet处理。
如此一来,servlet不再一直处于阻塞状态以等待业务逻辑的处理,而是启动异步线程后可以立即返回。
Servlet 3.0 还为异步处理提供了一个监听器,使用 AsyncListener 接口表示。它可以监控如下四种事件:
异步线程开始时,调用 AsyncListener 的 onStartAsync(AsyncEvent event) 方法;
异步线程出错时,调用 AsyncListener 的 onError(AsyncEvent event) 方法;
异步线程执行超时,则调用 AsyncListener 的 onTimeout(AsyncEvent event) 方法;
异步执行完毕时,调用 AsyncListener 的 onComplete(AsyncEvent event) 方法;
Servlet 4.0规范:
Servlet 4.0 的主要新功能为服务器推送和全新 API,该API可在运行时发现servlet的URL映射。
服务器推送是最直观的 HTTP/2 强化功能,通过 PushBuilder 接口在 servlet 中公开。服务器推送功能
还在 JavaServer Faces API 中实现,并在 RenderResponsePhase 生命周期内调用,以便 JSF 页面可以利用其增强性能。
Servlet API已经很好地支持HTTP / 2优化,并允许框架利用服务器推送。
服务器推送是HTTP/2中出现在servlet API中的许多改进中最明显的部分。HTTP/2中的所有新功能(包括服务器推送)
都旨在提高Web浏览体验的感知性能。
一个请求和多个响应Servlet API中的一个变化是在HTTP 1中我们有一个请求和一个响应。在HTTP/2中,这不再是唯一。
可以有一个请求,服务器可能决定推送多个资源,然后最终以最初请求的页面进行响应。您同时有一个请求和多个响应,
这对Servlet API来说是一个挑战。改进的是服务器可以知道,无论何时浏览器如果请求index.html页面,它同时就意味着请求标识图像,
样式表和菜单JavaScript等。由于服务器知道这一点,他们可以优先开始发送这些资源处理index.html。
Servlet 4.0 映射发现接口 HttpServletMapping 使框架能够获取有关激活给定 servlet 请求的 URL 信息。这可能对框架尤为有用,
这些框架需要这一信息来运行内部工作。
17 java四种元注解
元注解:注解的注解,即java为注解开发特准备的注解。
在java中有四种元注解:
1.@Target
表示该注解用于什么地方(类,接口,方法,参数,构造器等)
2.@Retention
表示该注解可以保存的范围(源代码,class文件,运行期)
3.@Documented
即拥有这个注解的元素可以被javadoc此类的工具文档化。它代表着此注解会被javadoc工具提取成文档。
在doc文档中的内容会因为此注解的信息内容不同而不同。相当与@return,@param 等。
4.@Inherited
允许子类继承父类中的注解。即拥有此注解的元素其子类可以继承父类的注解。
18 mysql默认隔离级别是可重复读,修改count字段+1,多个线程会有问题吗?
REPEATABLE_READ 可重复读 事务是多次读取,得到的相同的值。即该事务执行期间,不允许其他事务对该事务数据进行操作,保证该事物中多次对数据的查询结果一致。就是你多次查询的这个事务包含多条数据,为了保证读取的一致性,可重复读(REPEATABLE_READ)将使用的数据锁起来不让别人用。所以count字段+1的时候就会把该字段锁起来,操作完成才会释放,所以不会有问题
19 Aop里面cglib能代替动态代理吗?
