hadoop MapReduce计算总销售量,每个月的销售量,每个怕品牌的总销售量
今天来练习一下mapreduce的入门小知识点
准备数据如下截图

有IP xiaomi 华为三个手机品牌,在2019年中每个月每天都有销量
1 求三个品牌一年一共销售多少部手机
package com.sheng.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//计算
//maper计算框架,输出:
class Mapper1 extends Mapper{
@Override
protected void map(LongWritable key,Text values,Context context) throws IOException, InterruptedException {
//得到每一行的值
String lines =values.toString();
//对每一行的字符串按逗号来分
String[] s= values.toString().split(",");
//输出:key值和value值
context.write(new Text("总销售量"), new IntWritable(Integer.parseInt(s[1])));
}
}
//Reducer输出到Hadoop中:他的输入是mapper的输出
class WcReduce1 extends Reducer {
@Override
protected void reduce(Text key,Iterablevalues,Context context)throws IOException, InterruptedException{
int sum=0;
for (IntWritable val:values) {
sum+=val.get();
}
context.write(key,new IntWritable(sum));
}
}
public class Home1 {
public static void main(String[] args)throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// conf.set("HADOOP_USER_NAME","ambow");
// Job对像
Job job = Job.getInstance(conf);
// 注册Jar驱动类
job.setJarByClass(Home1.class);
// 注册Mapper驱动类
job.setMapperClass(Mapper1.class);
//注册Reducer驱动类
job.setReducerClass(WcReduce1.class);
// 设置MapOutPut输出的的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终输出的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入输出路径
// org.apache.hadoop.mapred.FileInputFormat 老版本
// org.apache.hadoop.mapreduce.lib.input.FileInputFormat 新版本
FileInputFormat.setInputPaths(job, new Path("/user/test/data.csv"));
FileOutputFormat.setOutputPath(job, new Path("/user/test/data1.csv"));
// FileInputFormat.setInputPaths(job, new Path(args[0]));
// FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置reduce任务数为0 分区多少个???
// job.setNumReduceTasks(0);
// 提交作业
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
在Hadoop中查看结果如下:

2 计算这三个品牌手机这一年分别销售多少部手机(分区计算)
package com.sheng.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//计算三个手机这一年的总销量
class Mapper2 extends Mapper{
@Override
protected void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException {
String lines=value.toString();
String[] s=lines.split(",");
//key值是手机品牌名字,vaule值是销售量
context.write(new Text(s[0]),new IntWritable(Integer.parseInt(s[1])));
}
}
//Reduce
class Reduce1 extends Reducer{
@Override
protected void reduce(Text key,Iterablevalue,Context context) throws IOException,InterruptedException {
int sum=0;
for(IntWritable val:value) {
sum+=val.get();
}
context.write(key, new IntWritable(sum));
}
}
//自定义分区
//注意:分区字段要和value字段相同
class Mypartitioner extends Partitioner{
@Override
public int getPartition(Text key, IntWritable value, int numPrtitons) {
if (key.toString().equals("xiaomi")) {
return 0;
}
if (key.toString().equals("华为")) {
return 1;
}
if (key.toString().equals("IP"))
return 2;
return 3;
}
}
public class Home2 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//
Configuration conf = new Configuration();
// conf.set("HADOOP_USER_NAME","ambow");
// Job对像
Job job = Job.getInstance(conf);
// 注册Jar驱动类
job.setJarByClass(Home2.class);
// 注册Mapper驱动类
job.setMapperClass(Mapper2.class);
//注册Reducer驱动类
job.setReducerClass(Reduce1.class);
// 设置MapOutPut输出的的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终输出的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入输出路径
// org.apache.hadoop.mapred.FileInputFormat 老版本
// org.apache.hadoop.mapreduce.lib.input.FileInputFormat 新版本
FileInputFormat.setInputPaths(job, new Path("/user/test/data.csv"));
FileOutputFormat.setOutputPath(job, new Path("/user/test/data5.csv"));
// FileInputFormat.setInputPaths(job, new Path(args[0]));
// FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置reduce任务数为0 分区多少个???
job.setPartitionerClass(Mypartitioner.class);
job.setNumReduceTasks(3);
// 提交作业
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
计算结果:

3 计算每个品牌手机的每个月的销售总量
package com.sheng.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/*
* 统计每个牌子的每个月的销售总量
*/
class WcMapper2 extends Mapper {
/*
* KeyIn:LongWritable 行的偏移量 ValueIn:Text 这一行的值 TextInputformat
*
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 得到每一行的值,反序化为字符串
String lines = value.toString();
// 对每一行的字符串按空格来拆分
String[] s = value.toString().split(",");
String str1=s[2];
String[] s1 = str1.toString().split("月");
String str3=s1[0];
String str2=str3.substring(5);
// 对每个单词写入Hadoop中 写入的数据必须是Hadoop的序列化
context.write(new Text(str2+"月"+s[0]), new IntWritable(Integer.parseInt(s[1])));
// hello:1 word:1 aaaa:1 空格 :1 空格 :1 空格 :1
}
}
class WcReduce2 extends Reducer {
// reduce(单词key, 指定的单词mapper统计的List, Context context)
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
class MyPartitioner1 extends Partitioner {
//转发给4个不同的reducer
//转发给4个不同的reducer
@Override
public int getPartition(Text key, IntWritable value, int numPartitons) {
if (key.toString().equals("xiaomi"))
return 0;
if (key.toString().equals("huawei"))
return 1;
if (key.toString().equals("iphone7"))
return 2;
return 3;
}
}
public class Home3 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//
Configuration conf = new Configuration();
// conf.set("HADOOP_USER_NAME","ambow");
// Job对像
Job job = Job.getInstance(conf);
// 注册Jar驱动类
job.setJarByClass(Home3.class);
// 注册Mapper驱动类
job.setMapperClass(WcMapper2.class);
//注册Reducer驱动类
job.setReducerClass(WcReduce2.class);
// 设置MapOutPut输出的的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终输出的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入输出路径
// org.apache.hadoop.mapred.FileInputFormat 老版本
// org.apache.hadoop.mapreduce.lib.input.FileInputFormat 新版本
FileInputFormat.setInputPaths(job, new Path("/user/test/data.csv"));
FileOutputFormat.setOutputPath(job, new Path("/user/test/data6.csv"));
// FileInputFormat.setInputPaths(job, new Path(args[0]));
// FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置reduce任务数为0 分区多少个???
job.setPartitionerClass(MyPartitioner1.class);
//job.setNumReduceTasks(3);
// 提交作业
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
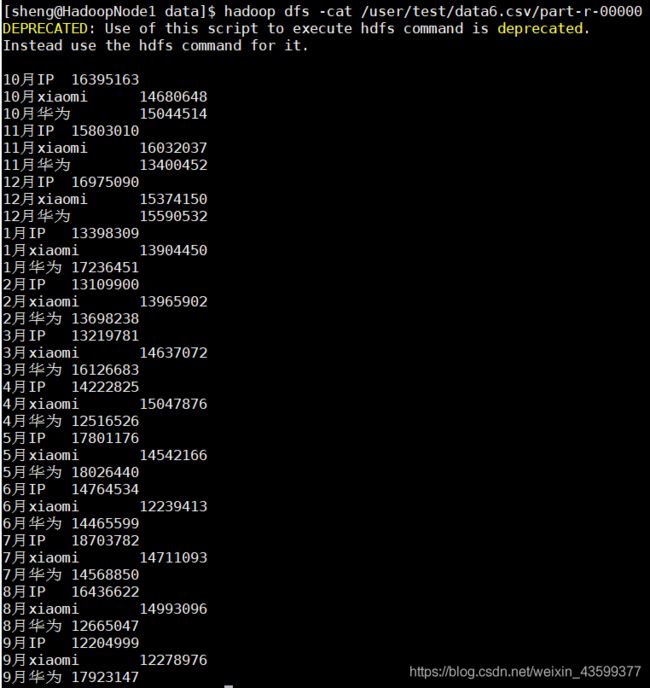
计算结果: